Examining Soft Machines' Architecture: An Element of VISC to Improving IPC
by Ian Cutress on February 12, 2016 8:00 AM EST- Posted in
- CPUs
- Arm
- x86
- Architecture
- Soft Machines
- IPC
The VISC Instruction Set and Global Front End
Common instruction set architectures (ISAs) such as x86, ARMv8, Power, SPARC and other more esoteric ones rely on system code converting into predefined instructions that each design can handle. VISC comes with its own ISA as well, separate from the others, which VISC cores and virtual cores use. When using native VISC code, the global front end will split the instructions into smaller ‘virtual hardware threadlets’ which are then dispatched to separate virtual cores. These virtual cores can then issue them to the available resources on any of the physical cores and keep track of where the data goes. Multiple virtual cores can push threadlets into the reorder buffer of a single physical core, which can split partial instructions and data from multiple threadlets through the execution ports at the same time. We were told that each ‘virtual core’ keeps track of the position of the relative output.
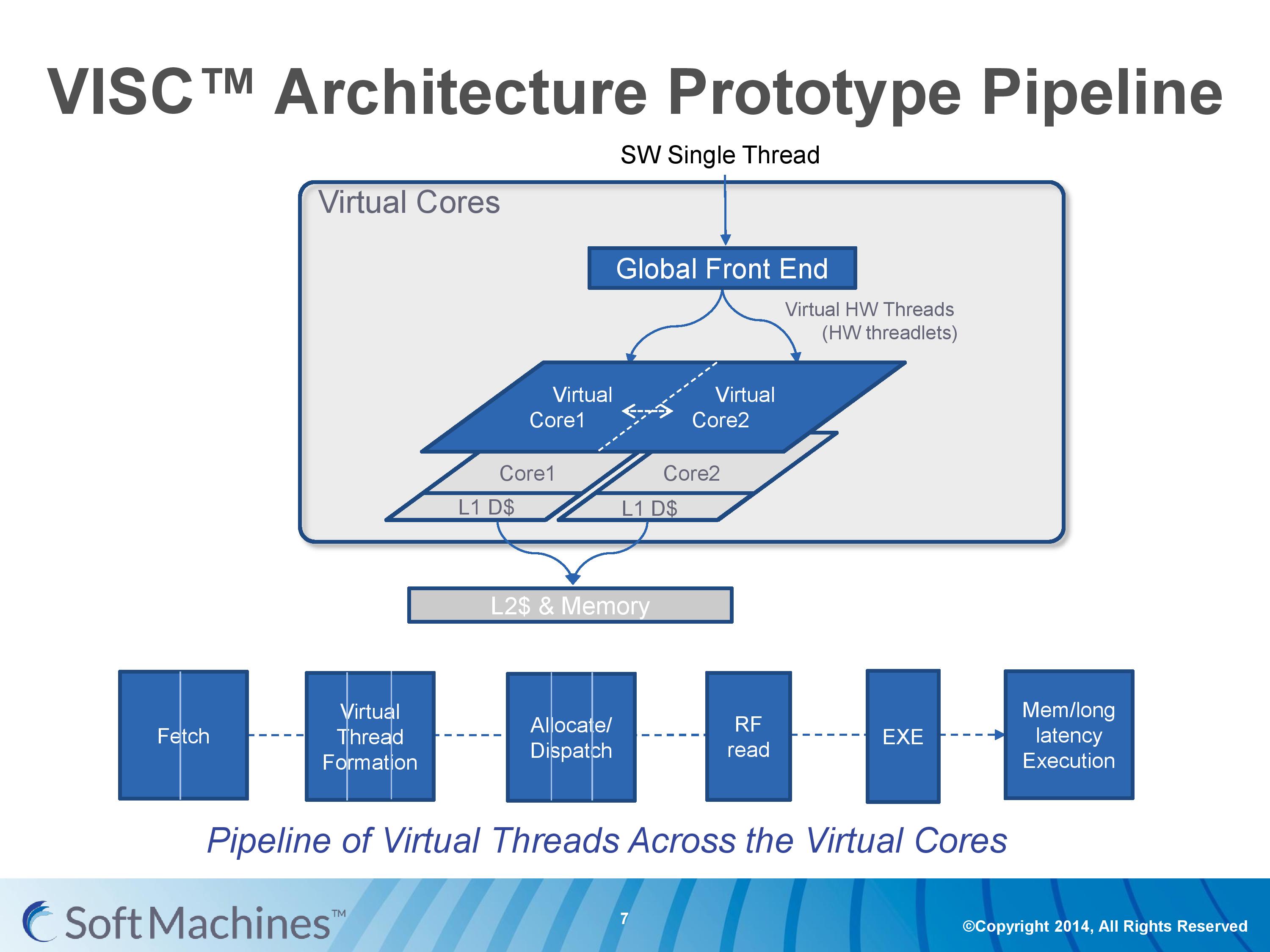
The true kicker (and so much of what sets VISC apart) is that when multiple virtual cores are in flight at one time, the core design allows the virtual core allocation of resources to be dynamic on a near-single cycle latency level (we were told from 1-4 cycles depending on the change in allocation). Thus if two virtual cores are competing for resources, there are appropriate algorithms in place to determine what resources are allocated where.
One big area of focus in optimizing processor designs for single-thread performance is speculation – being able to deal with branches in code and/or prefetch relevant data from memory when needed. Typically when speculation occurs, as the data for a single thread is contained within a core, it is easy enough to deal with code paths that rely on previous data or end up with bad speculation.
In the virtual core scenario however this becomes trickier. VISC tackles this in two ways – firstly, the threadlet generation is designed to minimize cross-core communication because this adds latency and reduces performance. Second, each core can communicate through either the register file or the L1 data caches. The register files have a single cycle latency for data but can only transmit tens of values, whereas the L1 cache has a 4-cycle latency but can transmit thousands of values.
Typically communicating through a register file is seen as a risky maneuver and difficult to control, especially when you have multiple physical cores and each core needs each other core to be able to place/take data into the right registers. Soft Machines told us that a large part of their design work has been in this area of speculation and data transfer. Specifically on speculation and branch prediction, we postulated that they were over ten years behind Intel in this, and the response we got was in a similar vein, stating that using Intel’s branch prediction methods could offer at least 20-30% better performance with branching code. However, we were told that the VISC design is quicker to recover in the event of a failed branch, needing only a few cycles.
The Pipeline
The first VISC core available for license is Shasta, a dual core part that enables up to two virtual cores or threads (2C/2VC), and we were given a base overview of the pipeline.
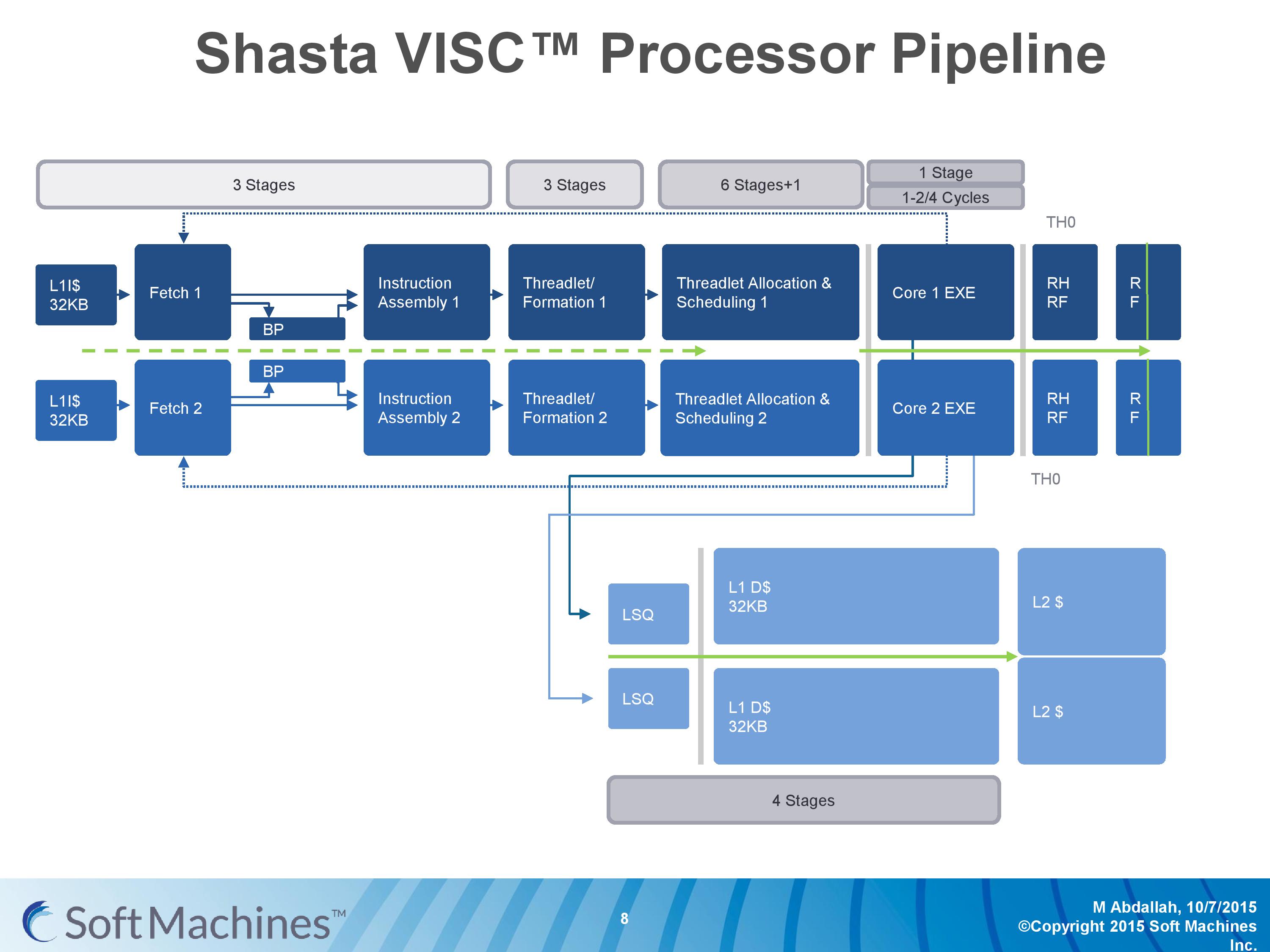
Normally we would see a pipeline of one core but this is a pipeline of both cores of Shasta. This pipeline, compared to the original VISC prototype, is also deeper. The pipeline looks relatively normal to others to start, where the thread either takes an instruction or issues a fetch for data into the instruction assembly. Making the VISC instructions and data into threadlets takes another three stages, but the allocation and scheduling takes six (plus one). On that subject, Soft Machines mentioned that keeping track of data across multiple cores per virtual core is tricky, as well as dealing with reorder buffers and parallel instruction management, that’s why there are a large amount of stages here. The plus one goes back to variable physical core allocation methodology, ensuring that if there are two threads active that the heavier one will get the most resources. The threadlets are then executed on the ports of each core, with a possible 1-4 cycle delay if data needs to be transferred across the core boundaries via registers or L1 cache.
With the variable allocation of fractions of a core to a virtual core, VISC is designed for this situation:
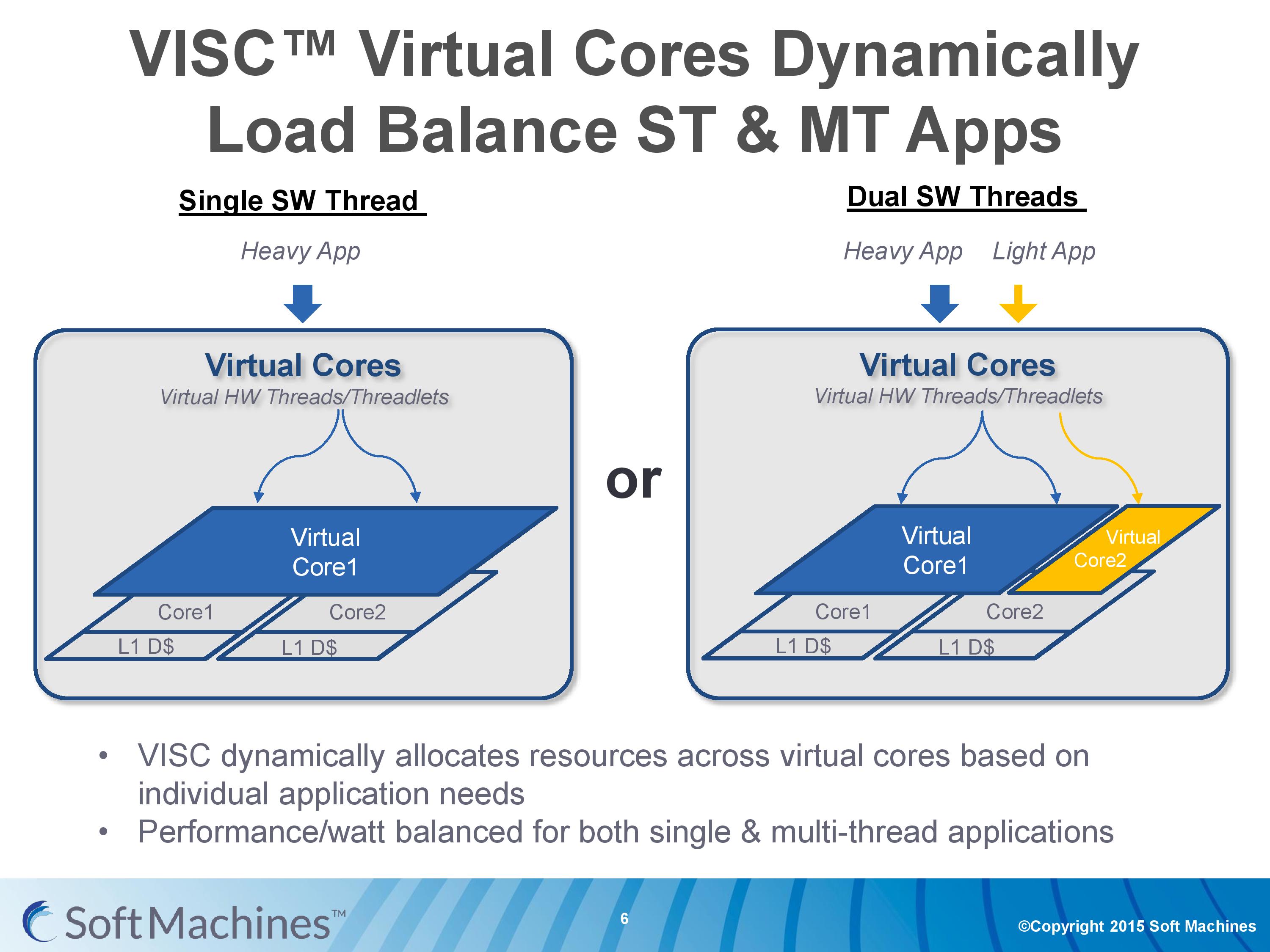
If one heaver thread needs more resources, it can take them from idle ports on a second core (or third, or fourth). The virtual cores can be configured at the software stage as well to limit their use (e.g. keep a VC to half a physical core), and this can be configured at runtime at the expense of 10-12 cycles. There is a quality of service implementation as well, so if a virtual core takes a high priority thread, it will have access to more resources by default.








97 Comments
View All Comments
KAlmquist - Sunday, February 14, 2016 - link
If I understand the article correctly, the difference between VISC and SMT is that in SMT there is a single scheduler which manages all of the execution units. VISC implements a two stage scheduling algorithm. In the first stage, an operation is assigned to a core. In the second stage, the scheduler for that core assigns the operation to an execution unit.The downside of SMT is that the amount of silicon required to implement the scheduler grows faster than the number of execution units. So as you add more threads and more execution units, it becomes harder and harder to keep the cost of the scheduler to a reasonable level.
In the second stage of VISC, you have multiple schedulers, each feeding a small number of execution units, which keeps these schedulers simple. In the first stage, the schedulers require at least some awareness of all the execution units. For example, if you have an integer multiply instruction, you want to send it to a core that doesn't have other integer multiply operations outstanding rather than just chosing the core with the smallest total number of outstanding operations. What may keep the first stage scheduling reasonably simple is that it doesn't appear to do any instruction reordering (though it does have to do the bookwork to keep track of which instructions have been retired).
In short, VISC appears to be intended to scale better than SMT as you add more threads and execution units.
What is strange, then, is that Soft Machines isn't talking about building an 8 thread device like IBM's POWER8. Instead, they have a two and four thread designs, and are mostly talking about the former. A two thread VISC design makes sense only if you believe that the SMT approach is already hitting its limits with two threads.
My sense is that VISC is not going to be a game changer, but Soft Machines could be successful if ARM Holdings screws up. If ARM has has a major screw up technologically (like AMD did with Bulldozer), Soft Machines could end up with a superior product. Conversely, if ARM screws up on customer relations, all Soft Machines would need is something close to technological parity with ARM to win customers.
Shadowmaster625 - Monday, February 15, 2016 - link
When Intel purchased Altera I immediately began to visualize all sorts of great potential breakthroughs in single threaded IPC. I imagine that within 5 years, we will have at least a modest number of FPGA cells integrated within Intel CPU cores. These cells will be programmed on-the-fly with application specific DSPs that will be capable of completing commonly used combinations of instructions MUCH faster than the general x86 instruction set would allow. I expect this to be the singularly largest breakthrough in computing of the last 20 years. Within 10 years, I expect the CPU itself to create its own DSP code on the fly as it profiles its own instruction loading in real time. The potential here is utterly massive. Think about what ASICs have done for bitcoin mining... Soon they will be able to do that for javascript!FunBunny2 - Monday, February 15, 2016 - link
-- capable of completing commonly used combinations of instructions MUCH faster than the general x86 instruction set would allow. I expect this to be the singularly largest breakthrough in computing of the last 20 years.that's what the real cpu/RISC core/micro-architecture has done for decades. twerked continually.
-- I imagine that within 5 years, we will have at least a modest number of FPGA cells integrated within Intel CPU cores.
done: http://www.extremetech.com/extreme/184828-intel-un...
"This new Xeon+FPGA chip will fit in the standard E5 LGA2011 socket, but the integrated FPGA will allow each chip to be customized to specific workloads."
Shadowmaster625 - Monday, February 15, 2016 - link
That's not what I mean. That is of course a good start, but what I'm talking about is programmable logic linked tightly to the actual execution units of the CPU core. Smaller blocks, probably only a square millimeter or perhaps even less. But many of them. Just like Skylake has 6 execution units. One of these programmable blocks would be only about the same size as one of those existing execution units. They would have direct access to the prefetcher and scheduler and instruction/data caches. They would be power gated.dustwalker13 - Saturday, February 20, 2016 - link
yes it looks good on paper ... but up to now that is all that it does.silicon existing at HQ is so much smoke and mirrors until some independant source has an actual go at it and publishes results.
it looks promising, but so did a million other things that ended up as just another failiur or worse scam.
i will keep an eye on this one but for now there simply is nothing to see than mirror images produced by a lot of hot air.
mikato - Saturday, February 20, 2016 - link
So why did they come out of stealth mode?TruePath - Saturday, April 16, 2016 - link
I've been curious for a long time why more wasn't done to use parallel resouces to extract instruction level parrelism.However, what puzzles me is why do so much of the work on the fly at run time. Sure, one needs to be able to respond to dynamic performance information like failed speculation but it seems like there is substantial overhead in translating the host ISA into native instructions and (I assume) encoding information into the native instructions about resource needs and dependencies.
Even before a program is run knowledge of the exact processor would enable software to translate the ISA (targeting the exact chip), hint at resources needs and perform a degree of instruction reordering (over a larger window than in hardware).
So why not push as much of this into the software as possible. One can even cache the results of software ISA translation. Is it just a desire to be totally hardware compatible?