3DLabs' P10 Visual Processing Unit - When a CPU & GPU Collide
by Anand Lal Shimpi on May 3, 2002 7:30 AM EST- Posted in
- GPUs
16 FP Vertex Processors
In stage 2 we talked about the transformation and lighting of vertices and the role vertex shaders play in today's programmable GPUs. By far the most powerful desktop GPU when it comes to vertex shaders is NVIDIA's GeForce4 which has two vertex shaders. The 3DLabs P10 on the other hand has 16 32-bit floating-point geometry processors that handle vertex processing, does this mean that the P10 has 8 times the vertex throughput of the GeForce4? Of course not, let's start off by making this an apples to apples comparison.
Each one of NVIDIA's vertex shader units operates on 4 element vector data (vect4) which is perfect for the type of work these units have to perform. Unfortunately if you send anything other than a vect4 operand to the vertex processor you'll lose efficiency. For example, these units can only handle one scalar at a time; if you recall from our explanation of the 3D pipeline, the transformation process makes heavy use of matrix math and the generation of scalar values occurs quite frequently here. Even with dual vertex shader units, the loss of efficiency when dealing with anything other than a vect4 operation is significant. For example, a vect4 operation can be processed in a single clock cycle through NVIDIA's vertex shader unit but it takes the same amount of time to process a single scalar operation. ATI's vertex shaders are setup in the same way and if you were to convert ATI/NVIDIA vertex shaders to what 3DLabs is referring to when they use the term "Vertex Processor" you could claim that each one of their units has 4 vertex processors.
The P10 uses a different approach; instead of using very powerful units, 3DLabs went to a more granular setup where they have a total of 16 32-bit scalar vertex processors (VPs). Each one of these processors can crank out a scalar operation in one clock cycle, but they take four clock cycles to complete a vect4 operation. The reason the P10 has the potential to be faster at all types of vertex operations is because there are so many (16) of these VPs in parallel.
If you are comparing theoretical vertex throughput between the P10 and the GeForce4's dual vertex shaders you'd end up with a little more than a 2x advantage in favor of the P10. The reason for the potential advantage being a more than 2x is because of the gain in efficiency when dealing with scalar operations that can be completed in one clock cycle through any of the 16 VPs in parallel.
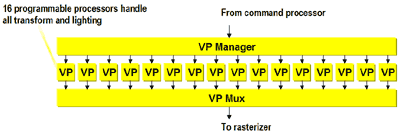
Software only sees one virtual VP and interacts with the VP manager which then
takes on the role of managing all 16 VPs.
From a software standpoint, the massively parallel array of VPs goes completely unnoticed. The developer can treat the array as a single vertex processor, a VP manager properly assigns and distributes the operations among the 16 parallel VPs. In the end a multiplexer chooses from the VP outputs and sends the data to the next stage of the pipeline.
This array of 16 VPs is the P10's version of NVIDIA's vertex shaders and they do offer full support for all current DX8 vertex shaders. 3DLabs believes that they will be able to claim full support for the Vertex Shader 2.0 specification in DirectX 9 but given that DX9 isn't out they cannot officially claim support yet.








0 Comments
View All Comments