The IBM POWER8 Review: Challenging the Intel Xeon
by Johan De Gelas on November 6, 2015 8:00 AM EST- Posted in
- IT Computing
- CPUs
- Enterprise
- Enterprise CPUs
- IBM
- POWER
- POWER8
Floating Point: C-ray
Shifting over from integer to floating point benchmarks we have C-ray. C-ray is an extremely simple ray-tracer which is not representative of any real world raytracing application. In fact, it is essentially a floating point benchmark that runs out the L1-cache. Luckily it is not as synthetic and meaningless as Whetstone, as you can actually use the software to do simple raytracing. That is not the kind of benchmark we like to use for the evaluations of server CPUs, but since our first efforts to port some of our favorite applications to OpenPOWER failed, we settled for something easier. We knew we would have the POWER8 system only for a few weeks, so we had to play it safe.
First we compiled the C-ray multi-threaded version with -O3 -ffast-math. To understand the CPU performance better, we limited C-ray with taskset to one or two threads (CPU 0 and 18) on the Haswell-based Xeon and one to eight threads on the POWER8. We also kept the output resolution at 768x432 to keep the render times in check. The "sphfract" file was used as input.
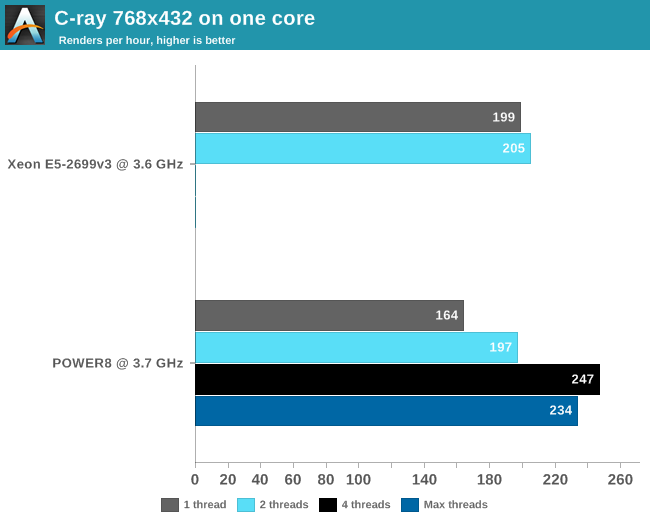
Real floating point intensive applications tend to put the memory subsystem under pressure, and running a second thread makes it only worse. So we are used to seeing that many HPC applications performe worse with multi-threading on. But since C-ray runs mostly out of the L1-cache, we get different behavior. Still, 8 threads of floating action seem to be too much: the POWER8 delivers the best FP performance at 4 threads. At this point, the POWER8 core is able to deliver 20% higher floating point performance than the Haswell Xeon.
Next we used all 160 (20 x 8 threads SMT) or 72 (36 x 2 threads SMT) threads and increased the resolution to 3840x2160.
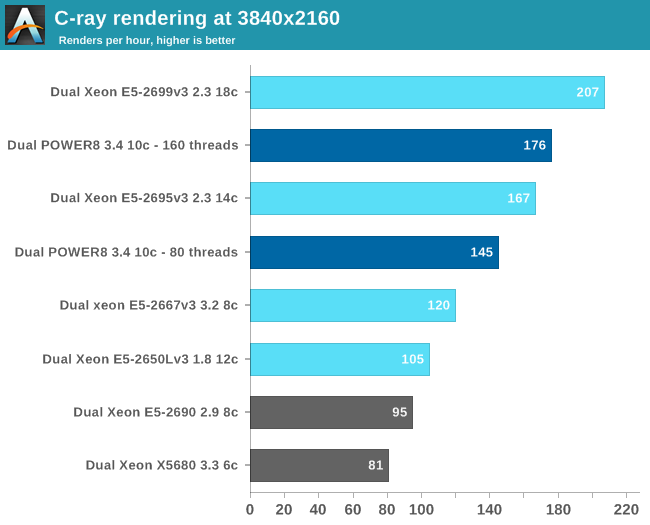
With a core count that is 80% higher, there is nothing stopping the Xeon E5-2699 v3 from taking the top spot. Still, the POWER8 delivers solid performance and outperforms the slower Xeon E5-2695 v3 by 5%. Although the real world relevance of this benchmark is small, we now have an idea of how good the "basic FP" performance is. Otherwise in real world applications, the use of AVX-2/VSX and the available bandwidth will play a role.








146 Comments
View All Comments
Der2 - Friday, November 6, 2015 - link
Life's good when you got power.BlueBlazer - Friday, November 6, 2015 - link
Aye, the power bills will skyrocket.Brutalizer - Friday, November 13, 2015 - link
It is confusing that sometimes you are benchmarking cores, and sometimes cpus. The question here is "which is the fastest cpu, x86 or POWER8" - and then you should bench cpu vs cpu. Not core vs core. If a core is faster than another core says nothing, you also need to know how many cores there are. Maybe one cpu has 2 cores, and the other has 1.000 cores. So when you tell which core is fastest, you give incomplete information so I still have to check up how many cores and then I can conclude which cpu is fastest. Or can I? There are scaling issues, just because one benchmark runs well on one core, does not mean it runs equally well when run on 18 cores. This means I can not extrapolate from one core to the entire cpu. So I still am not sure which cpu is fastest as you give me information about core performance. Next time, if you want to talk about which cpu is faster, please benchmark the entire cpu. Not core, as you are not talking about which core is faster.Here are 20+ world records by SPARC M7 cpu. It is typically 2-3x faster than POWER8 and Intel Xeon, all the way up to >10x faster. For instance, M7 achieves 87% higher saps than E5-2699v3.
https://blogs.oracle.com/BestPerf/
The big difference between POWER and SPARC vs x86, is scalability and RAS. When I say scalability, I talk about scale-up business Enterprise servers with as many as 16- or even 32-sockets, running business software such as SAP or big databases, that require one large single server. SGI UV2000 that scales to 10.000s of cores can only run scale-out HPC number crunching workloads, in effect, it is a cluster. There are no customers that have ever run SGI UV2000 using enterprise business workloads, such as SAP. There are no SAP benchmarks nor database benchmarks on SGI UV2000, because they can only be used as clusters. The UV2000 are exclusively used for number crunching HPC workloads, according to SGI. If you dont agree, I invite you to post SAP benchmarks with SGI UV2000. You wont find any. The thing is, you can not use a small cluster with 10.000 cores and replace a big 16- or 32-socket Unix server running SAP. Scale-out clusters can not run SAP, only scale-up servers can. There does not exist any scale-out clustered SAP benchmarks. All the highest SAP benchmarks are done by single large scale-up servers having 16- or 32-sockets. There are no 1.000-socket clustered servers on the SAP benchmark list.
x86 is low end, and have for decades stopped at maximum 8-sockets (when we talk about scale-up business servers), and just recently we see 16- and 32- sockets scale-up business x86 servers on the market (HP Kraken, and SGI UV300H) but they are brand new, so performance is quite bad. It takes a couple of generations until SGI and HP have learned and refined so they can ramp up performance for scale-up servers. Also, Windows and Linux has only scaled to 8-sockets and not above, so they need a major rewrite to be able to handle 16-sockets and a few TB of RAM. AIX and Solaris has scaled to 32-sockets and above for decades, were recently rewritten to handle 10s of TB of RAM. There is no way Windows and Linux can handle that much RAM efficiently as they have only scaled to 8-sockets until now. Unix servers scale way beyond 8-sockets, and perform very well doing so. x86 does not.
The other big difference apart from scalability is RAS. For instance, for SPARC and POWER you can hot swap everything, motherboards, cpu, RAM, etc. Just like Mainframes. x86 can not. Some SPARC cpus can replay instructions if something went wrong. x86 can not.
For x86 you typically use scale-out clusters: many cheap 1-2 socket small x86 servers in a huge cluster just like Google or Facebook. When they crash, you just swap them out for another cheap server. For Unix you typically use them as a single scale-up server with 16- or 32-sockets or even 64-sockets (Fujitsu M10-4S) running business software such as SAP, they have the RAS so they do not crash.
zeeBomb - Friday, November 6, 2015 - link
New author? Niiiice!Ryan Smith - Friday, November 6, 2015 - link
Ouch! Poor Johan.=(Johan is in fact the longest-serving AT editor. He's been here almost 11 years, just a bit longer than I have.
hans_ober - Friday, November 6, 2015 - link
@Johan you need to post this stuff more often, people are forgetting you :)JohanAnandtech - Friday, November 6, 2015 - link
well he started with "niiiiice". Could have been much worse. Hi zeeBomb, I am Johan, 43 years old and already 17 years active as a hardware editor. ;-)JanSolo242 - Friday, November 6, 2015 - link
Reading Johan reminds me of the days of AcesHardware.com.joegee - Friday, November 6, 2015 - link
The good old days! I remember so many of the great discussions/arguments we had. We had an Intel guy, an AMD guy, and Charlie Demerjian. Johan was there. Mike Magee would stop in. So would Chris Tom, and Kyle Bennett. It was an awesome collection of people, and the discussions were FULL of real, technical points. I always feel grateful when I think back to Ace's. It was quite a place.JohanAnandtech - Saturday, November 7, 2015 - link
And many more: Paul Demone, Paul Hsieh (K7-architect), Gabriele svelto ... Great to see that people remember. :-)