Matrox's Comeback Kid - The Parhelia-512
by Anand Lal Shimpi on May 14, 2002 9:00 AM EST- Posted in
- GPUs
The Parhelia Pipeline

We already explained where the Parhelia part of the name comes from but what about the '512' suffix? Luckily this is a bit easier to explain; as you'll soon see, there are a number of situations where the number 512 appears when looking at the architecture of the Parhelia. Matrox's decision to name the GPU the Parhelia-512 is akin to NVIDIA calling the NV10 the GeForce256.
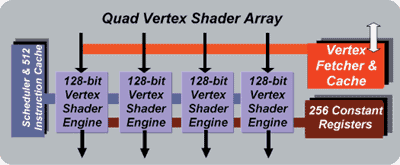
At the very start of the Parhelia-512's pipeline (after the AGP interface) you have the vertex processors. Matrox has outfitted the Parhelia-512 with four vertex shader units that they refer to as "128-bit Vertex Shader Engines." If you multiply 128 by the 4 units you'll get that magical 512 number. The 128-bits comes from the fact that each one of these units can work on four 32-bit floating point numbers at the same time provided that they are packaged as a 4-operand vector. Each one of these vertex shader engines is comparable to each one of the two vertex units engines in the GeForce4 or four of the vertex processors in the 3DLabs P10. This means that right off the bat, the Parhelia-512 has twice the vertex throughput of the GeForce4 at equivalent clock speeds.
The Parhelia's vertex shader units are fully DX8.1 compliant and offer a bit more flexibility than even DX8.1 requires which is why you will see them referred to as Vertex Shader 2.0 compliant (DX9). This flexibility is useful however from a developer's perspective, unless the entire pipeline (vertex and pixel portions) is DX9 compatible then there is not much added value. Remember that the entire point of the vertex shaders is to prepare the vertices for operations to be performed on them by the pixel shaders, if the pixel shaders aren't as flexible/programmable or if they are not also floating-point units then you can improve the vertex shaders all you'd like and you'd still be bottlenecked by the pixel shaders.
After the vertices come out of the vertex shader engines they are fed to Matrox's primitive engine that begins assembling the triangles and removing vertices that don't fit within the boundaries of the screen. This is where you'd normally find a fairly powerful occlusion culling logic to remove data that won't be seen by the user before actually rendering the pixels. For example, the Radeon 8500's HyperZ and the GeForce4's Visibility Subsystem engines come into play here. However, in a tradeoff that Matrox made to offer some of the other features of the Parhelia-512 the GPU does not have a system nearly as elaborate as any of their competitors.
The Parhelia-512 does have "Fast Z-Clear" logic that is used to quickly set the Z-buffer to an array of all zeros much like competing ATI and NVIDIA GPUs. Unfortunately the GPU does not have any comparable occlusion culling technologies or none that are nearly as advanced as ATI's Hierarchical Z or Z-Compression. With the amount of memory bandwidth that the Parhelia-512 can offer the lack of any elegant memory management technology isn't too big of a problem until you start getting into more complex games. If you are applying an extensive pixel shader program (50 - 100 instructions) to pixels and spending valuable clock cycles in doing so, if the pixel ends up never being displayed then a significant portion of your execution resources have been wasted. This will become much more common as games that take advantage of DX8 pixel shader functions become available and can become an Achilles' heel of the Parhelia architecture.








0 Comments
View All Comments