A3Cube develop Extreme Parallel Storage Fabric, 7x Infiniband
by Ian Cutress on February 26, 2014 4:25 AM EST- Posted in
- Enterprise
- Networking
- Datacenter
- A3Cube

News from EETimes points towards a startup that claims to offer an extreme performance advantage over Infiniband. A3Cube Inc. has developed a variation of the PCIe Express on a Network Interface Card to offer lower latency. The company is promoting their Ronniee Express technology via a PCIe 2.0 driven FPGA to offer sub-microsecond latency across a 128 server cluster.
In the Sockperf benchmark, numbers from A3Cube put performance at around 7x that of Infiniband and PCIe 3.0 x8, and thus claim that the approach beats the top alternatives. The PCIe support of the device at the physical layer enables quality-of-service features, and A3Cube claim the fabric enables a cluster of 10000 nodes to be represented in a single image without congestion.
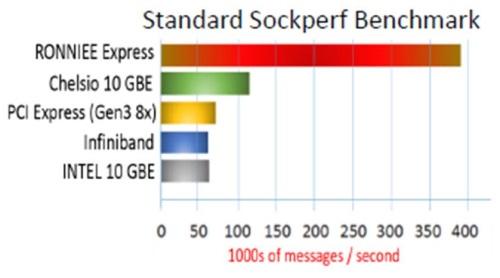
The aim for A3Cube will be primarily in HFT, genomics, oil/gas exploration and real-time data analytics. Prototypes for merchants are currently being worked on, and it is expected that two versions of network cards and a 1U switch based on the technology will be available before July.
The new IP from A3Cube is kept hidden away, but the logic points towards device enumeration and the extension of the PCIe root complex of a cluster of systems. This is based on the quote regarding PCIe 3.0 incompatibility based on the different device enumeration in that specification. The plan is to build a solid platform on PCIe 4.0, which puts the technology several years away in terms of non-specialized deployment.
As many startups, the process for A3Cube is to now secure venture funding. The approach to Ronniee Express is different to that of PLX who are developing a direct PCIe interconnect for computer racks.
A3Cube’s webpage on the technology states the fabric uses a combination of hardware and software, while remaining application transparent. The product combines multiple 20 or 40 Gbit/s channels, with the aim at petabyte-scale Big Data and HPC storage systems.
Information from Willem Ter Harmsel puts the Ronniee NIC system as a global shared memory container, with an in-memory network between nodes. CPU/Memory/IO are directly connected, with 800-900 nanosecond latencies, and the ‘memory windows’ facilitates low latency traffic.
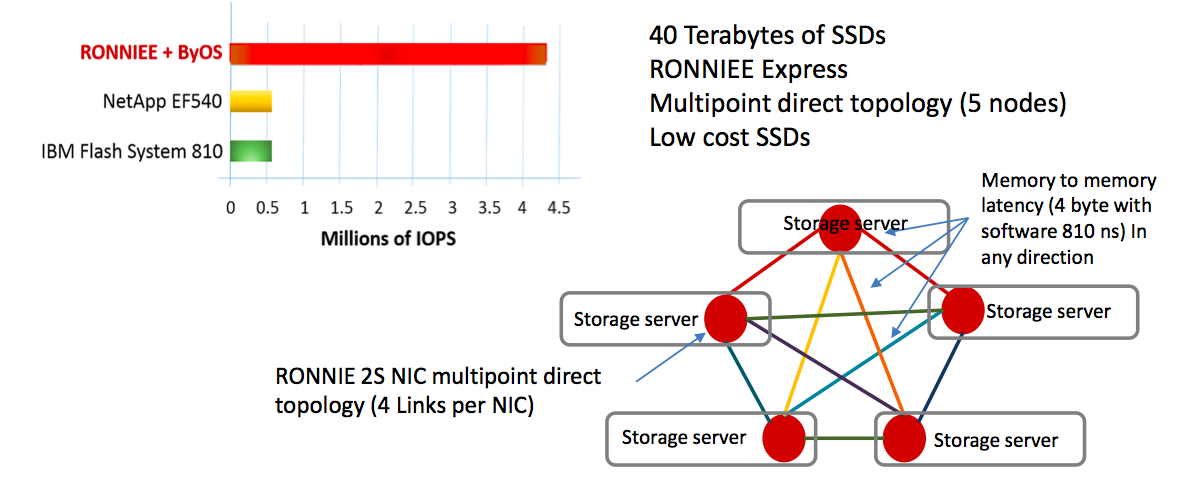
Using A3cube’s storage OS, byOS, and 40 terabytes of SSDs and the Ronniee Express fabric, five storage nodes were connected together via 4 links per NIC allowing for 810ns latency in any direction. A3Cube claim 4 million IOPs with this setup.
Further, in interview by Willem and Anontella Rubicco shows that “Ronniee is designed to build massively parallel storage and analytics machines; not to be used as an “interconnection” as Infiniband or Ethernet. It is designed to accelerate applications and create parallel storage and analytics architecture.”
Source: EETimes, A3Cube, willemterharmsel.nl.








9 Comments
View All Comments
nutgirdle - Wednesday, February 26, 2014 - link
Why couldn't it be used as an interconnect? If this is such a low-latency physical layer, why wouldn't an MPI-enabled stack be possible? I suppose MPI is tuned for ethernet and/or infiniband, and the overhead might be a bit high, but it still seems like a rather obvious application. I'd appreciate continued coverage of this particular technology.xakor - Wednesday, February 26, 2014 - link
I think that they are implying interconnection is an easy problem with respect to their technology, not that you can't do it.antoanto - Wednesday, February 26, 2014 - link
Absolutely yes, RONNIEE Express can be used as interconnect and we have the native MPI interface ready to use.The OSU 4.0 benchmark shows a point to point latency of 1 us.
Some Universities are using RONNIEE Express for specific applications and soon we can provide that result too
BMNify - Wednesday, February 26, 2014 - link
antoanto, i realize that a3cube are there to make profits ,but it would be nice if you industrial vendors finally made the effort to provide some affordable mass market kits for the home/SOHO markets where the masses of end consumers with an average of 4 machines on site, are desperately asking for faster than antiquated 1GbE at a reasonable all in price for more than a decadeantoanto - Wednesday, February 26, 2014 - link
BMNify, one of the reason because we started to develop RONNIEE Express is to provide a disruptive solution with a affordable price also for small solutions ( 4 machines).One of our consideration was that small teams of researchers, engineers, graphics have not enough money to buy faster solutions, RONNIEE may be the answer to that need.
Kevin G - Wednesday, February 26, 2014 - link
I'm not understanding how they're able to exceed an 8x PCI-e 3.0 speed link. With a bit of network tunneling hardware to create a virtual TCP/IP interface and an IOMMU, network transfers between two nodes accross the 8x PCI-e 3.0 link should operating at near DMA speeds. For generic IO, it doesn't get faster than that (well other than adding more PCI-e lanes to the setup).I do have to give credit to a3cube for the true mesh topology. That could be the secret to how they're able to reach such performance claims. It would also come with all the negatives of a true mesh: extensive cabling and limited scalability as the node count increases.
antoanto - Wednesday, February 26, 2014 - link
The article simplify too much what we explain.Please, watch http://www.youtube.com/watch?v=YIGKks78Cq8
And if you want more clarification feel free to contact us ( www.a3cube-inc.com)
gsvelto - Wednesday, February 26, 2014 - link
The use of sockperf to compare this interconnect performance with InfiniBand solutions is shoddy at best. sockperf uses regular IP sockets to perform its tests which is most likely to run using the IPoIB layer in an InfiniBand setup. Using the native InfiniBan APIs (verbs) in my personal experience usually yields 2-4x higher effective bandwidth and 10x higher message throughput (which for small messages is mostly bottlenecked by the CPU used, not the interconnect).antoanto - Wednesday, February 26, 2014 - link
We know, but we want compare the TCP/UDP socket performance because we want to run completely unmodified application with the maximum performance as possible.If you want to use IB verbs you need to use a modified application not a TCP/IP and of course you will have extraordinary performance, but if you don't have the source code of the application or the money and the time to do that you can not.
In any case also RONNIEE Express has a powerful native API that if you want to port your application give you more and more performance. What we show is our in memory TCP/IP socket compared with the standard one, so sockperf and netperf ( for UDP) are good to show very easily the difference.
We don't want to compete with IB, we want to use standard socket based unmodified application at the maximum speed as possible with no code changes.