Fall 2013 Supercomputer Rankings Released; Achieving Max Efficiency With Oil
by Ryan Smith on November 22, 2013 3:00 PM EST
Turning our eyes back towards SC13 and supercomputers one more time this week, we have the biannual supercomputer rankings, which are released every spring and every fall. These rankings are composed of the Top500 and Green500, which rank supercomputers based on total performance and power efficiency respectively. These lists are admittedly mostly for bragging rights, but they do give us an interesting look at what the top computers in the world currently look like.
| Top500 Top 6 Supercomputers | ||||||
| Supercomputer | Architecture | Performance (Rmax, TFLOPS) | Power Consumption (kW) | Efficiency (MFLOPS/W) | ||
| Tianhe-2 | Xeon + Xeon Phi | 33862.7 | 17808 | 1901.5 | ||
| Titan | Opteron + Tesla | 17590.0 | 8209 | 2142.7 | ||
| Sequoia | BlueGene/Q | 17173.2 | 7890 | 2176.5 | ||
| K Computer | SPARC64 | 10510.0 | 12660 | 830.1 | ||
| Mira | BlueGene/Q | 8586.6 | 3945 | 2176.5 | ||
| Piz Daint | Xeon + Tesla | 6271.0 | 1753 | 3185.9 | ||
Starting with the Top500, the top of the list remains unchanged from what we saw in June. Further supercomputers have come online in the last 6 months, but none large enough in scale to compete with the top supercomputers. This means that the Xeon + Xeon Phi powered Tianhe-2 remains as the top supercomputer in the world, offering a staggering 33.8 PFLOPS of performance, almost twice that of the next fastest computer. This also continues Intel’s rule of the top of the list, with the Xeon powered supercomputer having now held the top for two iterations of the list.
Moving down the list, we have the Opteron + Tesla based Titan, the Bluegene/Q based Sequoia and Mira, and the SPARC64 based K Computer. The first new supercomputer on the list comes in at #6, and that’s the Swiss National Computing Center’s Piz Daint. Piz Daint was first announced back in March and is now fully up and running, based on a Cray XC30 which in turn is a combined Xeon + Tesla system. Piz Daint weighs in at 6.2 PFLOPS, thereby making it the most powerful supercomputer in Europe. This also marks the second Tesla K20 system to make the top 10, tying Intel’s pair of Xeon Phi systems but still well behind the 4 Bluegene/Q systems that occupy the top of the list.
Also released this week was the Green500 list, which is a derivation of the Top500 list sorted by power efficiency instead of total performance. Since the Green500 list isn’t decided on raw performance it often sees a much higher rate of turnover than the Top500 list, as smaller scale computers can enter the top of the list if they’re efficient enough.
| Green500 Top 5 Supercomputers | ||||||
| Supercomputer | Architecture | Performance (Rmax, TFLOPS) | Power Consumption (kW) | Efficiency (MFLOPS/W) | ||
| TSUBAME-KFC | Xeon + Tesla | 150.4 | 27.7 | 4503.1 | ||
| Wilkes | Xeon + Tesla | 239.9 | 52.6 | 3631.8 | ||
| HA-PACS TCA | Xeon + Tesla | 277.1 | 78.7 | 3517.8 | ||
| Piz Daint | Xeon + Tesla | 6271.0 | 1753.6 | 3185.9 | ||
| Romeo | Xeon + Tesla | 254.9 | 81.4 | 3130.9 | ||
This November has seen exactly the above happen, with a number of smaller installations coming online and pushing older systems further down the list. For June you needed an efficiency level of 2,299 MFLOPS/W to make the top 10; for November you need 2358 MFLOPS/W. Which doesn’t sound like a huge difference, but it was enough to push systems 4 through 10 off of the top 10 list, meaning most of the list is composed of new supercomputers.
Interestingly, every new system on the list is some kind Xeon + Tesla K20 configuration, which in turn has led to the entire top 10 now being composed of those systems. In fact you have to go down past #11 – the Xeon + FirePro S10000 based SANAM computer – to find a system that isn’t GPU powered. The Green500 list is based on total power consumption – system plus cooling – so it isn’t just a measurement of system power efficiency, but except in the cases of Eurora, TSUBAME-KFC, and other computers that are using exotic cooling, everyone else is using standard air conditioning and as such system power efficiency is the deciding factor. To that end it’s clear that from an efficiency perspective GPUs have the market cornered, edging out both traditional CPU setups and even Xeon Phi setups (as GPU-like as they are).
Looking at some of the individual systems, the new champion of the Green500 is an interesting and admittedly small scale system out of Japan called TSUBAME-KFC. At 27.78 kW in power consumption and 150 TFLOPS, TSUBAME-KFC isn’t very powerful, but at 4,503 MFLOPS/W it’s by far the most efficient system on the list. The secret – and to our knowledge this is the only ranked supercomputer like this – is that TSUBAME-KFC is the only oil immersion supercomputer on the list. As we’ve seen in the past with systems such as Eurora, supercomputer builders are playing with increasingly exotic forms of cooling in order to keep power consumption down and to further increase efficiency, as the largest scale installations are bounded more by power/cooling needs than they are equipment costs.

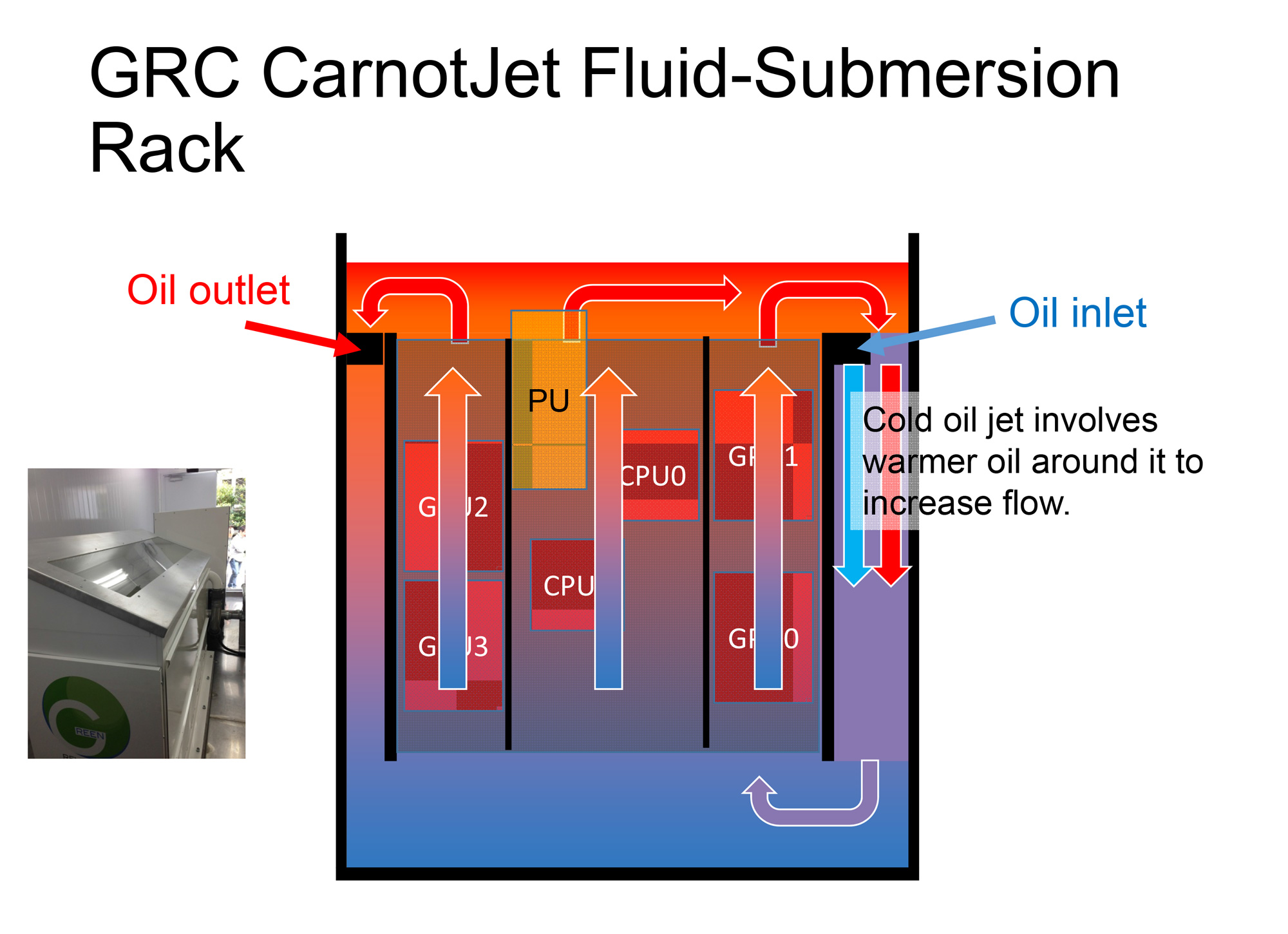
TSUBAME-KFC (Kepler Fluid Cooling, we’re told) takes this idea to the extreme by using non-conductive oil rather than air as the heat exchange medium. Oil doesn't have quite the immense heat capacity of water, but it allows for full immersion of the system nodes rather than requiring the use of tubing and water blocks. Coupled with system level optimizations undertaken by the system builders, such as turning down the GPU clockspeeds for efficiency rather than absolute performance, the builders were able to get the system up to 4,503 MFLOPS/W.
At 25% more efficient than the next closest supercomputer, TSUBAME-KFC is probably a safe bet for holding the top spot for another iteration. Any significant move on the list will require equally exotic cooling, or more likely a newer installation using newer processors, which is admittedly just a matter of time. Whether a traditional air cooled system can beat that mark remains to be seen, but we certainly expect all the usual parties – including the new IBM/NVIDIA partnership – to be potential contenders as their new processors and new manufacturing processes come online.








29 Comments
View All Comments
IanCutress - Friday, November 22, 2013 - link
The problem with oil is replacing components, a key element of large installations that might suffer a failure a day. Replacing an oily component means you smell like bad fries afterwards. Or maybe it's another sort of oil. Any info on which hydrocarbon being used and the specific heat capacity? :)Ryan Smith - Friday, November 22, 2013 - link
ExxonMobil SpectraSyn Polyalphaolefins (PAO)IanCutress - Friday, November 22, 2013 - link
As far as I can tell, they're C4 to C22 alkenes that are polymerised and further hydrogenated to alkanes. Patented chemicals are sometimes the hardest to find info of, and I suspect that these are a range of PAOs rather than one single type.The Von Matrices - Friday, November 22, 2013 - link
If the oil is pure alkanes and alkenes, it shouldn't have any smell at all. The aromatics and sulfurous compounds are the ones that have an odor. I work with FT Diesel in the lab, which this basically is, and there is no odor to it either. The petroleum Diesel with sulfur compounds and aromatics is the one that has the odor.I would think the biggest issue with replacing components is keeping the oil from spreading to everything in the room as components are moved around and replaced.
IanCutress - Friday, November 22, 2013 - link
Yes, the smell was a small bit of comedy :) I would imagine that if any sulphurous (natch, UK spelling ;]) links were present they'd attach pretty quickly to any exposed gold (excess pins etc) due to the low binding barrier therein.The name PAO is pretty generic, ExxonMobil have several SpectraSyn SKUs, and the datasheets on most of them had them as pretty viscous as far as I could tell. That wouldn't do much in terms of moving the oils around; I'd imagine there's a big-ass pump for each unit so push it through with fans along the way.
lwatcdr - Saturday, November 30, 2013 - link
My guess is that they remove the heat sink and keep the cooling loop intact when they swap parts.errorr - Friday, November 22, 2013 - link
The data sheet I saw claimed it was white mineral oil (your dielectric alkenes) with their own patented additive mixture (usually fluorocarbons) and I would assume some antioxidant to prevent free radical breakdown of the alkenes.They claim there is no evaporation and that the liquid need never be topped off or raplaced. The sheet also said the liquid is pumped through a heat exchanger where it uses tap water (hot or cold) to cool the system.
DanNeely - Friday, November 22, 2013 - link
In large scale installations the minimum size of a swap out module is much larger than in your home computer. I don't have any specific information about super computer installs; but it's probably similar to how huge internet company data centers work. Ex When MS went to containerized data centers their minimum swapout unit was an entire shipping container of computers. Individual computers failing within one were just disabled via admin tools.This question on ServerFault was asking specifically about storage capacity; but the answers focused on the general infrastructure that the disks were part of:
http://serverfault.com/q/535049/34835
nafhan - Friday, November 22, 2013 - link
Judging by the diagram above, the "swap out module" might not be much larger than a typical blade server, as it appears to be a self contained unit consisting of 2 CPU's, 4 GPU's and associated system board(s).Also, there's a decent chance that the module itself has no moving parts which are generally the first thing to go on a system. In the facility I work in, we only have a handful of non-disk or fan (or PS, which is usually the fan) related failures a year across a couple thousand servers. Get rid of the moving part failures, and we'd probably be swapping out less than one "module" a month at a location like mine.
nathanddrews - Friday, November 22, 2013 - link
So cool.