Intel’s Silvermont Architecture Revealed: Getting Serious About Mobile
by Anand Lal Shimpi on May 6, 2013 1:00 PM EST- Posted in
- CPUs
- Intel
- Silvermont
- SoCs
OoOE
You’re going to come across the phrase out-of-order execution (OoOE) a lot here, so let’s go through a quick refresher on what that is and why it matters.
At a high level, the role of a CPU is to read instructions from whatever program it’s running, determine what they’re telling the machine to do, execute them and write the result back out to memory.
The program counter within a CPU points to the address in memory of the next instruction to be executed. The CPU’s fetch logic grabs instructions in order. Those instructions are decoded into an internally understood format (a single architectural instruction sometimes decodes into multiple smaller instructions). Once decoded, all necessary operands are fetched from memory (if they’re not already in local registers) and the combination of instruction + operands are issued for execution. The results are committed to memory (registers/cache/DRAM) and it’s on to the next one.
In-order architectures complete this pipeline in order, from start to finish. The obvious problem is that many steps within the pipeline are dependent on having the right operands immediately available. For a number of reasons, this isn’t always possible. Operands could depend on other earlier instructions that may not have finished executing, or they might be located in main memory - hundreds of cycles away from the CPU. In these cases, a bubble is inserted into the processor’s pipeline and the machine’s overall efficiency drops as no work is being done until those operands are available.
Out-of-order architectures attempt to fix this problem by allowing independent instructions to execute ahead of others that are stalled waiting for data. In both cases instructions are fetched and retired in-order, but in an OoO architecture instructions can be executed out-of-order to improve overall utilization of execution resources.
The move to an OoO paradigm generally comes with penalties to die area and power consumption, which is one reason the earliest mobile CPU architectures were in-order designs. The ARM11, ARM’s Cortex A8, Intel’s original Atom (Bonnell) and Qualcomm’s Scorpion core were all in-order. As performance demands continued to go up and with new, smaller/lower power transistors, all of the players here started introducing OoO variants of their architectures. Although often referred to as out of order designs, ARM’s Cortex A9 and Qualcomm’s Krait 200/300 are mildly OoO compared to Cortex A15. Intel’s Silvermont joins the ranks of the Cortex A15 as a fully out of order design by modern day standards. The move to OoO alone should be good for around a 30% increase in single threaded performance vs. Bonnell.
Pipeline
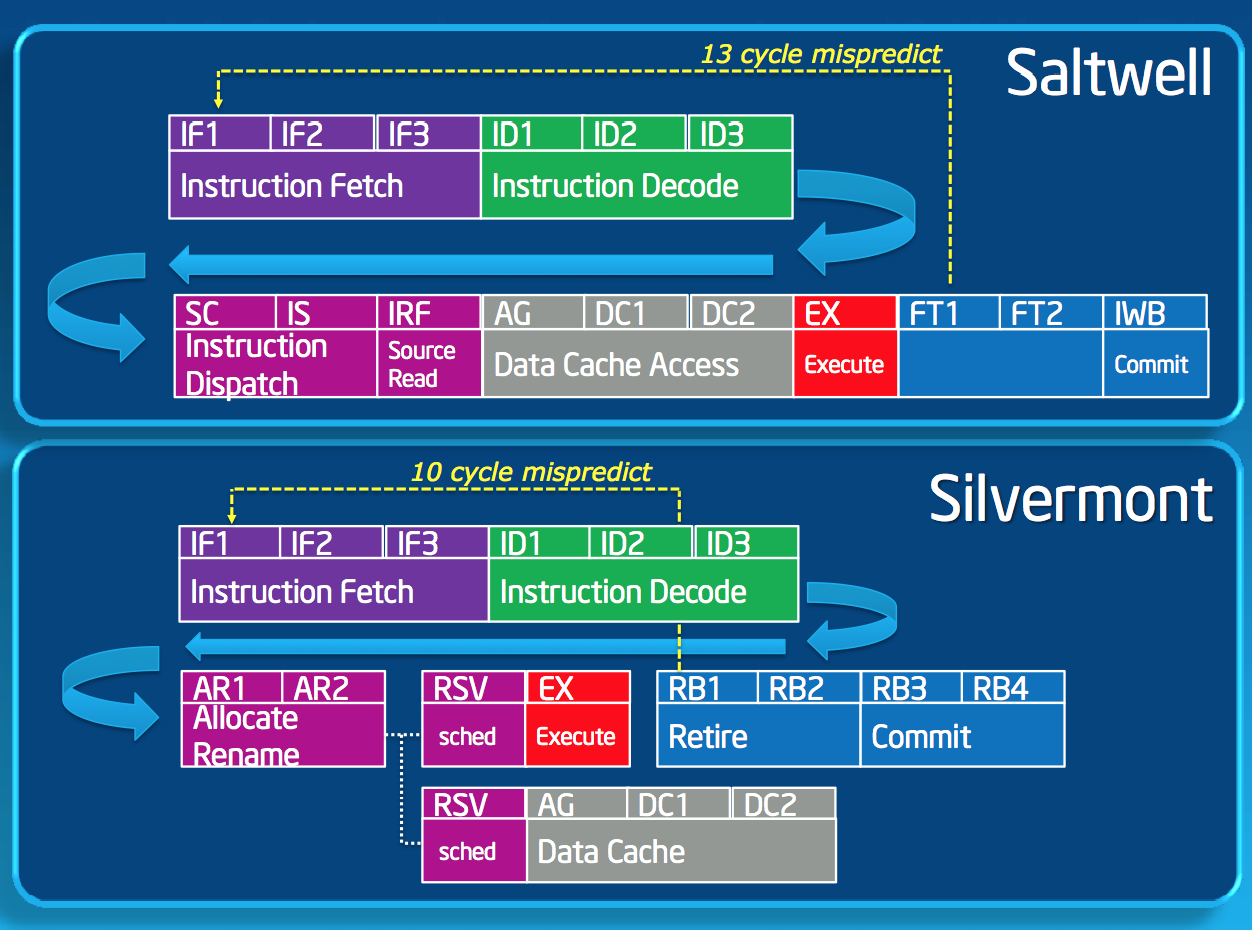
Silvermont changes the Atom pipeline slightly. Bonnell featured a 16 stage in-order pipeline. One side effect to the design was that all operations, including those that didn’t have cache accesses (e.g. operations whose operands were in registers), had to go through three data cache access stages even though nothing happened during those stages. In going out-of-order, Silvermont allows instructions to bypass those stages if they don’t need data from memory, effectively shortening the mispredict penalty from 13 stages down to 10. The integer pipeline depth now varies depending on the type of instruction, but you’re looking at a range of 14 - 17 stages.
Branch prediction improves tremendously with Silvermont, a staple of any progressive microprocessor architecture. Silvermont takes the gshare branch predictor of Bonnell and significantly increased the size of all associated data structures. Silvermont also added an indirect branch predictor. The combination of the larger predictors and the new indirect predictor should increase branch prediction accuracy.
Couple better branch prediction with a lower mispredict latency and you’re talking about another 5 - 10% increase in IPC over Bonnell.








174 Comments
View All Comments
Amoro - Monday, May 6, 2013 - link
In the first sentence of the paragraph below the Saltwell Vs. Silvermont graph, it states "In terms of absolute performance, Saltwell’s peak single threaded performance is 2x that of Saltwell" and it should be "Silvermont's peak single...."ClockworkPirate - Monday, May 6, 2013 - link
Also at the end of the first paragraph on the "Tablet Expectations and Performance" page, "...with Haswell picking up above Haswell." should probably be "...with Haswell picking up above Bay Trail."chrone - Monday, May 6, 2013 - link
this is the soc i've been waiting for since 2008. winter is coming!! it's gonna be a long winter for arm and friends ahead. \m/theos83 - Monday, May 6, 2013 - link
lol...wait and watch...it has been a long winter for intel (from a mobile market point of view), lets see what they end up with in the next 4 years...ARM and friends are not going away anytime soon.Hector2 - Friday, May 17, 2013 - link
True. The difference between then and now is that Intel didn't have an SoC designed and optimized for smartphones. Now they do (this year) and it'll be about 22nm & 14nm offering Intel higher performance, lower power and lower cost. In this area Intel has about a 2 year lead on their competitionKrysto - Monday, May 6, 2013 - link
It's very, very, VERY hard to beat a monopoly in a certain market (ARM that is), even with a company like Intel that may have a monopoly in another.Plus they have like a dozen competitors there, with at least 3-4 top ones. Intel has promised a lot of stuff before, and under-delivered. So we'll see. ARM chips are also going 20nm and 64 bit next year, and at 14nm FinFET the year after that (yes, only a year later).
Plus, if these things cost 2-3x what the high-end ARM chips cost, they can just pack and go home. No OEM will accept that, unless Intel gives them Haswell in PC's for 30% off, or some deal like that (which would mean they won't be making any money on these Atoms anytime soon).
klmccaughey - Tuesday, May 7, 2013 - link
Intel has the cash to loss-lead on this and open a big crack into the market. It also has the bucks to advertise.My guess is that shareholders are screaming for Intel to get into this market. All the omens look good and I am really looking forward to a big jump in power and battery life for mobiles. I think ARM finally has a real competitor.
HisDivineOrder - Tuesday, May 7, 2013 - link
Intel (and MS) are still under the delusion they're in the 1990's where they could be a premium vendor. Look at all the Windows tablets for proof of this. Intel and MS are both charging way more than they should and all their Wintel tablets (RT or 8) are overpriced by a huge amount.Intel doesn't loss lead. At least, they haven't shown any sign of it at all. Maybe this will be their moment, but somehow... I really, really doubt it.
zeo - Wednesday, May 8, 2013 - link
Don't confuse Intel with the OEMs and MS, Intel isn't over charging on their hardware!The listed Tray cost for the Clover Trail Z2760 SoC is only $41, at a time when ARM high end SoCs are starting to go over $30... So there's not a multiple times cost difference anymore.
OEMs just mistakenly took their cue from MS pricing of the Surface and it's not like the tablet market is really set up for PC configurations.
OEMs for example are used to using internal drive capacity as a way of charging more of their products. Like it doesn't cost anywhere near $50 to double the drive capacity of a Nexus 7 for example or how Apple charges a $100 for each doubling of capacity.
Remember, Windows tablets start with 32GB and that's much higher minimum than what mobile devices still offer.
Along with inclusion of full size USB ports, the added cost of Windows license, the greater tendency to include premium parts like WACOM digitizers, etc all added together for how the pricing finally came out...
However, the OEMs should have learned their lessons, MS is definitely going to offer them better volume license fees this time around, and Bay Trail is suppose to be even lower priced than Clover Trail... So we should see much better pricing with this new generation of products.
BSMonitor - Wednesday, May 8, 2013 - link
Its not a monopoly. There are several companies that build ARM SoC's. ARM is an ISA, no different than x86. If Intel delivers quantity, better performaning SoC's than the competitors, best believe they will switch. Apple already does x86 in house on OS X. Promise you they have been testing Atom in house for potential future designs.. Whether those designs win over ARM A# in house designs is another matter... Intel is nothing if not good at getting companies to sign up with them.. They deliver the highest quality and highest quantities of anyone in the silicon business.