AMD Radeon HD 7970 GHz Edition Review: Battling For The Performance Crown
by Ryan Smith on June 22, 2012 12:01 AM EST- Posted in
- GPUs
- AMD
- GCN
- Radeon HD 7000
Compute Performance
Shifting gears, as always our final set of performance benchmarks is a look at compute performance. As we saw with the launch of the GTX 680, Kepler (GK104) just doesn’t do very well here, thanks in part to NVIDIA stripping out a fair bit of compute hardware and memory bandwidth on GK104 in order to focus on gaming performance. OpenCL performance is particularly bad with NVIDIA almost completely ignoring it, but even DirectCompute performance often swings AMD’s way. This isn’t to say that GK104 doesn’t have its moments, but when it comes to compute it’s typically AMD’s time to shine.
Our first compute benchmark comes from Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. Note that this is a DX11 DirectCompute benchmark.
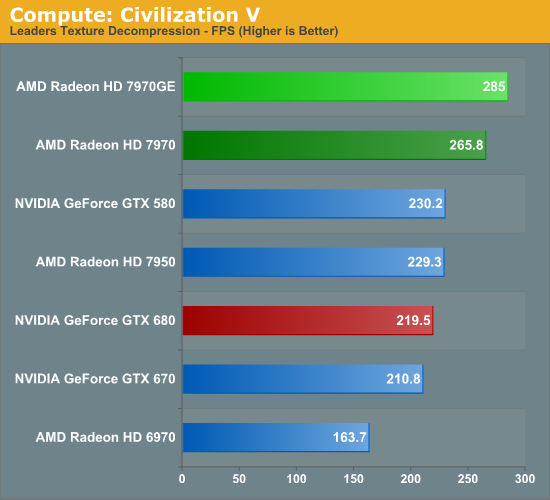
The 7970 already had a significant lead in this benchmark thanks to AMD’s work on improving their DirectCompute performance, and the 7970GE extends it further. The most important factor of course is actual game performance – where the 7970GE and GTX 680 are tied – but this is clear software evidence of what we already know in hardware: that the 7970GE is far more potent at compute than the GTX 680 is.
Our next benchmark is SmallLuxGPU, the GPU ray tracing branch of the open source LuxRender renderer. We’re now using a development build from the version 2.0 branch, and we’ve moved on to a more complex scene that hopefully will provide a greater challenge to our GPUs.

Being an OpenCL title that NVIDIA isn’t taking any care to optimize for, the 7970GE simply blows the GTX 680 out of the water. It’s not even a contest here. Only one card family is even worth consideration for use here. However it’s interesting to note that the 7970GE’s performance improvement over the 7970 is a bit below average, with the 7970GE only picking up 6%. SLG does stress memory bandwidth and compute performance, but in all likelihood the 7970GE isn’t boosting as much here as it is under our gaming tests. Once AMD starts exposing real clockspeeds we’ll need to revisit this assumption.
For our next benchmark we’re looking at AESEncryptDecrypt, an OpenCL AES encryption routine that AES encrypts/decrypts an 8K x 8K pixel square image file. The results of this benchmark are the average time to encrypt the image over a number of iterations of the AES cypher.

While the 7970GE does improve upon the 7970’s already strong performance, we’re clearly reaching the point where the relatively long CPU/GPU transfer times over PCIe are taking their toll, explaining why the 7970GE could only shave off 5ms. This is actually an important point to make and is why APUs are so important to AMD’s GPU computing plans, but it also means that at a certain speed GPU performance ceases to matter.
Our fourth benchmark is once again looking at compute shader performance, this time through the Fluid simulation sample in the DirectX SDK. This program simulates the motion and interactions of a 16k particle fluid using a compute shader, with a choice of several different algorithms. In this case we’re using an (O)n^2 nearest neighbor method that is optimized by using shared memory to cache data.

In this final compute shader benchmark NVIDIA’s performance is actually quite respectable, leading to them besting the 7970. However the 7970GE provides just enough of a performance boost to push AMD ahead of NVIDIA here, giving AMD a solid majority of our standard compute benchmarks. Even when Kepler is faced with a favorable workload, it looks like GCN based 7970GE is capable of taking NVIDIA head-on.
Finally, we received a number of requests for some further compute benchmarking using some of the consumer programs AMD provided the press with for the Trinity launch. In particular WinZip and handbrake were requested, so we’ve gone ahead and run those benchmarks for this review.
Starting with WinZip, WinZip 16.5 introduced OpenCL acceleration of both compression and AES achieve encryption. Despite being accelerated via OpenCL WinZip only supports AMD devices, presumably because only AMD provided technical assistance. As a result we’re looking solely at pure CPU performance and GPU accelerated performance across AMD’s lineup.
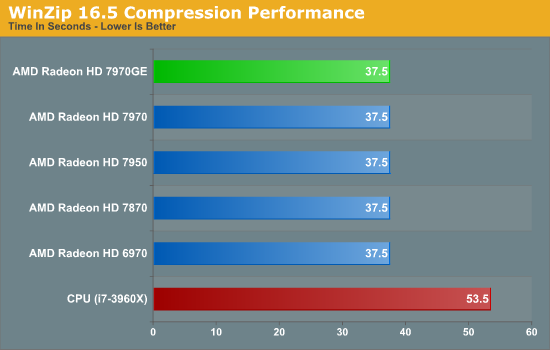

One thing immediately sticks out: WinZip isn’t very sensitive to GPU performance. Merely having a GPU increases performance rather significantly, but it doesn’t matter if it’s a fast GCN card or a GCN card at all for that matter, as even the VLIW4 based 6970 returns the same times. In fact AMD’s drivers report almost no GPU load, so it’s questionable how much of this is actually being run on the GPU versus being run on the CPU through AMD’s OpenCL CPU driver.
As for Handbrake, AMD sent along a newer version that works with discrete GPUs. AMD notes that this is still very much a work in progress, which we saw first-hand when OpenCL acceleration failed to handle two of our three test clips. It failed to properly crop one video, and failed to properly detelecine another. Handbrake’s OpenCL acceleration will of course continue to improve as it approaches release, but for the time being it’s definitely a beta.
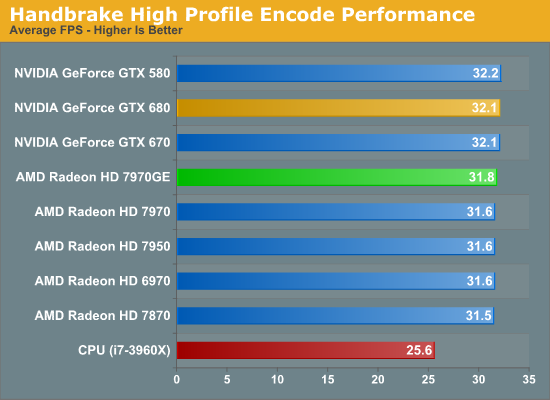
Much like WinZip, Handbrake doesn’t appear to be particularly GPU performance sensitive, which doesn’t come as much of a surprise. Large parts of the H.264 encoding process are ill suited for GPU acceleration, so X.264 is only offloading part of the process and the deciding factor is still CPU performance. The actual GPU load is very inconsistent, but generally tops out at around 40% usage.
The end result is nothing to sneeze at however. Whereas Handbrake averaged 25.6fps without GPU acceleration, with it performance increases by 24% to around 32fps. And unlike other GPU compute accelerated encoders the quality here is very consistent between the CPU and GPU paths (though GPU file size tends to be a bit larger), which means we’re retaining the same quality and customizability of Handbrake/x264 while gaining additional performance for free.
Despite the fact that this is an AMD backed initiative it’s interesting to see that Handbrake’s performance isn’t heavily reliant on the GPU being used. We would have assumed that Handbrake was only optimized for AMD’s GPUs at this point, and even if that’s the case NVIDIA’s GPUs are still fast enough to make up the difference. The fact that Handbrake performance with NVIDIA’s GPUs is a hair faster is not at all what we would have expected, but at the same time this is very beta quality software and is likely dependent on the clip being used, so we wouldn’t advise reading too much into this at this time.








110 Comments
View All Comments
clumsyalex - Friday, June 22, 2012 - link
the first chart, the regular 7970 is priced higher than the ghz edition. the second chart shows it as lower howeverRyan Smith - Friday, June 22, 2012 - link
Actually those are a list of launch prices up top. The 7970 launched at $550, which is indeed higher than the $500 launch price of the 7970GE.EnerJi - Friday, June 22, 2012 - link
It's confusing and misleading. The first thing I thought when I saw it was that you had accidentally reversed the prices between the two models.Iketh - Friday, June 22, 2012 - link
that certainly isn't what I thought... i understood what was being presented to meCeriseCogburn - Saturday, June 23, 2012 - link
I love how amd has a birthday for tahiti at 6 months....Why wait a year for a birthday when you're a lying sack of crap corporate monster rip off crummy drivers fan boy mass brainwash co ?
Heck, two birthdays a year !!! amd is so great, they get two birthdays a year !
silverblue - Monday, June 25, 2012 - link
People in the first few months of a relationship like to mention anniversaries a lot despite the (rather obvious) point that the word denotes a yearly period. "Milestone" would be more appropriate though it does sound less glamourous and perhaps a bit pessimistic (well, in the case of relationships, anyway). Might even seem cynical.Captmorgan09 - Friday, June 22, 2012 - link
Just read the chart and it's not confusing... I did a double take the first time I glanced at it, but when I actually read it it made perfect sense. :)Ryan Smith - Friday, June 22, 2012 - link
In case it's not clear, since we have a price comparison chart at the bottom, the purpose of the prices up top is to help describe the cards. The fact that the 7970GE is listed for $500 next to the $550 7970 for example is to make it clear that it's launching at a lower price than the 7970. It helps offer some perspective on capabilities and the market segment it's designed for.That said, we can always get rid of it if it's a problem.
QChronoD - Friday, June 22, 2012 - link
Could I suggest adding when they launched on the line right above the prices? I can easily see how that is confusing, but also knowing how old each generation would be useful to see.Ryan Smith - Friday, June 22, 2012 - link
Now that's an excellent idea!