Intel Announces Xeon Phi Family of Co-Processors – MIC Goes Retail
by Ryan Smith on June 19, 2012 1:00 AM ESTAs conference season is in full swing, this week’s big technical conference is the 2012 International Supercomputing Conference (ISC) taking place over in Hamburg, Germany. ISC is one of the traditional venues for major supercomputing and high performance computing (HPC) announcements and this year is no exception. Several companies will be showing off their wares, but perhaps the biggest announcement of the week is from Intel. After having worked on the project for over half a decade in some form or another they’re finally ready to take a stab at the parallel computing market by bringing their first Many Integrated Core (MIC) product to market. Knights Corner, the codename for the first such product, will be the launch product for a brand new family of Intel co-processors, which the company is introducing as the Xeon Phi family.

As a bit of background on the subject, as many of our regular readers are aware Intel has been working for a while now on various high performance highly parallel CPU and GPU designs based on their x86 architecture. Initially intended to fill a gap in the High Performance Computing space where users have workloads that are highly parallel (as opposed to highly serial), these designs would be able to quickly tear through highly parallel workloads by using a large collection of small, simple x86 cores that would be far better suited to the task than the large, complex x86 cores that are necessary for a modern CPU.
The first and still most famous of these projects was Larrabee, which initially unveiled in 2008 was Intel’s first attempt at building such an HPC processor in the form of a graphics capable CPU. Larrabee was to be Intel’s answer to practically NVIDIA’s entire desktop GPU lineup, with Larrabee intended to confront GeForce on the graphics side and the then-fledgling Tesla on the HPC side, both served by a single processor similar to how NVIDIA uses the same GPUs in both Tesla and GeForce products. Larrabee of course never came to fruition, and in 2010 Intel canceled it while continuing their research into parallel processing.
Larrabee’s successor was named shortly thereafter under a new architecture called Many Integrated Core (MIC), which in many ways was a direct continuation from where Larrabee left off. MIC kept the concept of multiple simple X86 cores, but threw away any pretense of graphics in favor of focusing solely on HPC computing. Even at more than 2 years out from launch Intel already had a plan for MIC, announcing the codename of the first processor – Knights Corner – which would have 50+ cores and be manufactured on Intel’s 22nm process.
This brings us to the present and Intel’s latest announcement. With Intel’s 22nm process in full production Intel is adhering to their previously announced plans and is getting ready to bring MIC to the market. So with ISC 2012 as the logical backdrop for such a product, Intel is announcing that Knights Corner will be launching into retail as the Xeon Phi family of co-processors.

At this point we don’t have the full technical details of the Xeon Phi family – Intel is still holding their cards close to their chest at this time – but with this announcement we do finally have some additional details on the hardware and how Intel intends to market it. The first generation of Xeon Phi products will be composed of an unknown number of products in the form of PCIe cards. Intel hasn’t nailed down the specific number of cores, keeping it at a nebulous 50+, but we do know that Intel is sticking to the goal of offering 1TFLOP of real world double-precision (FP64) performance; for comparison Tesla M2090 and Radeon HD 7970 have a theoretical FP64 throughput of 665GFLOPs and 947GFLOPs respectively. As for memory, Xeon Phi boards will come with at least 8GB of GDDR5, which marks the first time Intel has ever paired up a CPU with what’s otherwise graphics memory. Meanwhile the fact that it’s 8GB means we’re looking at either a 256-bit or 512-bit memory bus.
Intel isn’t using the Xeon Phi announcement to bring a great deal of attention to the underlying architecture, but all indications are that it’s closely related to what we first saw with Larrabee, with Intel confirming that it is indeed using an enhanced Pentium 1 (P54C) core with the addition of vector and FP64 hardware. Intel has also confirmed that Xeon Phi will offer 512-bit SIMD operations, which means we’re almost certainly looking at a 16-wide vector ALU in each core, the same kind of vector unit that Larrabee was detailed to have.
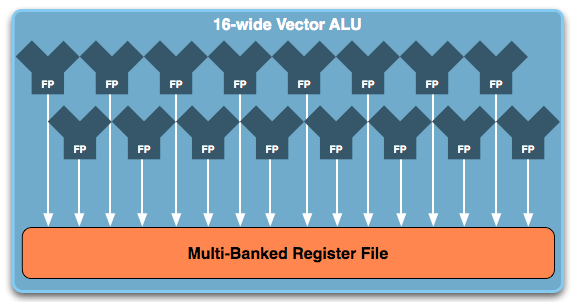
High Level Overview Of Larrabee's Vector ALU
We also don’t have any deep details about its fabrication – all indications are that Knights Corner is going to be large for an Intel processor – but Intel has reiterated that it’s being built on their 22nm process. Traditionally Intel has reserved their leading edge process for their higher margin mainstream products such as Core and Xeon processors, with Atom, Itanium, and other low-margin/niche products being a node (or more behind). Xeon Phi will be the first niche product to be built on Intel’s 22nm process with Atom following it up in the future.
Meanwhile on the software side of things in an interesting move Intel is going to be equipping Xeon Phi co-processors with their own OS, in effect making them stand-alone computers (despite the co-processor designation) and significantly deviating from what we’ve seen on similar products (i.e. Tesla). Xeon Phis will be independently running an embedded form of Linux, which Intel has said will be of particular benefit for cluster users. Drivers of course will still be necessary for a host device to interface with the co-processor, with the implication being that these drivers will be fairly thin and simple since the co-processor itself is already running a full OS.

All of this of course is designed to further build upon x86. The fundamental purpose of the Xeon Phi family is to bring highly threaded processing to x86, allowing x86 developers to quickly integrate the co-processor into their existing workloads and code as opposed to having to target another ISA and any idiosyncrasies it may bring. With that said it’s interesting to note that while Xeon Phi co-processors can either be used as a proper co-processor alongside a traditional Xeon processor or as a standalone device, Intel’s marketing group is focusing on the latter to differentiate themselves from NVIDIA’s Tesla products. So while it’s possible to use both Xeon and Xeon Phi processors together on a single project it’s not clear just how common that’s going to be. Intel looks to be largely exploiting x86 for the familiarity of the ISA as opposed for the ability for code to run on either kind of Xeon.
Last but not least, Intel hasn’t put any hard date on availability but they have said they expect Xeon Phi co-processors to go into full production later this year, and in the meantime Intel has already produced enough co-processors to build a MIC based supercomputer that’s ranked #150 on the new TOP 500 list. Given the typical gap between volume production and when a product is available for purchase it’s likely that Xeon Phi co-processors won’t be available until the end of the year – if not next year – but regardless the timing is such that Intel will be going up against NVIDIA’s GK110-based Tesla K20, which is similarly expected by the end of the year. Meanwhile given AMD’s HPC ambitions with GCN we’re also not ready to rule them out, so all 3 parties may have major compute products out by the start of 2013.
Wrapping things up, as always we’ll be keeping on top of the Xeon Phi family and should have more details later this year once Intel nails down final specifications and pricing. So until then stay tuned.








54 Comments
View All Comments
Homeles - Tuesday, June 19, 2012 - link
Looks like Intel's going to kick Nvidia while they're down... since they're lacking a competitive 28nm GPU when it comes to FP64.Still, with Intel being a whole process node ahead, it's disappointing to see that they're only putting out a card roughly equivalent to the 7970. This is only the beginning of a new war, though.
Khato - Tuesday, June 19, 2012 - link
It's not roughly equivalent to the 7970 though. The Xeon Phi manages roughly 1 TFlops in actual performance (rmax) whereas the 7970 is roughly 1 TFlops in theoretical performance (rpeak.) For GPUs, rmax is typically ~60% of rpeak.Spunjji - Tuesday, June 19, 2012 - link
According to Intel, it does. Given that one can buy and install a 7970 and one cannot yet buy the Laughabee card, I would say that AMD's "theoretical" performance is a lot more practical for the time being. By the time this thing comes out nVidia and AMD will be rolling out second-gen 28nm parts.DigitalFreak - Tuesday, June 19, 2012 - link
Hush child. The grownups are talking.Guspaz - Tuesday, June 19, 2012 - link
He does have a point, though. We're talking about the difference between the theoretical performance of a shipping product versus the vendor-reported performance of an unshipped product. It's a pretty silly comparison, really.taltamir - Monday, July 9, 2012 - link
Such a putdown is not something a grownup does.Also everything he said is correct.
rickcain2320 - Thursday, July 12, 2012 - link
Not to sound like a kid (or an out of touch grownup) but what is this Phi thing for?Pirks - Monday, August 13, 2012 - link
This fetus named DigitalStuck is named so for a reason, 'cause he's still stuck in vagina after so may years. Sometimes he tries to talk but labia majora keeps his hole plugged most of the time, fortunately for all of us.raghu78 - Tuesday, June 19, 2012 - link
So do you have any benchmarks to show that Intel Xeon Phi achieves 1 TFLOP actual DP performance. Until you have some real benchmarks its best not to comment. Radeon HD 7970 has been reviewed and has proved its compute performance in many benchmarks like LuxMark, SiSoft Sandra . These chips have been praised for their compute performance.http://www.anandtech.com/show/5314/xfxs-radeon-hd-...
http://www.tomshardware.com/reviews/geforce-gtx-68...
Sisoft Sandra measures DP performance.
Kevin G - Tuesday, June 19, 2012 - link
The Top 500 results score achieves 118 TFlop with 9800 cores. Making the big assumption that all of the performance was from a 50 core MIC card, that'd put performance per card at 602 Gflop double precision. At 64 cores per card, double precision performance would be 770 Gflop. Chances are that part of the result also used the SandyBridge CPU's, otherwise it would have made more sense to go with the quad core Xeons to make the power consumption figures look better. How much this would skew results would depend on the system configuration. Two Xeon E5-2670's per MIC card would have a bigger increase the performance per card rating than one Xeon E5-2670 for four MIC cards would.There are a few factors that could raise those scores. As a prototype, clock speeds were likely conservative and there is also the possibility of turbo coming into play. Further more results for a single card and host will likely be higher due to the removal of network overhead.
Regardless, these results paint Xeon Phi as merely competitive instead of having a decisive performance edge over its GPU counter parts.