The Bulldozer Aftermath: Delving Even Deeper
by Johan De Gelas on May 30, 2012 1:15 AM ESTIPC Analysis: What Is Going On?
We decided to focus our attention on our MS SQL Server benchmark and profile it on the most important hardware events (IPC, cache, and branch prediction). We used Intel's VTune Amplifier XE 2011 and AMD's Code Analyst 3.4.1037.88 to get a better understand of this benchmark. To put things into perspective, we compared the results with the extremely popular Cinebench benchmark and the 7-Zip compression benchmark.
Note that VTune has a rather steep learning curve and the numbers presented are more detailed but also harder to interprete than those of Code Analyst. In some cases we had doubts about our measurements on the brand spanking new Xeon E5. That is why we are refraining from publishing those numbers until we are absolutely sure they are accurate, so some of the Xeon E5 numbers are missing.
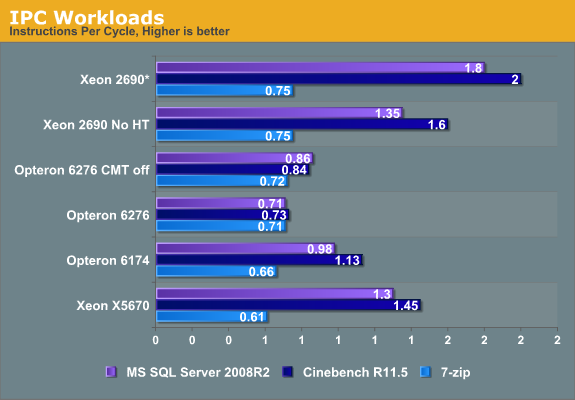
* We add the IPC of the two threads up
It is interesting to note the high Instruction Level Parallelism (ILP) that the Xeon E5 "Sandy Bridge" is able to extract out of these server benchmarks. Almost 1.4 instructions per clock cycle are retired and if you add SMT (Simultaneous Multi Threading), another 0.4 IPC flows through a single core. That is pretty remarkable for a benchmark that consists mostly of SQL statements that result in many branches and loads.
Our Opteron 6200 reveals a bit more about its internal working. Using the extra integer cluster inside the Opteron module causes the separate threads to slow down somewhat. In the case of Cinebench, this is not a real surprise since it contains a lot of SSE floating point commands; a single thread can have the out of order FP cluster all to itself while two threads have to share the SMT capable floating point engine.
But in case of our datamining benchmarks, something else is going on. Single-threaded performance regresses by 18% once you enable the second cluster. We get a 65% speed up (2x 0.71 vs 0.86), which is somewhat lower than the 80% predicted by the AMD slides discussing CMT. So some of the shared resources are slowing down the total performance of our module. We will find out more on the next page.








84 Comments
View All Comments
thunderising - Wednesday, May 30, 2012 - link
Glad AMD has "Greater Performance" planned sometime in the future. Wow!themossie - Wednesday, May 30, 2012 - link
"There are also other factors at play, though, as it's already known that StarCraft II doesn't use more than two cores; theinstead, it's likely the..."(feel free to remove comment after fixing this)
Nightraptor - Wednesday, May 30, 2012 - link
I am wondering if it would be possible to compare the processor performance of the Trinity A10 with a underclocked FX-4100 set to the same frequencies (I don't know if it is possible to disable the L3 cache on the FX-4100). This might give us a rough idea of how much the improvements of Piledriver have bought us. Just doing rough math in my head it would seem that they have to be pretty significant given how a FX-4100 compared to the Phenom II X4's (it lost alot, if not most of the time t of the time). The new A10 Trinity's on the other hand seem to win most of the time compared to the old architecture. Given that the A10 is a Piledriver based FX-4XXX series equivalent minus the L3 cache it would seem that Piledriver brought very significant enhancements. Either that or the Phenom II era processors responded much more poorly to the lack of L3 than Piledriver does.coder543 - Wednesday, May 30, 2012 - link
I was hoping they would be doing the same thing, even though it would be challenging to draw real information out of comparing a desktop processor and a mobile processor.SleepyFE - Wednesday, May 30, 2012 - link
+1kyuu - Wednesday, May 30, 2012 - link
+2If you can figure out some way to do a comparison and analysis of Piledriver's performance vs. Bulldozer, I think a great many of us are interested to see that. From benchmarks, it seems like Piledriver improved a great deal over Bulldozer, but it's difficult to tell without being able to compare two similar processors.
Aone - Wednesday, May 30, 2012 - link
You can compare A10-4600M or A8-4500M versus mobile Llano or Phenom or even Turion to see tweaked BD is nothing of spectacular. For instance, in most cases A8-4500M (2.3GHz base) loses to Llano A8-3500M (1.5GHz base).Nightraptor - Wednesday, May 30, 2012 - link
Where are you getting the benchmarks from that a Trinity loses to Llano. In almost all the benchmarks I have been able to find (with the exception of a few) it seems that Trinity beats Llano, hence the original post. If the Piledriver enhancements were very minor I would've expected Trinity (a hacked quad core) to lose to Llano most of the time (a true quad core). This didn't appear to happen - at least not in the anandtech review.Aone - Wednesday, May 30, 2012 - link
"http://www.notebookcheck.net/AMD-A-Series-A8-4500M...Look at "Show comparison chart". Great info!
Nightraptor - Thursday, May 31, 2012 - link
I'm not a big fan of the reliability of that website - They tend to be pretty scant on the test circumstances and configurations. Furthermore I'm curious where they are getting the informaiton for the A8-4500 as to the best of my knowledge the only Trinity in the wild at the moment is the A10 which AMD sent out in a custom made review laptop. All they list is a "K75D Sample".