HPC: Dell Says a Single PCIe x16 Bus Is Enough for Multiple GPUs – Sometimes
One of the more interesting sessions we saw was a sold-out session being held by Dell, discussing whether a single PCIe x16 bus provides enough bandwidth to GPUs working on HPC tasks. Just as in the gaming world, additional x16 busses come at a premium, and that premium doesn’t always offer the kind of performance that justifies the extra cost. In the case of rackmount servers, giving each GPU a full x16 bus either means inefficiently packing GPUs and systems together by locating the GPU internally with the rest of the system, or running many, many cables from a system to an external cage carrying the GPUs. Just as with gaming, if you can get more GPUs to share a PCIe bus then the cheaper it becomes. While for gaming this means using cheaper chipsets, for servers this means being able to run more GPUs off of a single host system, reducing the number of hosts an HPC provider would need to buy.
Currently the most popular configurations for the market Dell competes in are systems with a dedicated x16 bus for each GPU, and systems where 2 GPUs share an x16 bus. Dell wants to push the envelope here, and go to 4 GPUs per x16 bus in the near future, and upwards of 8 and 16 GPUs per bus in the far future when NVIDIA enables support for that in their drivers. To make that happen, Dell is introducing the PowerEdge C410x PCIe Expansion Chassis, a 3U chassis capable of holding up to 16 GPUs. Their talk in turn what about what they found when testing this cassis when filled with Tesla 1000 series cards (GT200 based) in conjunction with a C410 server.
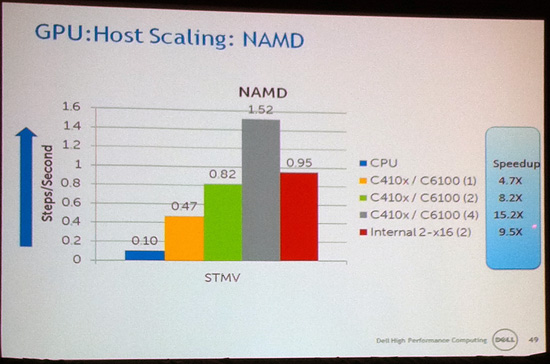
Ultimately Dell’s talk, delivered by staff Ph.D Mark R. Fernandez, ended up being an equal part about the performance hit of sharing a x16 bus, and whether the application in question will scale with more GPUs in the first place. Compared to the gold standard of one bus per GPU and internally locating the GPUs, simply moving to an external box and sharing an x16 bus among 2 GPUs had a negative impact in 4 of the 6 applications Dell tested with. The external connection would almost always come with a slight hit, while the sharing of the x16 bus is what imparted the biggest part of the performance hit as we would expect.
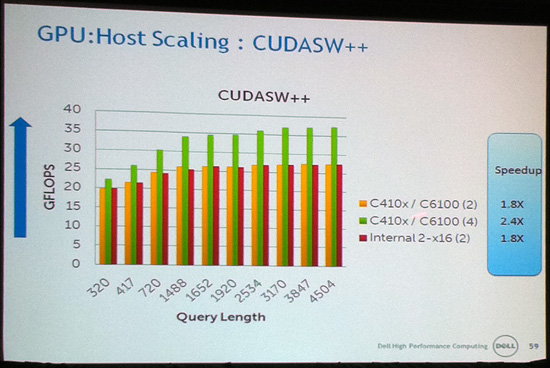
However when the application in question does scale beyond 1-2 GPUs, what Dell found was that the additional GPU performance more than offset the loss through a shared bus. In this case 4 of the same 6 benchmarks saw a significant performance improvement in moving from 2 to 4 GPUs; ranging between a 30% improvement and a 90% improvement. With these many GPUs it’s hard to separate the effects of the bus from scaling limitations, but it’s clear there’s a mix of both going on, in what seems particularly dependent on just how much bus chatter an application eventually causes.
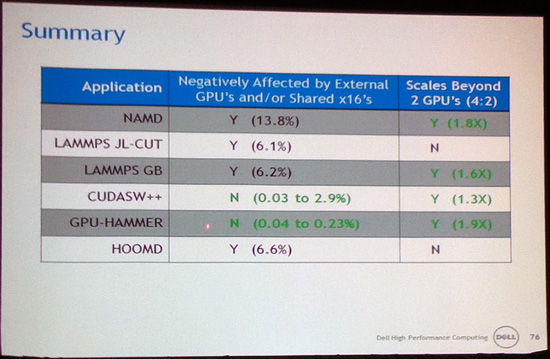
So with these results, Dell’s final answer over whether a single x16 PCIe bus is enough was simply “sometimes”. If an application scales against multiple GPUs in the first place, it usually makes sense to go further – after all if you’re already on GPUs, you probably need all the performance you can get. However if it doesn’t scale against multiple GPUs, then the bus is the least of the problem. It’s in between these positions where the bus matters: sometimes it’s a bottleneck, and sometimes it’s not. It’s almost entirely application dependent.
NVIDIA Quadro: 3D for More than Gaming
While we were at GTC we had a chance to meet with NVIDIA’s Quadro group, the first such meeting since I became AnandTech’s Senior GPU Editor. We haven’t been in regular contact with the Quadro group as we aren’t currently equipped to test professional cards, so this was the first step in changing that.
Much of what we discussed we’ve already covered in our quick news blurb on the new Quadro parts launching this week: NVIDIA is launching Quadro parts based on the GF106 and GF108 GPUs. This contrasts from their earlier Fermi Quadro parts, which used GF100 GPUs (even heavily cut-down ones) in order to take advantage of GF100’s unique compute capabilities: ECC and half-speed double precision (FP64) performance. As such the Quadro 2000 and 600 are more focused on NVIDIA’s traditional professional graphics markets, while the Quadro 4000, 5000, and 6000 cover a mix of GPU compute users and professional graphics users who need especially high performance.

NVIDIA likes to crow about their professional market share, and for good reason – their share of the market is much more one-sided than consumer graphics, and the profit margins per GPU are much higher. It’s good to be the king of a professional market. It also helps their image that almost every product being displayed is running a Quadro card, but then that’s an NV conference for you.
Along those lines, it’s the Quadro group that gets to claim much of the credit for the big customers NVIDIA has landed. Adobe is well known, as their Premiere Pro CS5 package offers a CUDA backend. However a new member of this stable is Industrial Light & Magic, who just recently moved to CUDA to do all of their particle effects using a new tool they created, called Plume. This is one of the first users that NVIDIA mentioned to us, and for good reason: this is a market they’re specifically trying to break in to. Fermi after all was designed to be a ray tracing powerhouse along with being a GPU compute powerhouse, and while NVIDIA hasn’t made as much progress here (the gold standard without a doubt being who can land Pixar), this is the next step in getting there.

Finally, NVIDIA is pushing their 3D stereoscopy initiative beyond the consumer space and games/Blu-Ray. NVIDIA is now looking at ways to use and promote stereoscopy for professional use, and to do so they cooked up some new hardware to match the market in the form of a new 3D Vision kit. Called 3D Vision Pro, it’s effectively the existing 3D Vision kit with all Infrared (IR) communication replaced with RF communication. This means the system uses the same design for the base and the glasses (big heads be warned) while offering the benefits of RF over IR: it doesn’t require line of sight, it plays well with other 3D Vision systems in the same area, and as a result it’s better suited for having multiple people looking at the same monitor. Frankly it’s a shame NVIDIA can’t make RF more economical – removing the LoS requirements alone is a big step up from the IR 3D Vision kit where it can be easy at times to break communication. But economics is why this is a professional product at the time: the base alone is $399, and the glasses are another $349, a far cry from the IR kit’s cost of $199 for the base and the glasses together.








19 Comments
View All Comments
adonn78 - Sunday, October 10, 2010 - link
This is pretty boring stuff. I mean the projectors ont eh curved screens were cool but what about gaming? anything about Nvidia's next gen? they are really falling far behind and are not really competing when it comes to price. I for one cannot wait for the debut of AMD's 6000 series. CUDA and PhysX are stupid proprietary BS.iwodo - Sunday, October 10, 2010 - link
What? This is GTC, it is all about the Workstation and HPC side of things. Gaming is not the focus of this conference.bumble12 - Sunday, October 10, 2010 - link
Sounds like you don't understand what CUDA is, by a long mile.B3an - Sunday, October 10, 2010 - link
"teh pr0ject0rz are kool but i dun understand anyting else lolz"Stupid kid.
iwodo - Sunday, October 10, 2010 - link
I was about the post Rendering on Server is fundamentally, but the more i think about it the more it makes sense.However defining a codec takes months, actually refining and implementing a codec takes YEARS.
I wonder what the client would consist of, Do we need a CPU to do any work at all? Or would EVERYTHING be done on server other then booting up an acquiring an IP.
If that is the case may be an ARM A9 SoC would be enough to do the job.
iwodo - Sunday, October 10, 2010 - link
Just started digging around. LG has a Network Monitor that allows you to RemoteFX with just an Ethernet Cable!.http://networkmonitor.lge.com/us/index.jsp
And x264 can already encode at sub 10ms latency!. I can imagine IT management would be like trillion times easier with centrally managed VM like RemoteFX. No longer upgrade every clients computer. Stuff a few HDSL Revo Drive and let everyone enjoy the benefit of SSD.
I have question of how it will scale, with over 500 machines you have effectively used up all your bandwidth...
Per Hansson - Sunday, October 10, 2010 - link
I've been looking forward to this technology since I heard about it some time ago.Will be interesting to test how well it works with the CAD/CAM software I use, most of which is proprietary machine builder specific software...
There was no mention of OpenGL in this article but from what I've read that is what it is supposed to support (OpenGL rendering offload)
Atleast that's what like 100% of the CAD/CAM software out there use so it better be if MS wants it to be successful :)
Ryan Smith - Sunday, October 10, 2010 - link
Someone asked about OpenGL during the presentation and I'm kicking myself for not writing down the answer, but I seem to recall that OpenGL would not be supported. Don't hold me to that, though.Per Hansson - Monday, October 11, 2010 - link
Well I hope OpenGL will be supported, otherwise this is pretty much a dead tech as far as enterprise industries are concerned.This article has a reply by the author Brian Madden in the comments regrading support for OpenGL; http://www.brianmadden.com/blogs/brianmadden/archi...
"For support for apps that require OpenGL, they're supporting apps that use OpenGL v1.4 and below to work in the VM, but they don't expect that apps that use a higher version of OpenGL will work (unless of course they have a DirectX or CPU fallback mode)."
Sebec - Sunday, October 10, 2010 - link
Page 5 -"... and the two companies are current the titans of GPU computing in consumer applications."Current the titans?
"Tom believes that ultimately the company will ultimately end up using..."