Better Image Quality: Jittered Sampling & Faster Anti-Aliasing
As we’ve stated before, the DX11 specification generally leaves NVIDIA’s hands tied. Without capsbits they can’t easily expose additional hardware features beyond what DX11 calls for, and even if they could there’s always the risk of building hardware that almost never gets used, such as AMD’s Tessellator on the 2000-4000 series.
So the bulk of the innovation has to come from something other than offering non-DX11 functionality to developers, and that starts with image quality.
We bring up DX11 here because while it strongly defines what features need to be offered, it says very little about how things work in the backend. The Polymorph Engine is of course one example of this, but there is another case where NVIDIA has done something interesting on the backend: jittered sampling.
Jittered sampling is a long-standing technique used in shadow mapping and various post-processing techniques. In this case, jittered sampling is usually used to create soft shadows from a shadow map – take a random sample of neighboring texels, and from that you can compute a softer shadow edge. The biggest problem with jittered sampling is that it’s computationally expensive and hence its use is limited to where there is enough performance to pay for it.
In DX10.1 and beyond, jittered sampling can be achieved via the Gather4 instruction, which as the name implies is the instruction that gathers the neighboring texels for jittered sampling. Since DX does not specify how this is implemented, NVIDIA implemented it in hardware as a single vector instruction. The alternative is to fetch each texel separately, which is how this would be manually implemented under DX10 and DX9.

NVIDIA’s own benchmarks put the performance advantage of this at roughly 2x over the non-vectorized implementation on the same hardware. The benefit for developers will be that those who implement jittered sampling (or any other technique that can use Gather4) will find it to be a much less expensive technique here than it was on NVIDIA’s previous generation hardware. For gamers, this will mean better image quality through the greater use of jittered sampling.
Meanwhile anti-aliasing performance overall received a significant speed boost. As with AMD, NVIDIA has gone ahead and tweaked their ROPs to reduce the performance hit of 8x MSAA, which on previous-generation GPUs could result in a massive performance drop. In this case NVIDIA has improved the compression efficiency in the ROPs to reduce the hit of 8x MSAA, and also cites the fact that having additional ROPs improves performance by allowing the hardware to better digest smaller primitives that can’t compress well.
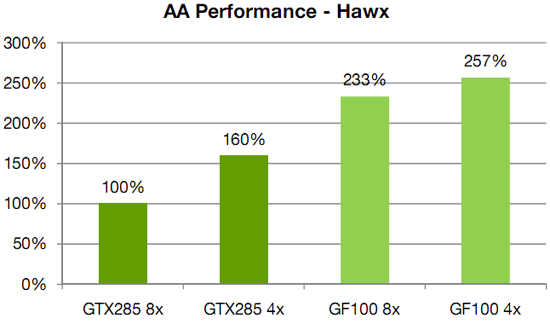
NVIDIA's HAWX data - not independently verified
This is something we’re certainly going to be testing once we have the hardware, although we’re still not sold on the idea that the quality improvement from 8x MSAA is worth any performance hit in most situations. There is one situation however where additional MSAA samples do make a stark difference, which we’ll get to next.








115 Comments
View All Comments
x86 64 - Sunday, January 31, 2010 - link
If we don't know these basic things then we don't know much.1. Die size
2. What cards will be made from the GF100
3. Clock speeds
4. Power usage (we only know that it’s more than GT200)
5. Pricing
6. Performance
Seems a pretty comprehensive list of important info to me.
nyran125 - Saturday, January 30, 2010 - link
You guys that buy a brand new graphics card every single year are crazy . im still running an 8800 GTS 512mb with no issues in any games whatso ever DX10, was a waste of money and everyones time. Im going to upgrade to the highest end of the GF100;s but thats from a 8800 GTS512mb so the upgrade is significant. Bit form a heigh end ati card to GF 100 ?!?!?!? what was the friggin point in even getting a 200 series card.!?!?!!?1/. Games are only just catching up to the 9000 series now.Olen Ahkcre - Friday, January 22, 2010 - link
I'll wait till they (TSMC) start using 28nm (from planned 40nm) fabrication process on Fermi... drop in size, power consumption and price and rise is clock speed will probably make it worth the wait.It'll be a nice addition to the GTX 295 I currently have. (Yeah, going SLI and PhysX).
Zingam - Wednesday, January 20, 2010 - link
Big deal... Until the next generation of Consoles - no games would take any advantage of these new techs. So? Why bother?zblackrider - Wednesday, January 20, 2010 - link
Why am I flooded with memories of the 20th Anniversary Macintosh?Zool - Wednesday, January 20, 2010 - link
Tesselation is quite resource hog on shaders. If u increase polygons by tenfold (quite easy even with basic levels of tesselation factor) the dissplacement map shaders needs to calculate tenfold more normals which ends in the much more detailed dissplacement of course. The main advatage of tesselation is that it dont need space in video memmory and also read(write ?) bandwith is on chip but it actualy acts as you would increase the polygons in game. Lightning, shadows and other geometry based efects should act as on high polygon models too i think (at least in uniengine heaven u have shadows after tesselation where before u didnt had a single shadow).Only the last stage of tesselator the domain shader produces actual vertices. The real question would be how much does this single(?) domain shader in radeons keep up with the 16 polymorph engines(each with its own tesselation engines) in gt300.
Thats 1(?) domain shader for 32 stream procesors in gt300(and much closer) against 1(?) for 320 5D units in radeon.
If u have too much shader programs that need the new vertices cordinations the radeon could end up being realy botlenecked.
Just my toughs.
Zool - Wednesday, January 20, 2010 - link
Of course ati-s tesselation engine and nvidias tesselation engine can be completly different fixed units. Ati-s tesselation engine is surely more robust than a single tesselation engine in nvidias 16 polymorph engines as its designed for the entire shaders.nubie - Tuesday, January 19, 2010 - link
They have been sitting on the technology since before the release of SLi.In fact SLi didn't have even 2-monitor support until recently, when it should have had 4-monitor support all along.
nVidia clearly didn't want to expend the resources on making the software for it until it was forced, as it now is by AMD heavily advertising their version.
If you look at some of their professional offerings with 4-monitor output it is clear that they have the technology, I am just glad they have acknowledged that it is a desire-able feature.
I certainly hope the mainstream cards get 3-monitor output, it will be nice to drive 3 displays. 3 Projectors is an excellent application, not only for high-def movies filmed in wider than 16:9 formats, but games as well. With projectors you don't get the monitor bezel in the way.
Enthusiast multi-monitor gaming goes back to the Quake II days, glad to see that the mainstream has finally caught up (I am sure the geeks have been pushing for it from inside the companies.)
wwwcd - Tuesday, January 19, 2010 - link
Maybe I'll live to see if Nvidia still wins AMD / Ati, a proposal which is as leadership price / performance, or even as productivity, regardless of price!:)AnnonymousCoward - Tuesday, January 19, 2010 - link
They should make a GT10000, in which the entire 300mm wafer is 1 die. 300B transistors. Unfortunately you have to mount the final thing to the outside of your case, and it runs off a 240V line.