GF100’s Gaming Architecture
Although it feels like ages ago, NVIDIA announced the Fermi architecture back in September of 2009, focusing on the compute abilities of the GPU that would be GF100. Today’s announcement is about filling in the blanks – where does the graphics hardware fit in to the design that NVIDIA revealed earlier.
As a quick refresher, the GF100 is composed of 512 SPs, which NVIDIA now calls CUDA cores. Each CUDA core is organized in to a block of 32 cores which we call a Streaming Multiprocessor (SM), which in turn are laid out so that 4 of them are in a Graphics Processing Cluster (GPC). Finally, there are 4 GPCs in a single GF100 chip. 32x4x4 = 512 CUDA cores.
| GF100 | GT200x2 (GTX 295) | GT200 (GTX 285) | G92 (9800+ GTX) | |
| Stream Processors | 512 | 2 x 240 | 240 | 128 |
| Texture Address / Filtering | 64/256 | 2 x 80 / 80 | 80 / 80 | 64 / 64 |
| ROPs | 48 | 2x 28 | 32 | 16 |
| Core Clock | ? | 576MHz | 648MHz | 738MHz |
| Shader Clock | ? | 1242MHz | 1476MHz | 1836MHz |
| Memory Clock | ? GDDR5 | 999MHz (1998MHz data rate) GDDR3 | 1242MHz (2484MHz data rate) GDDR3 | 1100MHz (2200MHz data rate) GDDR3 |
| Memory Bus Width | 384-bit | 2 x 448-bit | 512-bit | 256-bit |
| Frame Buffer | ? | 2 x 896MB | 1GB | 512MB |
| Transistor Count | 3B | 2 x 1.4B | 1.4B | 754M |
| Manufacturing Process | TSMC 40nm | TSMC 55nm | TSMC 55nm | TSMC 55nm |
| Price Point | $? | $500 | $400 | $150 - 200 |
When NVIDIA first unveiled GF100, we did not know anything about the ROPs, texture units, or any of the fixed-function graphics units that are customary in a GPU. Today we now have that information, and can discuss where it goes.
While GF100 resembles GT200 in a number of ways as a compute GPU, as a gaming GPU it’s very close to being a complete departure from GT200. The big change here is that the single block of fixed-function hardware as we know it is gone. Virtually every piece of hardware has been split up and moved down a level, and can now be found as part of a GPC or as a SM. NVIDIA’s GF100 block diagram does a good job of showing this.
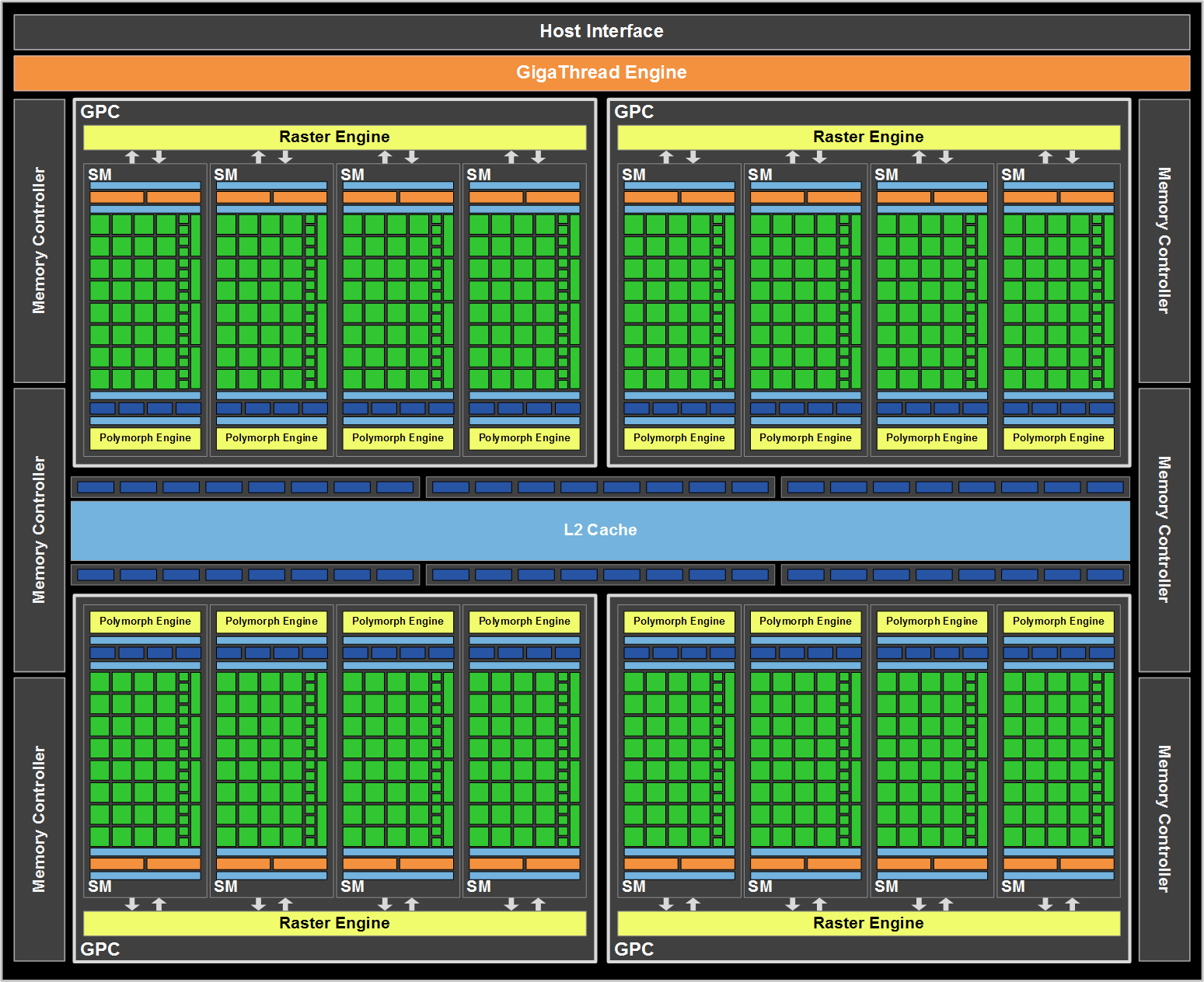
What’s left of the fixed function hardware is the GigaThread Engine, which is what NVIDIA is calling their scheduler. To understand where our fixed function hardware went, we must meet the newest execution units: The PolyMorph Engine and the Raster Engine.

We’ll start with the Raster Engine. The Raster Engine is the combination of all the raster related hardware that we would have found previously in the fixed function pipeline. It does edge/triangle setup, rasterization, and z-culling in a pipelined manner. Each GPC has its own Raster Engine. NVIDIA has very little to say about the Raster Engine, but very little has changed from GT200 besides the fact that there are now 4 of them (one for each GPC) as opposed to 1 larger block. Each rasterizer can do 8 pixels per clock, for a total of 32 pixels per clock over the entirety of GF100.
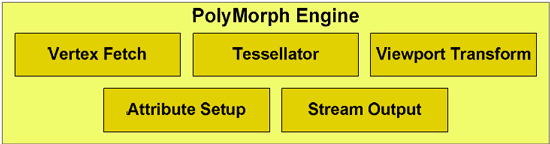
The much more important of the two new execution units is the PolyMorph Engine, which is what NVIDIA is calling the execution unit that handles geometry for GF100. The PolyMorph Engine is responsible for handling Vertex Fetch, Tessellation, Viewport Transform, Attribute Setup, and Stream Output. It’s here where the Tessellator is located, one of the biggest changes that DX11 is bringing to GPU design. Unlike the Raster Engine, each SM has a PolyMorph Engine, giving the GF100 16 PolyMorph Engines altogether.
While the PolyMoprh Engine may sound simple in its description, don’t let it fool you. NVIDIA didn’t just move their geometry hardware to a different place, clone it 15 times, and call it a day. This was previously fixed-function hardware where a single unit sat in a pipeline and did its share of the work. By splitting up the fixed-function pipeline like this, NVIDIA in actuality created a lot of work for themselves. Why? Out of order execution.
OoO is something we usually reserve for CPUs, where high-end CPUs are built to execute instructions out of order in order to extract more performance out of them through instruction level parallelism. OoO is very hard to accomplish, because you can only execute certain instructions ahead of other ones while maintaining the correct result for your data. Execute an add instruction that relies on a previous operation before that’s done, and you have problems. GF100 isn’t a full OoO design, so we’re not going to cover OoO in-depth here, but if you’d like to know more please see this article.
At any rate, internally each PolyMorph Engine is still a simple in-order design. NVIDIA hasn’t gone so far as to make a PolyMorph Engine an OoO design – but because there are 16 of them when there used to be just 1, OoO hazards can occur just as they would in an OoO executing CPU. NVIDIA now has to keep track of what each PolyMorph Engine is doing in respect to the other 15, and put the brakes on any of them that get too far ahead in order to maintain the integrity of results.
To resolve the hazards of OoO, GF100 has a private communication channel just for the PolyMorph Engines that allows them to stay together on a task in spite of being spread apart. The fact of the matter is that all of the work that goes in to making a design like this work correctly is an immense amount of effort, and NVIDIA’s engineers are quite proud of this effort. They have taken the monolithic design of prior GPUs’ geometry units, and made it parallel. We can’t overstate how much of an engineering challenge this is.
However all of this work came at a cost, and not just the significant engineering resources NVIDIA threw at GF100. The other cost was time – we believe that the PolyMorph Engine is the single biggest reason that GF100 didn’t make it out last year. It’s the single biggest redesign of any component in GF100, and is something that NVIDIA had to start virtually from scratch on. When NVIDIA told us that designing a big GPU is hard, this is what they had in mind.
Now why did NVIDIA put themselves through all of this? Because in their eyes, they had to. The use of a fixed-function pipeline in their eyes was a poor choice given the geometric complexity that a tessellator would create, and hence the entire pipeline needed to be rebalanced. By moving to the parallel design of the PolyMorph Engine, NVIDIA’s geometry hardware is no longer bound by any limits of the pipelined fixed-function design (such as bottlenecks in one stage of the pipeline), and for better or for worse, they can scale their geometry and raster abilities with the size of the chip. A smaller GF100 derivative will not have as many PolyMorph or Raster units as GF100, and as a result won’t have the same level of performance; G92 derivatives and AMD’s designs both maintain the same fixed function pipeline through all chips, always offering the same level of performance.

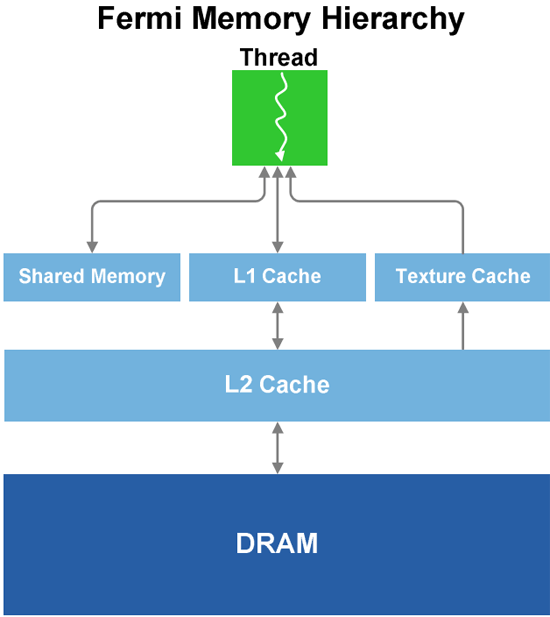
Speaking of performance, we’ll get to that in a bit, but for now we’ll finish our discussion of GF100’s graphics units. Each SM has 4 texture units, which have changes somewhat from the GT200. In GT200, the texture units were at the TPC level; here they are per SM. The texture units are also affected by the cache reorganization of GF100; for L1 cache they still have the same 12KB of texture cache per set of 4 texture units, while they all share GF100’s 768KB L2 cache, which is now used by all execution units and not just textures. Each unit can compute 1 texture address and fetch 4 texture samples per clock, a significantly higher texture fetch rate than on the GT200. Furthermore in conjunction with DX11, NVIDIA’s texture units now support DX11’s new compressed texture formats. Finally, texture units are now tied to the shader clock and not the core clock. They run at 1/2 the shader clock speed of GF100.
Last but not least, this brings us to the ROPs. The ROPs have been reorganized, there are now 48 of them in 6 parttions of 8, and a 64bit memory channel serving each partition. The ROPs now share the L2 cache with the rest of GF100, while under GT200 they had their own L2 cache. Each ROP can do 1 regular 32bit pixel per clock, 1 FP16 pixel over 2 clocks, or 1 FP32 pixel over 4 clocks, giving the GF100 the ability to retire 48 regular pixels per clock. The ROPs are clocked together with the L2 cache.
That leaves us on a final note: clocks. The core clock has been virtually done away with on GF100, as almost every unit now operates at or on a fraction of the shader clock. Only the ROPs and L2 cache operate on a different clock, which is best described as what’s left of the core clock. The shader clock now drives the majority of the chip, including the shaders, the texture units, and the new PolyMorph and Raster Engines. Specifically, the texture units, PolyMorph Engine, and Raster Engine all run at 1/2 shader clock (which NVIDIA is tentatively calling the "GPC Clock"), while the L1 cache and the shaders themselves run at the full shader clock. Don’t be surprised if GF100 overclocking is different from GT200 overclocking as a result.








115 Comments
View All Comments
x86 64 - Sunday, January 31, 2010 - link
If we don't know these basic things then we don't know much.1. Die size
2. What cards will be made from the GF100
3. Clock speeds
4. Power usage (we only know that it’s more than GT200)
5. Pricing
6. Performance
Seems a pretty comprehensive list of important info to me.
nyran125 - Saturday, January 30, 2010 - link
You guys that buy a brand new graphics card every single year are crazy . im still running an 8800 GTS 512mb with no issues in any games whatso ever DX10, was a waste of money and everyones time. Im going to upgrade to the highest end of the GF100;s but thats from a 8800 GTS512mb so the upgrade is significant. Bit form a heigh end ati card to GF 100 ?!?!?!? what was the friggin point in even getting a 200 series card.!?!?!!?1/. Games are only just catching up to the 9000 series now.Olen Ahkcre - Friday, January 22, 2010 - link
I'll wait till they (TSMC) start using 28nm (from planned 40nm) fabrication process on Fermi... drop in size, power consumption and price and rise is clock speed will probably make it worth the wait.It'll be a nice addition to the GTX 295 I currently have. (Yeah, going SLI and PhysX).
Zingam - Wednesday, January 20, 2010 - link
Big deal... Until the next generation of Consoles - no games would take any advantage of these new techs. So? Why bother?zblackrider - Wednesday, January 20, 2010 - link
Why am I flooded with memories of the 20th Anniversary Macintosh?Zool - Wednesday, January 20, 2010 - link
Tesselation is quite resource hog on shaders. If u increase polygons by tenfold (quite easy even with basic levels of tesselation factor) the dissplacement map shaders needs to calculate tenfold more normals which ends in the much more detailed dissplacement of course. The main advatage of tesselation is that it dont need space in video memmory and also read(write ?) bandwith is on chip but it actualy acts as you would increase the polygons in game. Lightning, shadows and other geometry based efects should act as on high polygon models too i think (at least in uniengine heaven u have shadows after tesselation where before u didnt had a single shadow).Only the last stage of tesselator the domain shader produces actual vertices. The real question would be how much does this single(?) domain shader in radeons keep up with the 16 polymorph engines(each with its own tesselation engines) in gt300.
Thats 1(?) domain shader for 32 stream procesors in gt300(and much closer) against 1(?) for 320 5D units in radeon.
If u have too much shader programs that need the new vertices cordinations the radeon could end up being realy botlenecked.
Just my toughs.
Zool - Wednesday, January 20, 2010 - link
Of course ati-s tesselation engine and nvidias tesselation engine can be completly different fixed units. Ati-s tesselation engine is surely more robust than a single tesselation engine in nvidias 16 polymorph engines as its designed for the entire shaders.nubie - Tuesday, January 19, 2010 - link
They have been sitting on the technology since before the release of SLi.In fact SLi didn't have even 2-monitor support until recently, when it should have had 4-monitor support all along.
nVidia clearly didn't want to expend the resources on making the software for it until it was forced, as it now is by AMD heavily advertising their version.
If you look at some of their professional offerings with 4-monitor output it is clear that they have the technology, I am just glad they have acknowledged that it is a desire-able feature.
I certainly hope the mainstream cards get 3-monitor output, it will be nice to drive 3 displays. 3 Projectors is an excellent application, not only for high-def movies filmed in wider than 16:9 formats, but games as well. With projectors you don't get the monitor bezel in the way.
Enthusiast multi-monitor gaming goes back to the Quake II days, glad to see that the mainstream has finally caught up (I am sure the geeks have been pushing for it from inside the companies.)
wwwcd - Tuesday, January 19, 2010 - link
Maybe I'll live to see if Nvidia still wins AMD / Ati, a proposal which is as leadership price / performance, or even as productivity, regardless of price!:)AnnonymousCoward - Tuesday, January 19, 2010 - link
They should make a GT10000, in which the entire 300mm wafer is 1 die. 300B transistors. Unfortunately you have to mount the final thing to the outside of your case, and it runs off a 240V line.