A New SSE Instruction Set: AMD Announces SSE5
by Ryan Smith on August 30, 2007 4:00 PM EST- Posted in
- CPUs
So what's so important about being able to use 3+ operands? In a word: MADD, Multiply-ADDition operations (aka multiply-accumulate/MAC), such as C=(A*B)+C. Matrix math is the cornerstone of data processing and image rendering, and one of the cornerstone operations in manipulating a matrix is multiplying two elements and adding them to a third, which would require 3 operands. Modern GPUs are MADD powerhouses, with their stream processors capable of processing a mind-boggling number of such instructions in a short period of time; being fast at MADD is one of the specialized tasks that makes a GPU so fast at its job.
Meanwhile x86 processors have no real MADD abilities, so any time a CPU is doing the kind of image manipulation work that would benefit from MADD, instead it is executing separate multiply and addition instructions (and sometimes more). It should come as no surprise that AMD's favorite/most-publicized part of SSE5 then are instructions using 3+ operands since fusing two instructions in to one can theoretically double performance in certain situations. Furthermore using such instructions can cut down on the number of register load/store operations needed, which can save yet more time.
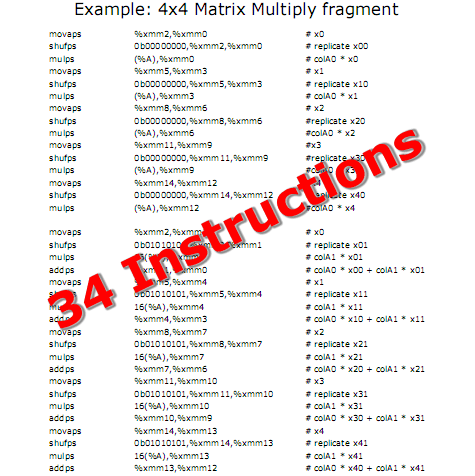
AMD has provided us with an example of such a situation, with the code for a 4x4 matrix multiplication operation, one coded optimally in SSE3, the other optimized via SSE5. The SSE3 code requires 34 instructions, meanwhile the SSE5 code does it in 20. Now there is more to the performance of such a code segment than the number of instructions (so this example isn't necessarily 41% faster) since the time to execute and retire an instruction can vary depending on the instruction, but it doesn't negate the performance improvement offered by such code.

For actual performance numbers with SSE5, AMD has told us that they've found that a discrete cosine transform - an operation important for image and movie encoding - can be done 30% faster using SSE5 than SSE3. They have even more impressive numbers for encryption processing, with a 5x performance improvement possible on certain encryption tasks, although we suspect this case is more limited than their image encoding scenario. Either way the promise of other performance improvements is there, however this is going to heavily depend on how well programmers will be able to extract additional performance out of SSE5, and how good AMD's own optimized math libraries will be once those are released.
This also isn't taking in to significant account instructions that are not part of the MADD/MAC set. All of AMD's examples today deal with improvements due to those instructions, meanwhile we don't have a lot of information on the performance aspects of the permutation, vector, or precision instructions. We have no doubt that they'll be similarly useful, we just don't know to what degree at this point.
Finally, as we're always watching how the predicted merging of CPUs and GPUs is progressing, this is a notable time. Although AMD is not targeting GPUs specifically with SSE5, as we mentioned before GPUs are particularly fast at MADD operations and meanwhile SSE5 is providing CPUs a shot in the arm in that area. This won't kill (or even significantly maim) the GPU, but it is one less thing that the GPU advantage is shrinking in. As SSE iterations keep coming out and implementing features similar to DSPs and GPUs, they will keep chipping away at their side of the barrier between the CPU and the GPU until very little is left and the two become one.








17 Comments
View All Comments
skiboysteve - Friday, August 31, 2007 - link
this is stupid. they are adding SSE5 before SSE4. wow.tygrus - Friday, August 31, 2007 - link
SSE numbers/description becoming like model numbers. Confusing and virtually meaningless. Need CPU core with microcode to convert non-native SSE? instructions into sequence of native instuctions (micro-ops/macro-ops).If that doesn't happen then the compilers may need to re-write the code sequences for target(s) at compile time or execution.
yyrkoon - Thursday, August 30, 2007 - link
Just from what I have seen in the past, whenever AMD does something like this, Intel tries to seperate themselves by going a different direction, this is why I think Intel will rename their future instruction sets to something else.If AMD and Intel were to actually work together on this, then maybe Intel would opt in on some of the better portions of the instruction set that enhanced their CPUs, but somehow I do not think this is the case.
I watch the Intel/AMD 'rivalry' from the outside looking in, and I see the Coke/Pepsi 'war' all over again. Little kids going so far as to pull an engine out of a new delivery truck, paint it another color other than blue, because that *is* their rivals colors . . . At what cost for your share holders ? Nonesense !
jeromekwok - Thursday, August 30, 2007 - link
I don't think of a good reason we should care this SSE5A, or should we call it 3dnow technically. AMD may gain back a few benchmark scores, but it is hard to get developers move from Intel compiler suites.Do you guys feel the same. When the MADD goes thru the OOO, it should be decoded as MUL and ADD micro-ops. There should not be a big difference if we use two instructions MUL and ADD, which should get similar micro-ops. May be there is something AMD is weak at.
saratoga - Thursday, August 30, 2007 - link
Since muls have a very high latency compared to adds, and a dependency would exist between the ops, this would not be a good way to do things.
The result is the same (obviously), but its slower and complicates scheduling for no logical reason. Compared to a multiplier, adders are very cheap.
redpriest_ - Thursday, August 30, 2007 - link
Look at Itanium's fused multiply add.jiulemoigt - Thursday, August 30, 2007 - link
Well I wrote several versions but what it comes down to is I'm scratching my at the example as it looks like it was written by marketing without asking an engineer how to code it. The first can be written in half that many lines of code and more efficiently, it looks like vb code that was automatically translated by a very bad compiler. I've written code for both chips and generally hand coding will give code than four about four times faster but is not practical considering time constraints and the number of people that can write assembler code. Yet using instructions is supposed to speed up the rate code goes because the computer performs a series of instructions that have predefined procedures ie store data in A, store data in B, ADD A to B, repeat C times, return B, where as this looks like store data in A, store data in B, Add A,B store in C, return C, repeat with new numbers multiple times, go back and get data returned from C and store in A compare to data from pass two stored in B store result in C return C, get data just returned compare to data from pass three, store in C return C, get data just returned etc... with the second one using the location but still using a third location! Instead of ADD a,b with the result in B, return B to location 1, return B to loc2, then store loc 1 in A, loc 2 in B ADD A,B return B.The interesting thing about the number of instructions in the example is that the time it takes to one instruction to complete is far different, as store statements are not equal to compare statements are not equal to ADD/MUL statements, the computer can do an ADD statement faster than it can find data on local cache let alone system memory. One of the reason graphic cards are so much faster at MADD tends to do with the data being right there, which is why graphic DRR is so much more expensive than system memory. and now AMD wants to join the slowest instruction with the fast ones? This is something people should be really wondering about since it kills prefetch as it is going to make the system wait for data with every pass including the ones that should be really fast. That suggests they are going to try and force the scheduler to get longer blocks of data like Intel did with its P4 which was a very bad design since branching logic is only so good, and every miss will cause the CPU to sit ideal, covering up misses with longer cycles.
Any way for the non-coders SSE takes low level code and packages chunks of code that can be pasted to the CPU as one chunk it knows what to do with. Usually this makes the chunks get processed faster as scheduler on the CPU takes the chunks as one piece and it all gets pushed through no waiting, only in this case it is forcing the CPU to be an in-order CPU for every instruction so coded, which is bad because normally it can crank through fast instructions ideal through slow ones, this will force it to ideal through many slow ones, as opposed to simply burning through the fast short ones, less ideal time fast the job gets done, but with everything waiting on store statements there will be an increase in ideal time, since it is easier to stack a bunch of small legos in a box than four bowling balls. Just think of store statements as getting the legos or the bowling balls to put in the box you may have to make more trips to get enough legos to fill the box but the trips are faster and if you get two many legos the amount that does not fit will be small where as that last bowling balls is a significant amount compared to what is in the box. Rough analogy but I'm supposed to be relaxing not thinking about work.
Oh and MMX when it first came out was a PR stunt and it was only about two years after being added that someone found a use for it, as kludge to simply coding for people who were not willing to do it right. 3DNow was just as bad SSE was the first set that was actually useful, when added to compiler to speed up certain repetitive tasks like encoding and rendering. Though this new set defeats the purpose of having all those new registers to use!
PeteRoy - Thursday, August 30, 2007 - link
Return of the Jedi anyone?her34 - Thursday, August 30, 2007 - link
next for amd:the geforce 10800xt
peldor - Thursday, August 30, 2007 - link
This strikes me as a way to distract from the lack of a complete SSE4 implementation.