ATI Radeon HD 2900 XT: Calling a Spade a Spade
by Derek Wilson on May 14, 2007 12:04 PM EST- Posted in
- GPUs
Memory and Data Movement
Internal cache bandwidth on the R600 is 180GB/sec, while the internal memory bus, a second generation Ring Bus that builds on the X1k series idea, is able to deliver 100GB/sec of throughput in either read or write capacity. Memory offers nearly 110GB/sec, and AMD has stated that the internal bus is well matched to this due to the fact that some external bandwidth is wasted on overhead. The bottom line here is that a whole of data can move very quickly into and out of this hardware.
As we mentioned, R600 sees a reincarnation of the Ring Bus which can now handle both read and write data (X1k could only handle reads on the Ring Bus while writes were run through a crossbar). An independent DMA controller manages a bus comprised of multiple ring stops. There is one ring stop per pair of memory channels, and each ring stop is connected to two others via a 256 bit wide connection. The ring bus is 1024 wires total and can move read and write data in either direction to follow the shortest path around the ring to or from the memory client or memory.
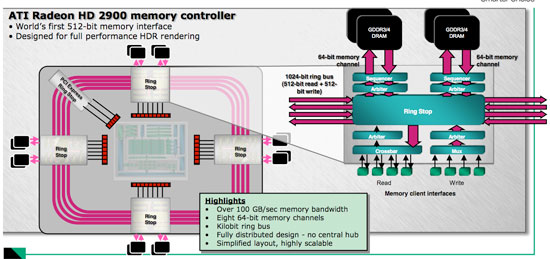
The Ring Bus allows the PCI Express bus to be treated like just another memory device by the rest of the hardware. The DMA hardware is able to manage all the traffic to and from onboard and system memory in the same manner, and the memory clients on the GPU don't need to know what device they're talking to. The Ring Bus services 84 read clients and 70 write clients.
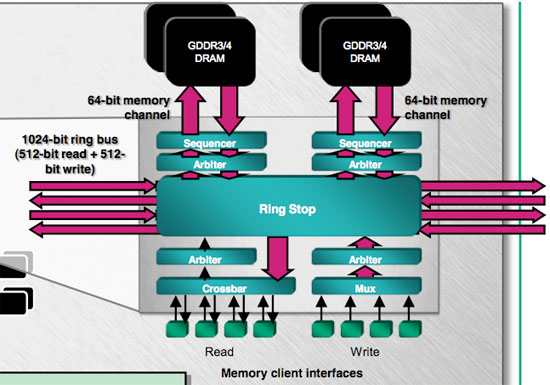
The external memory interface is 512-bit, doubling the X1k maximum of 256-bit and surpassing G80's 384-bit memory bus. Memory speeds are lower than on previous generation high end AMD hardware, but total bandwidth is higher. The net result is that AMD only slightly edges out G80 for memory bandwidth.
In implementing the 512-bit memory interface, AMD didn't want to add any more I/O pads to its package. They accomplished this by making use of a stacked I/O pad design. Unfortunately, details were vague on the implementation and methods used to keep clock speed high in spite of the proximity of other high frequency I/O.








86 Comments
View All Comments
wjmbsd - Monday, July 2, 2007 - link
What is the latest on the so-called Dragonhead 2 project (aka, HD 2900 XTX)? I heard it was just for OEMs at first...anyone know if the project is still going and how the part is benchmarking with newest drivers?teainthesahara - Monday, May 21, 2007 - link
After this failure of the R600 and likely overrated(and probably late) Barcelona/Agena processors I think that Intel will finally bury AMD. Paul Ottelini is rubbing his hands with glee at the moment and rightfully so. AMD now stands for mediocrity.Oh dear what a fall from grace.... To be honest Nvidia don't have any real competition on the DX10 front at any price points.I cannot see AMD processors besting Intel's Core 2 Quad lineup in the future especially when 45nm and 32 nm become the norm and they don't have a chance in hell of beating Nvidia. Intel and Nvidia are turning the screws on Hector Ruiz.Shame AMD brought down such a great company like ATI.DerekWilson - Thursday, May 24, 2007 - link
To be fair, we really don't have any clue how these cards compete on the DX10 front as there are no final, real DX10 games on the market to test.We will try really hard to get a good idea of what DX10 will look like on the HD 2000 series and the GeForce 8 Series using game demos, pre-release code, and SDK samples. It won't be a real reflection of what users will experience, but we will certainly hope to get a glimpse at performance.
It is fair to say that NVIDIA bests AMD in current game performance. But really there are so many possibilities with DX10 that we can't call it yet.
spinportal - Friday, May 18, 2007 - link
From the last posting of results for the GTS 320MB round-uphttp://www.anandtech.com/video/showdoc.aspx?i=2953...">Prey @ AnandTech - 8800GTS320
we see that the 2900XT review chart pushes the nVidia cards down about 15% across the board.
http://www.anandtech.com/video/showdoc.aspx?i=2988...">Prey @ AnandTech - ATI2900XT
The only difference in systems is software drivers as the cpu / mobo / mem are the same.
Does this mean ATI should be getting a BIGGER THRASHING BEAT-DOWN than the reviewer is stating?
400$ ATI 2900XT performing as good as a 300$ nVidia 8800 GTS 320MB?
Its 100$ short and 6 months late along with 100W of extra fuel.
This is not your uncle's 9700 Pro...
DerekWilson - Sunday, May 20, 2007 - link
We switched Prey demos -- I updated our benchmark.Both numbers are accurate for the tests I ran at the time.
Our current timedemo is more stressful and thus we see lower scores with this test.
Yawgm0th - Wednesday, May 16, 2007 - link
The prices listed in this article are way off.Currently, 8800GTS 640MB retails for $350-380, $400+ for OC or special versions. 2900XT retails for $430+. In the article, both are listed as $400, and as such the card is given a decent review in the conclusion.
Realistically, this card provides slightly inferior performance to the 8800GTS 640MB at a considerably higher price point -- $80-$100 more than the 8800GTS. I mean, it's not like the 8800Ultra, but for the most part this card has little use outside of AMD and/or ATI fanboys. I'd love for this card to do better as AMD needs to be competing with Nvidia and Intel right now, but I just can't see how this is even worth looking at, given current prices.
DerekWilson - Thursday, May 17, 2007 - link
really, this article focuses on architechture more than product, and we went with MSRP prices...we will absolutly look closer at price and price/performance when we review retail products.
quanta - Tuesday, May 15, 2007 - link
As I recalled, the Radeon HD 2900 only has DVI ports, but nowhere in DVI documentation specifies it can carry audio signals. Unless the card comes with adapter that accepts audio input, it seems the audio portion of R600 is rendered useless.DerekWilson - Wednesday, May 16, 2007 - link
the card does come with an adapter of sorts, but the audio input is from the dvi port.you can't use a standard DVI to HDMI converter for this task.
when using AMD's HDMI converter the data sent out over the DVI port does not follow the DVI specification.
the bottom line is that the DVI port is just a physical connector carrying data. i could take a DVI port and solder it to a stereo and use it to carry 5.1 audio if I wanted to ... wouldn't be very useful, but I could do it :-)
While connected to a DVI device, the card operates the port according to the DVI specification. When connected to an HDMI device through the special converter (which is not technically "dvi to hdmi" -- it's amd proprietry to hdmi), the card sends out data that follows the HDMI spec.
you can look at it another way -- when the HDMI converter is connected, just think of the dvi port as an internal connector between an I/O port and the TMDS + audio device.
ShaunO - Tuesday, May 15, 2007 - link
I was at an AMD movie night last night where they discussed the technical details of the HD 2900 XT and also showed the Ruby Whiteout DX10 Demo rendered using the card. It looked amazing and I had high hopes until I checked out the benchmark scores. They're going to need more than free food and popcorn to convince me to buy an obsolete card.However there is room for improvement of course. Driver updates, DX10 and whatnot. The main thing for me personally will be driver updates, I will be interested to see how well the card improves over time while I save my pennies for my next new machine.
Everyone keeps saying "DX10 performance will be better, yadda yadda" but I also want to be able to play the games I have now and older games without having to rely on DX10 games to give me better performance. Nothing like totally underperforming in DX9 games and then only being equal or slightly better in DX10 games compared to the competition. I would rather have a decent performer all-round. Even saying that we don't even know for sure if DX10 games are even going to bring any performance increases of the competition, it's all speculation right now and that's all we can do, speculate.
Shaun.