The GPU Advances: ATI's Stream Processing & Folding@Home
by Ryan Smith on September 30, 2006 8:00 PM EST- Posted in
- GPUs
Folding@Home
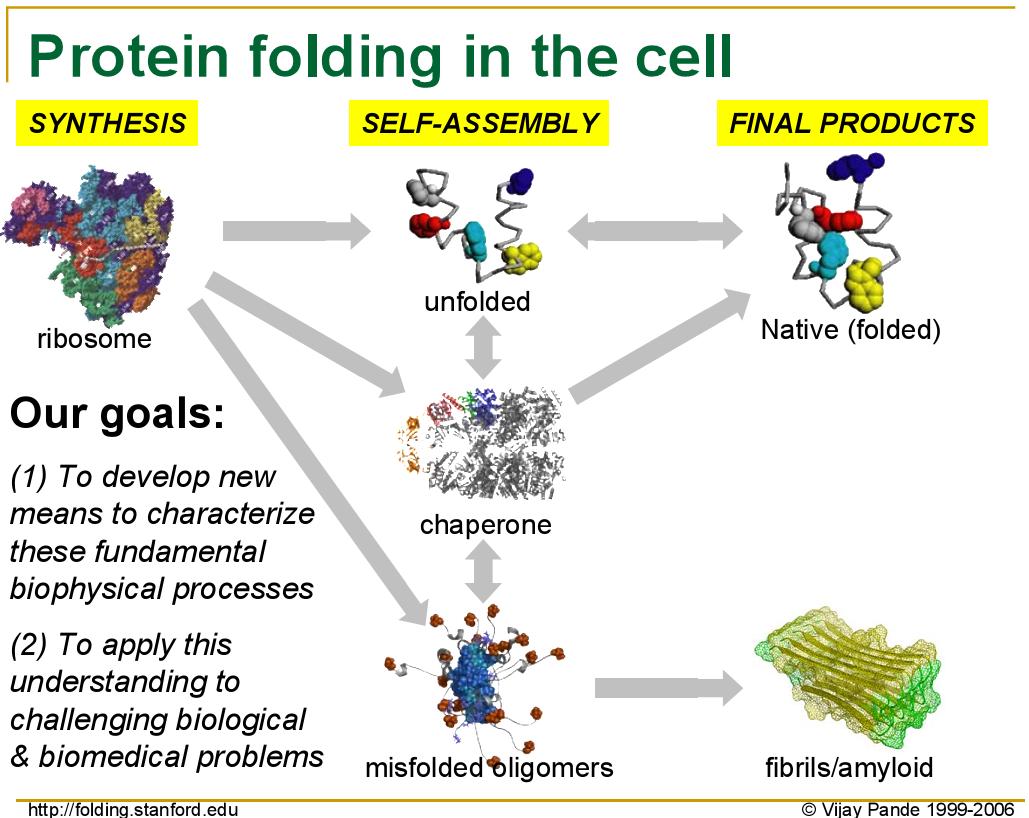
For several years now, Dr. Vijay Pande of Stanford has been leading the Folding@Home project in order to research protein folding. Without diving unnecessarily into the biology of his research, as proteins are produced from their basic building blocks - amino acids - they must go through a folding process to achieve the right shape to perform their intended function. However, for numerous reasons protein folding can go wrong, and when it does it can cause various diseases as malformed proteins wreck havoc in the body.
Although Folding@Home's research involves multiple diseases, the primary disease they are focusing on at this point is Alzheimer's Disease, a brain-wasting condition affecting primarily older people where they slowly lose the ability to remember things and think clearly, eventually leading to death. As Alzheimer's is caused by malformed proteins impairing normal brain functions, understanding how exactly Alzheimer's occurs - and more importantly how to prevent and cure it - requires a better understanding on how proteins fold, why they fold incorrectly, and why malformed proteins cause even more proteins to fold incorrectly.
The biggest hurdle in this line of research is that it's very computing intensive: a single calculation can take 1 million days (that's over 2700 years) on a fast CPU. Coupled with this is the need to run multiple calculations in order to simulate the entire folding process, which can take upwards of several seconds. Even splitting this load among processors in a supercomputer, the process is still too computing intensive to complete in any reasonable amount of time; a processor will simulate 1 nanosecond of folding per day, and even if all grant money given out by the United States government was put towards buying supercomputers, it wouldn't even come close to being enough.
This is where the "@Home" portion of Folding@Home comes in. Needing even more computing power than they could hope to buy, the Folding@Home research team decided to try to spread processing to computers all throughout the world, in a process called distributed computing. Their hopes were that average computer users would be willing to donate spare/unused processor cycles to the Folding@Home project by running the Folding@Home client, which would grab small pieces of data from their central servers and return it upon completion.
The call for help was successful, as computer owners were more than willing to donate computer cycles to help with this research, and hopefully help in coming up with a way to cure diseases like Alzheimer's. Entire teams formed in a race to see who could get more processing done, including our own Team AnandTech, and the combined power of over two-hundred thousand CPUs resulted in the Folding@Home project netting over 200 Teraflops (one trillion Floating-point Operations Per Second) of sustained performance.
While this was a good enough start to do research, it was still ultimately falling short of the kind of power the Folding@Home research group needed to do the kind of long-runs they needed along side short-run research that the Folding@Home community could do. Additionally, as processors have recently hit a cap in terms of total speed in megahertz, AMD and Intel have been moving to multiple-core designs, which introduce scaling problems for the Folding@Home design and is not as effective as increasing clockspeeds.
Since CPUs were not growing at speeds satisfactory for the Folding@Home research group, and they were still well short of their goal in processing power, the focus has since returned to stream processors, and in turn GPUs. As we mentioned previously, the massive floating-point power of a GPU is well geared towards doing research work, and in the case of Folding@Home, they excel in exactly the kind of processing the project requires. To get more computing power, Folding@Home has now turned towards utilizing the power of the GPU.
For several years now, Dr. Vijay Pande of Stanford has been leading the Folding@Home project in order to research protein folding. Without diving unnecessarily into the biology of his research, as proteins are produced from their basic building blocks - amino acids - they must go through a folding process to achieve the right shape to perform their intended function. However, for numerous reasons protein folding can go wrong, and when it does it can cause various diseases as malformed proteins wreck havoc in the body.
 |
| Click to enlarge |
Although Folding@Home's research involves multiple diseases, the primary disease they are focusing on at this point is Alzheimer's Disease, a brain-wasting condition affecting primarily older people where they slowly lose the ability to remember things and think clearly, eventually leading to death. As Alzheimer's is caused by malformed proteins impairing normal brain functions, understanding how exactly Alzheimer's occurs - and more importantly how to prevent and cure it - requires a better understanding on how proteins fold, why they fold incorrectly, and why malformed proteins cause even more proteins to fold incorrectly.
The biggest hurdle in this line of research is that it's very computing intensive: a single calculation can take 1 million days (that's over 2700 years) on a fast CPU. Coupled with this is the need to run multiple calculations in order to simulate the entire folding process, which can take upwards of several seconds. Even splitting this load among processors in a supercomputer, the process is still too computing intensive to complete in any reasonable amount of time; a processor will simulate 1 nanosecond of folding per day, and even if all grant money given out by the United States government was put towards buying supercomputers, it wouldn't even come close to being enough.
This is where the "@Home" portion of Folding@Home comes in. Needing even more computing power than they could hope to buy, the Folding@Home research team decided to try to spread processing to computers all throughout the world, in a process called distributed computing. Their hopes were that average computer users would be willing to donate spare/unused processor cycles to the Folding@Home project by running the Folding@Home client, which would grab small pieces of data from their central servers and return it upon completion.
The call for help was successful, as computer owners were more than willing to donate computer cycles to help with this research, and hopefully help in coming up with a way to cure diseases like Alzheimer's. Entire teams formed in a race to see who could get more processing done, including our own Team AnandTech, and the combined power of over two-hundred thousand CPUs resulted in the Folding@Home project netting over 200 Teraflops (one trillion Floating-point Operations Per Second) of sustained performance.
While this was a good enough start to do research, it was still ultimately falling short of the kind of power the Folding@Home research group needed to do the kind of long-runs they needed along side short-run research that the Folding@Home community could do. Additionally, as processors have recently hit a cap in terms of total speed in megahertz, AMD and Intel have been moving to multiple-core designs, which introduce scaling problems for the Folding@Home design and is not as effective as increasing clockspeeds.
Since CPUs were not growing at speeds satisfactory for the Folding@Home research group, and they were still well short of their goal in processing power, the focus has since returned to stream processors, and in turn GPUs. As we mentioned previously, the massive floating-point power of a GPU is well geared towards doing research work, and in the case of Folding@Home, they excel in exactly the kind of processing the project requires. To get more computing power, Folding@Home has now turned towards utilizing the power of the GPU.








43 Comments
View All Comments
BikeAR - Monday, October 2, 2006 - link
I may be living in a vacuum these days, but did anyone notice the following comment on theF@D site, "Help" page?...
Intel has been helping support our project(Stanford/Intel Alzheimer's Research Program), but has announced that it is ending their contribution to distributed computing in general and no longer supports any distributed computing clients, including F@H.
What is up with this?
Staples - Monday, October 2, 2006 - link
I'd love to know how a fully loaded X1900 folding would be compared to an E6600 Core 2 Duo? These GPUs have always been said to be 100s of times faster than CPUs at what they are designed to do so I'd love to see if it is really true or not. If not, it looks like we may have been lied to for so so many years.Ryan Smith - Monday, October 2, 2006 - link
Unfortunately it looks like they'll be using larger units. We thought we'd be able to use the same units for both the normal and GPU-accelerated clients, but this appears to not be the case. There's no direct way to compare the clients then, the closest we could get is comparing the number of points given for a work unit.peternelson - Sunday, October 1, 2006 - link
"So far, the only types of programs that have effectively tapped this power other than applications and games requiring 3D rendering have also been video related, such as video decoders, encoders, and video effect processors. In short, the GPU has been underutilized, as there are many tasks that are floating-point hungry while not visual in nature, and these programs have not used the GPU to any large degree so far."Erm, not so! Try looking at GPGPU.org
Also see the books GPU Gems and GPU Gems 2.
mostlyprudent - Sunday, October 1, 2006 - link
BTW, a type-o in the 1st paragraph of the article: "...manipulate data in ways that goes far beyond" -- should read "in ways that GO far beyond..".I knew about SETI, but was completely unaware of F@H. Thanks. I will look to get involved!
imaheadcase - Sunday, October 1, 2006 - link
Did anandtech just post a article on the weekend when most PC users are at home so they can read it? Amazing! :PCupCak3 - Sunday, October 1, 2006 - link
When loading the client, our team number is 198. :)If anyone has any questions and/or would like to join the TeAm, come and visit us http://forums.anandtech.com/categories.aspx?catid=...">here. We have many people which would be more than happy to answer any question.
I'll try to answer some of the questions and comments which have been posted thus far:
NVIDIA support may come later. This is a BETA right now so only a small number of devices will be supported. The supported ATI line will expand and when NVIDIA gets the kinks worked out on using GPGPU processing for their cards, I"m sure the Pande group would be glad to them up :)
No one knows about Crossfire support yet. We'll know more about this tomorrow.
Same goes for using CPU + GPU.
Scalability: A multithreaded client I've heard is in the works but I'm sure its on hiatus with the GPU client coming into BETA.
That is correct in saying for each core, a separate folding@home client must be loaded. Right now the max amount of RAM one core will use is between 100 and 120 megs of RAM. Other workunits utilize around 5 or 10 megs. The client will only load workunits with this amount of RAM usage if you have the resources to spare. (so not just having 1 256 meg stick in your XP box and then using 110 megs of that for folding) We still yet do not know the RAM requirements for the vid cards.
The Pande Group has posted that 1600 and 1800 series cards will be the next ones supported :) (if all goes well of course)
Linux and Max OSX client is also available for those wondering.
I hope this helps!
Messire - Sunday, October 1, 2006 - link
Hi folksIt is surprising to me that this Stanford project works only on the most modern and powerful ATI GPUs, because i know of an another Stanford project called BrookGPU. Here is the URL: http://graphics.stanford.edu/projects/brookgpu/">http://graphics.stanford.edu/projects/brookgpu/
It is only in beta now and seems to be abandoned a little bit, but they've made a very usable GENERAL PURPOSE streaming programming language wich works on much more older GPUs as well. And it is very fast...
Messire
lopri - Sunday, October 1, 2006 - link
I know this question is somewhat off the discussion at the moment, but I can't help but ask. Would this crank up the GPU usage to 100% as it does to CPU? All the time? Then it could be a problem for average users, because the X1900 is hot as it is even in idle.GhandiInstinct - Sunday, October 1, 2006 - link
Don't get me wrong, I'd love to contribute, as I have with SETI, but what evidence is there that this will help anything or even at all?I mean we've had super computers working in science for a while now and I haven't heard of any major breakthroughs because of it, and if my computer is going to exhaust a little extra heat I want some numbers to crunch before I do so.
That's all.