The Quest for More Processing Power, Part Three: "Multi core of Intel and AMD compared"
by Johan De Gelas on May 18, 2005 3:15 PM EST- Posted in
- CPUs
Dual core Opteron versus Pentium-D and Dempsey
There is no doubt that the Dual core Opteron architecture is more advanced and elegant than the Pentium-D and even future Netburst based dual cores such as Dempsey (Xeon). The Pentium-D Dual core is more a way of packaging than an actual architecture: two cores cut out the wafer together, and communicate via an external FSB.With two different L1 and L2-caches, and two CPUs working on the same variables, you risk that one of the CPUs is working on an outdated cached value. You need to make sure that if variable A is cached on both CPUs, and CPU 1 changes the value of variable A, then CPU 2 knows about it. This happens with a protocol called MESI on the Intel CPUs and MOESI on the AMD CPUs. The discussion of these “cache coherency protocols” is outside the scope of this article, but you understand that the more variables that are shared between the two CPUs, the more communication that will happen between the caches of the different CPUs.
In the case of the Pentium-D, the caches talk to each other (to keep cache consistency) via a shared 800 MHz bus, just like two single core SMP Xeons. Not only is 800 MHz relatively slow compared to the CPU (3200 MHz), but exchanging information via a bus also increases latency and lowers bandwidth. Latency is increased as the bus may not always be free - one of the CPUs might be using it to transfer data to or from the memory. This half duplex bus can only transmit signals of one device (CPU 1, CPU 2, chipset) at a given moment. Bandwidth is decreased as the cache coherency exchanges need a small amount of time on the bus too.
Enter the elegant dual core Opteron architecture. Each core in the Dual Opteron/Athlon 64 X2 puts its request on the System Request Queue (SRQ).
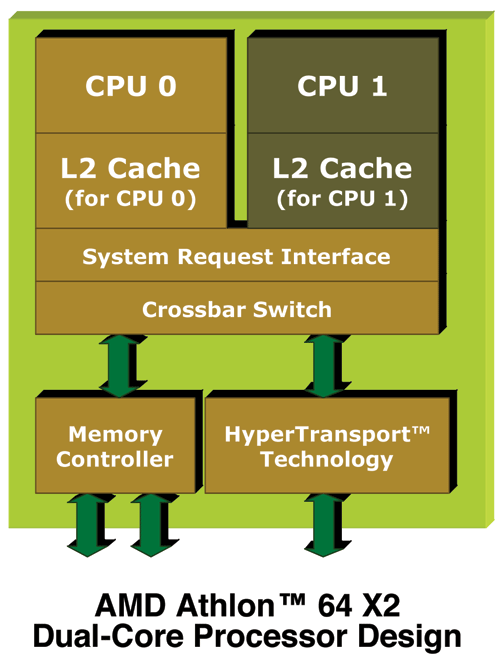
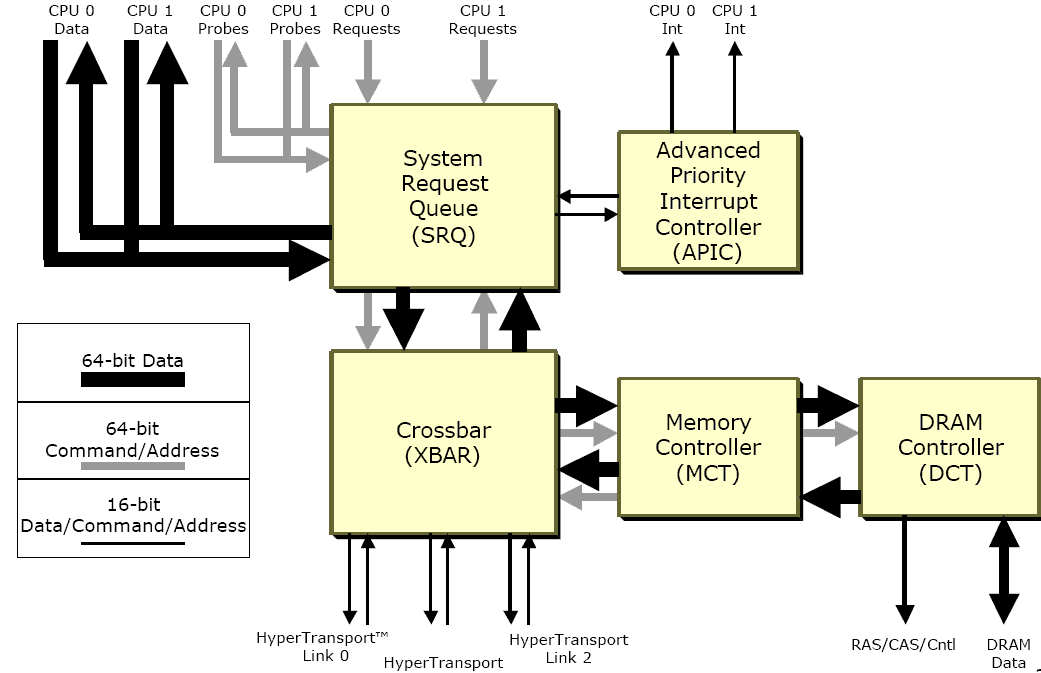
Click to enlarge.








28 Comments
View All Comments
Viditor - Friday, May 20, 2005 - link
fitten - Thanks very much for the explanation!fitten - Friday, May 20, 2005 - link
"When a thread is blocked it got swapped out of the processor all together. It is the OS's job to check if some conditions are met to re-waken a thread. So a waiting thread will not be actively checking that data at any time.Only in single-write/multi-read situation (server/consumer model) those consumer threads are not blocked but actively checking for new data."
Only if you are using synchronization primitives (mutex, critical section, semaphore, etc.) which are kernel objects or you call sleep() or something in the midst of reading/writing values. If you are just reading/writing a memory location, the OS doesn't know anything about it. Plus, if you have multiple CPUs/cores, more than one thread can be running simultaneously, which is where the MOESI protocols really come into play.
cz - Friday, May 20, 2005 - link
When a thread is blocked it got swapped out of the processor all together. It is the OS's job to check if some conditions are met to re-waken a thread. So a waiting thread will not be actively checking that data at any time.Only in single-write/multi-read situation (server/consumer model) those consumer threads are not blocked but actively checking for new data.
fitten - Thursday, May 19, 2005 - link
"When you write a program where the threads are effectively fighting over the ownership of data, particularly in the current designs of multiprocessor (this includes multi-core) cache systems, performance will tank because of all the overhead of taking ownership and such"But doesn't AMDs MOESI protocol help avoid this by allowing one cache to copy data from another?"
No, MOESI doesn't help avoid the problem - It is the mechanism of how the problem is arbitrated and resolved.
Simplified example: CPU1 wants some data. The cache subsystem uses MOESI to determine that CPU0 currently owns that data. MOESI protocols are then used to transfer the ownership of that data to CPU1 (including copying the data to a different cache if necessary). Meanwhile, one (definitely the writing core) or both cores must wait while the MOESI stuff is done and then CPU1 is allowed to proceed with its write.
So, you can write a two thread program where each thread does nothing but writes a value into a memory location (both threads write to the same memory location). That cannot be avoided by anything. On every write, MOESI will be invoked to resolve the ownership of the data and make sure the processor currently wanting to write to that memory location owns it. So, these two threads will generate massive amounts of MOESI traffic between the two caches (on a multi-core or multi-processor machine) because both cores want to effectively always own that memory. While MOESI is fast, it still takes time to resolve, longer than not having to do the transfer of ownership and any copying required in any case. So, you have two cores fighting over the data and generating a lot of MOESI overhead which saps performance from both cores (both cores spend a bit of time waiting until the cache tells it that it can do its writing).
"I agree fully that most multi threaded applications are coarse grained. But there are HPC applications where you can not avoid to work on shared data. I believe fluid dynamics, and OLTP applications that mix writes with reads (and use row locking) are examples."
Absolutely. There are times when it simply cannot be avoided and must be done. But, if you can avoid it, then you probably want to avoid it :)
JohanAnandtech - Thursday, May 19, 2005 - link
Ahkorishaan:Good summary, that is most likely what is happening at Intel.
bob661:
"The Quest for More Processing Power, Part Three: ", that doesn't sound like a buyers guide hey? :-)
nserra:
Very astute! Ok, ok, "AMDs current dual core architecture is pretty good, let’s wait Until Intel gets it right :-).
Fitten:
I agree fully that most multi threaded applications are coarse grained. But there are HPC applications where you can not avoid to work on shared data. I believe fluid dynamics, and OLTP applications that mix writes with reads (and use row locking) are examples.
Viditor - Thursday, May 19, 2005 - link
"When you write a program where the threads are effectively fighting over the ownership of data, particularly in the current designs of multiprocessor (this includes multi-core) cache systems, performance will tank because of all the overhead of taking ownership and such"But doesn't AMDs MOESI protocol help avoid this by allowing one cache to copy data from another?
fitten - Thursday, May 19, 2005 - link
Processes that will benefit from fast cache-cache transfers are ones that are multithreaded and the threads are manipulating the same data. There are applications that do this, but usually when you design multi-threaded applications you try to avoid these type situations. When you write a program where the threads are effectively fighting over the ownership of data, particularly in the current designs of multiprocessor (this includes multi-core) cache systems, performance will tank because of all the overhead of taking ownership and such. Shared (L2) caches tend to help this out because the data doesn't actually have to be transfered to the other core's cache as a part of the taking of ownership, the cache line(s) can stay right where they are with only the ownership modified.Anyway, HPC code usually goes through pains to avoid the situation where ownership of data must switch between processes/threads often. That's why data partitioning is one of the most important steps of application design in parallel applications.
blackbrrd - Thursday, May 19, 2005 - link
Uhm.. #19 - that is exactly the point, to check if a row is locked you most likely have to query the other caches to see if it is locked or not...JNo - Thursday, May 19, 2005 - link
"In Part 2, Tim Sweeney, the leading developer behind the Unreal 3 engine, explained the challenges of multi-threaded development of the next generation of games."...before showing off a beautiful working demo of the Unreal 3 engine on the 7-core PS3 cell processor that was put together in only 2 months and that was relatively easy to develop according to the Unreal guys themselves... Ha! (cos Sweeney did downplay the use of multithreading in games if you read his original comments)
cz - Thursday, May 19, 2005 - link
It is an interesting read I would say. But I would like to point out that OLTP programs will not benefit from cache2cache performance very much. That is because the very principle of multi-threaded programming requires the user account to be locked before updating. So only one thread can update an user account at any given time and other threads are blocked. Only programs that use data in single-write and multi-read form will benefit from cache2cache performance. And most likely these applications will be some sort of scientific simulations.