AMD Zen Microarchitecture: Dual Schedulers, Micro-Op Cache and Memory Hierarchy Revealed
by Ian Cutress on August 18, 2016 9:00 AM EST
In their own side event this week, AMD invited select members of the press and analysts to come and discuss the next layer of Zen details. In this piece, we’re discussing the microarchitecture announcements that were made, as well as a look to see how this compares to previous generations of AMD core designs.
AMD Zen
Prediction, Decode, Queues and Execution
First up, let’s dive right into the block diagram as shown:
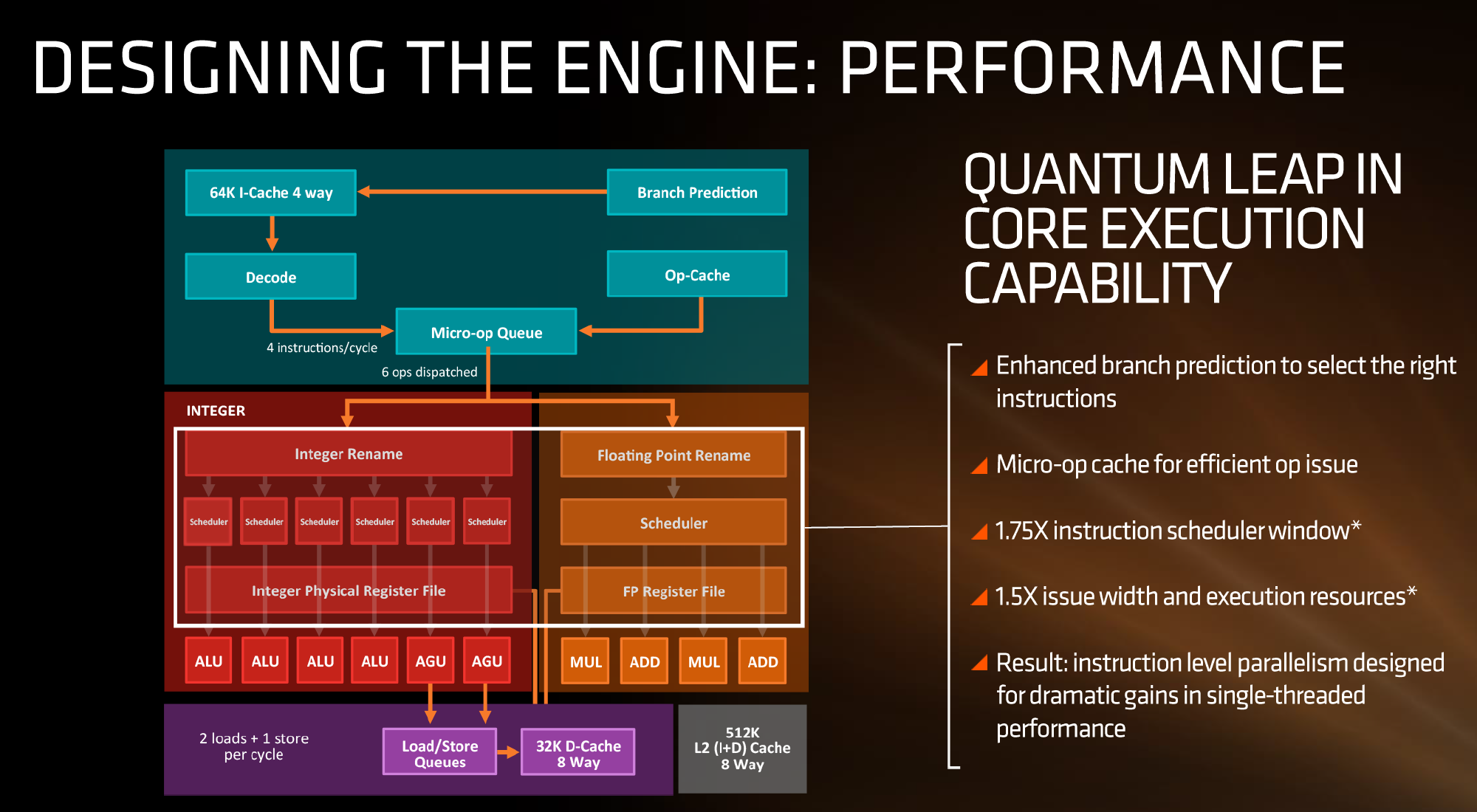
If we focus purely on the left to start, we can see most of the high-level microarchitecture details including basic caches, the new inclusion of an op-cache, some details about decoders and dispatch, scheduler arrangements, execution ports and load/store arrangements. A number of slides later in the presentation talk about cache bandwidth.
Firstly, one of the bigger deviations from previous AMD microarchitecture designs is the presence of a micro-op cache (it might be worth noting that these slides sometimes say op when it means micro-op, creating a little confusion). AMD’s Bulldozer design did not have an operation cache, requiring it to fetch details from other caches to implement frequently used micro-ops. Intel has been implementing a similar arrangement for several generations to great effect (some put it as a major stepping stone for Conroe), so to see one here is quite promising for AMD. We weren’t told the scale or extent of this buffer, and AMD will perhaps give that information in due course.
Aside from the as-expected ‘branch predictor enhancements’, which are as vague as they sound, AMD has not disclosed the decoder arrangements in Zen at this time, but has listed that they can decode four instructions per cycle to feed into the operations queue. This queue, with the help of the op-cache, can deliver 6 ops/cycle to the schedulers. The reasons behind the queue being able to dispatch more per cycle is if the decoder can supply an instruction which then falls into two micro-ops (which makes the instruction vs micro-op definitions even muddier). Nevertheless, this micro-op queue helps feed the separate integer and floating point segments of the CPU. Unlike Intel who uses a combined scheduler for INT/FP, AMD’s diagram suggests that they will remain separate with their own schedulers at this time.
The INT side of the core will funnel the ALU operations as well as the AGU/load and store ops. The load/store units can perform 2 16-Byte loads and one 16-Byte store per cycle, making use of the 32 KB 8-way set associative write-back L1 Data cache. AMD has explicitly made this a write back cache rather than the write through cache we saw in Bulldozer that was a source of a lot of idle time in particular code paths. AMD is also stating that the load/stores will have lower latency within the caches, but has not explained to what extent they have improved.
The FP side of the core will afford two multiply ports and two ADD ports, which should allow for two joined FMAC operations or one 256-bit AVX per cycle. The combination of the INT and FP segments means that AMD is going for a wide core and looking to exploit a significant amount of instruction level parallelism. How much it will be able to depends on the caches and the reorder buffers – no real data on the buffers has been given at this time, except that the cores will have a +75% bigger instruction scheduler window for ordering operations and a +50% wider issue width for potential throughput. The wider cores, all other things being sufficient, will also allow AMD’s implementation of simultaneous multithreading to potentially take advantage of multiple threads with a linear and naturally low IPC.








216 Comments
View All Comments
Zingam - Thursday, August 18, 2016 - link
AMD realized finally that there is nothing better in the x86 world than copying Intel.tarqsharq - Thursday, August 18, 2016 - link
The same way Intel copied x86-64 from AMD? Or how AMD put out a superior dual core solution?Copying has gone both ways.
Stuka87 - Thursday, August 18, 2016 - link
Intel did not copy x86-64, they licensed it from AMD.Krysto - Thursday, August 18, 2016 - link
Which by the way is one of the reasons why the argument that "Intel would never allow AMD to be sold to another company" is so STUPID. If they do something like that and somehow retract their own licensing to AMD, let's see how well Intel does in the market without the 64-bit support licensed from AMD......That's why I believe AMD could easily sell itself to Qualcomm or Samsung if it wanted to. Intel may throw a hissy fit, but at the end of the day there's nothing they can do about it. Worst case scenario, whoever buys AMD, has to pay a little more for Intel's IP, but nothing that would break the company.
Kvaern1 - Thursday, August 18, 2016 - link
The licensing agreement is automatically terminated if either part goes through a change of control.Piraal - Thursday, August 18, 2016 - link
If intel wasn't licensed then it would be monopoly for AMD in no time, ever wonder why they licensed intel?Guess what intel licensed x86 to AMD before that for the same reason. It is funny how few people understand why AMD, and Intel before that 'had' to essentially give up something that would destroy their biggest competitor.
Morawka - Thursday, August 18, 2016 - link
IIRC if was part of a settlement between AMD and Intel that lead to the x64 getting licensed. i could be wrong thoSamus - Friday, August 19, 2016 - link
Actually the way I last read the licensing agreement worked is as long as AMD licenses x86, Intel has exclusive use of any AMD innovations in x86. That's how Intel essentially "licensed" x86-64 for free.It's like Mazda licensing a platform to Ford to build, and in return Mazda is allowed to monitor improvements to the platform to use on their own vehicles. This is commonly referred to as a joint venture technology agreement, and although AMD and Intel don't call it that, it's what it appears to be because the fine print of Intel licensing permits them to peak inside architectural improvements.
Note that this has nothing to do with the manufacturing end, unlike my Mazda>Ford analogy which is exclusively manufacturing based.
Anato - Saturday, August 20, 2016 - link
"Actually the way I last read the licensing agreement worked is as long as AMD licenses x86, Intel has exclusive use of any AMD innovations in x86. That's how Intel essentially "licensed" x86-64 for free."I doubt this, as this would mean that terminating AMD would terminate Intel x86-64 license. Think IBM, Samsung, Oracle or Apple buying AMD and stop making x86. Then Intel would not have x86-64 license anymore. So by paying 5-10B$ for AMD you could stop Intel's current 64 license which is >70% (?) of their revenue or use this as ransom.
Samus - Saturday, August 20, 2016 - link
All past-tense licensed innovation is grandfathered in upon a technology agreement termination. Legally. For instance, Mazda and Ford can use each others previous platforms indefinitely.