AMD Carrizo Part 2: A Generational Deep Dive into the Athlon X4 845 at $70
by Ian Cutress on July 14, 2016 9:00 AM ESTAnalyzing Generational Updates
Going through the benchmark data for our Carrizo part compared to Kaveri, Richland and Trinity gives two very different sides of the same story. Simply put, it would come across that Carrizo is overall better at CPU tasks when you compare clock for clock, but performs worse when a discrete graphics card is in play for gaming. There are some slight exceptions for both sides of this story, especially when larger memory accesses comes in, but this comes down to the design choices when Carrizo for desktop was made. The fact that we have a laptop CPU in desktop clothing is going to be a main detractor when it comes to gaming, but the CPU compute side of the equation is very promising indeed.
In our generational testing, we compared the following four processors at 3 GHz and running the highest supported JEDEC memory speeds for each:
| AMD CPUs | ||||||||||||
| µArch / Core |
Cores | Base Turbo |
TDP | DDR3 | L1 (I) Cache |
L1 (D) Cache |
L2 Cache |
|||||
| Athlon X4 845 |
Excavator Carrizo |
4 | 3500 3800 |
65 W | 2133 | 192KB 3-way |
128KB 8-way |
2 MB 16-way |
||||
| Athlon X4 860K |
Steamroller Kaveri |
4 | 3700 4000 |
95 W | 1866 | 192KB 3-way |
64KB 4-way |
4 MB 16-way |
||||
| Athlon X4 760K |
Piledriver.v2 Richland |
4 | 3800 4100 |
100 W | 1866 | 128KB 2-way |
64KB 4-way |
4 MB 16-way |
||||
| Athlon X4 750K |
Piledriver Trinity |
4 | 3400 4000 |
100 W | 1866 | 128KB 2-way |
64KB 4-way |
4 MB 16-way |
||||
It is worth noting that for the most part the X4 750K and X4 760K are essentially equal, using a slightly modified Piledriver v2 microarchitecture for the X4 760K that in most cases performs similarly to the other processor at the same frequency. This will come through in almost all of our benchmark comparisons. However, the main battle will be between the top two.
Comparing the Upgrade: 2012 to 2016
Our results are going to be compared in two different ways. Firstly, we are going to look at the absolute improvement of each processor compared to the lowest one in the test: Trinity. This gives a direct analysis of the performance increase per clock total increase for every generation from 2012 to 2016. What follows is a series of graphs for each of our benchmark sections showing the results of each benchmark as a percentage improvement over Trinity. We'll analyze each one in turn.
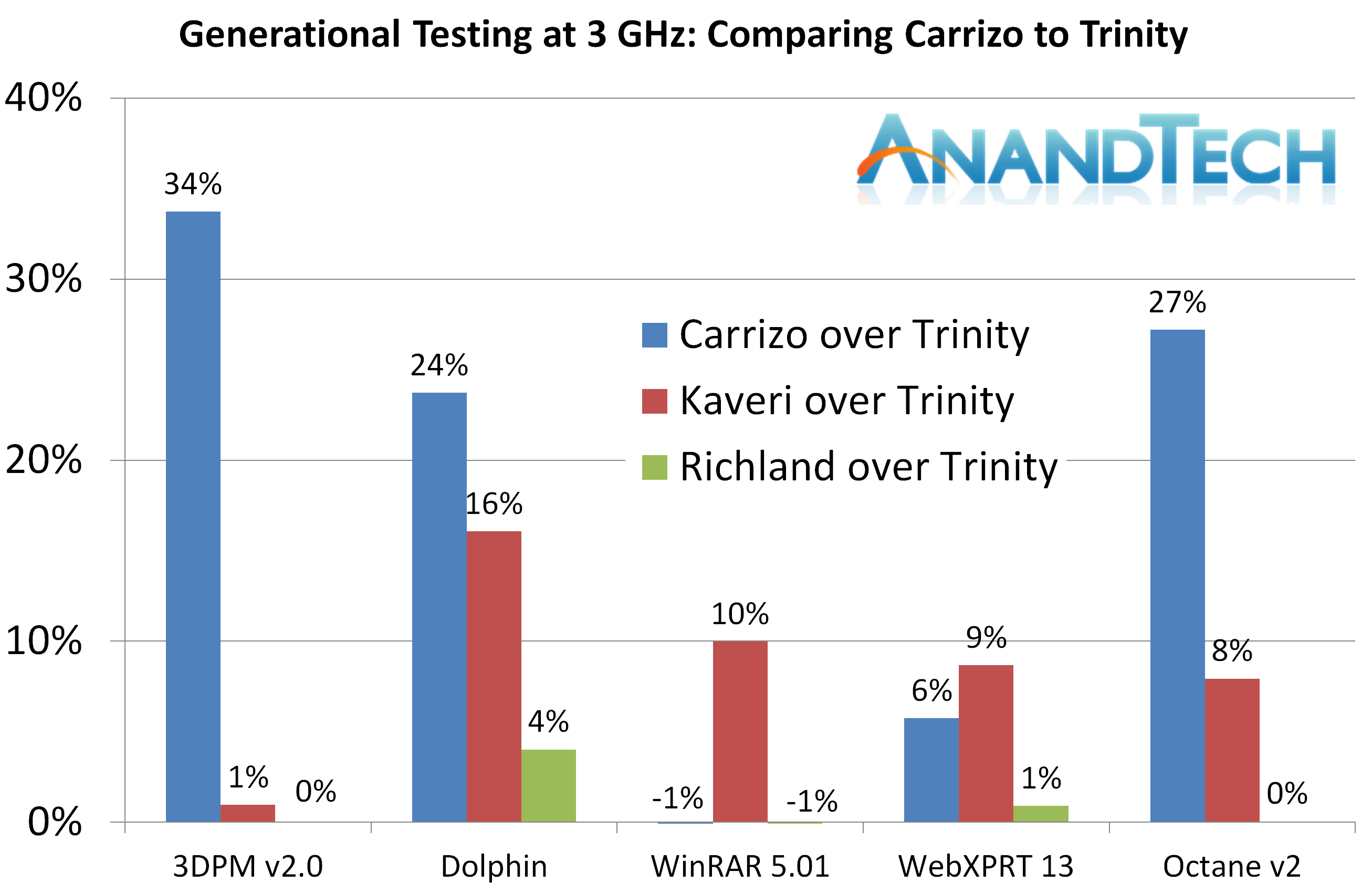
From our Real World benchmarks, Carrizo gets a good showing in three of the benchmarks, showing a sizeable jump over Kaveri, however WinRAR and WebXPRT are a little lower.
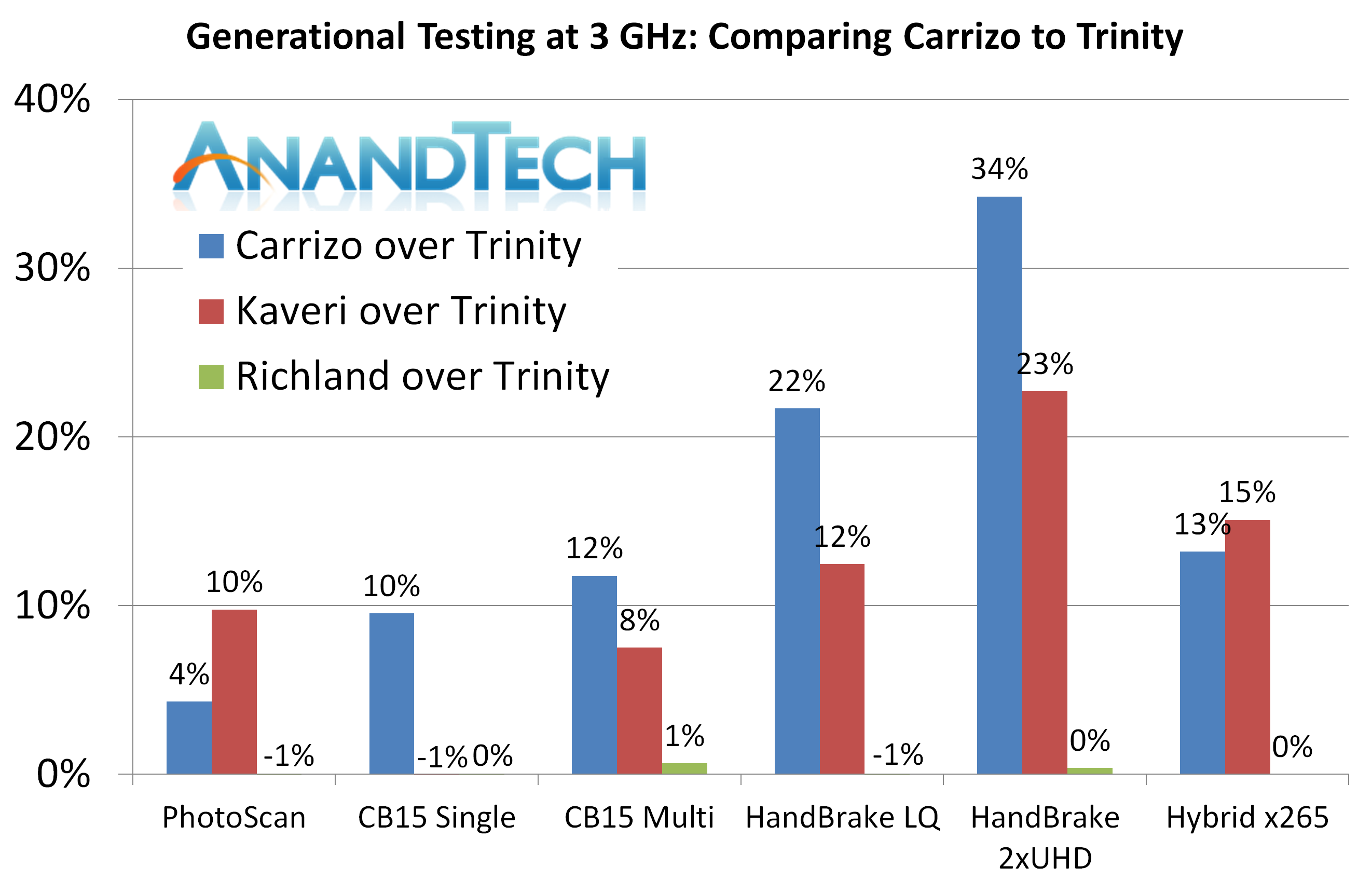
For the office tests, Carrizo takes the biggest gain for CineBench and Handbrake, but sits behind in Photoscan and Hybrid. HandBrake shows a sizable gain in both tests compared to Trinity.
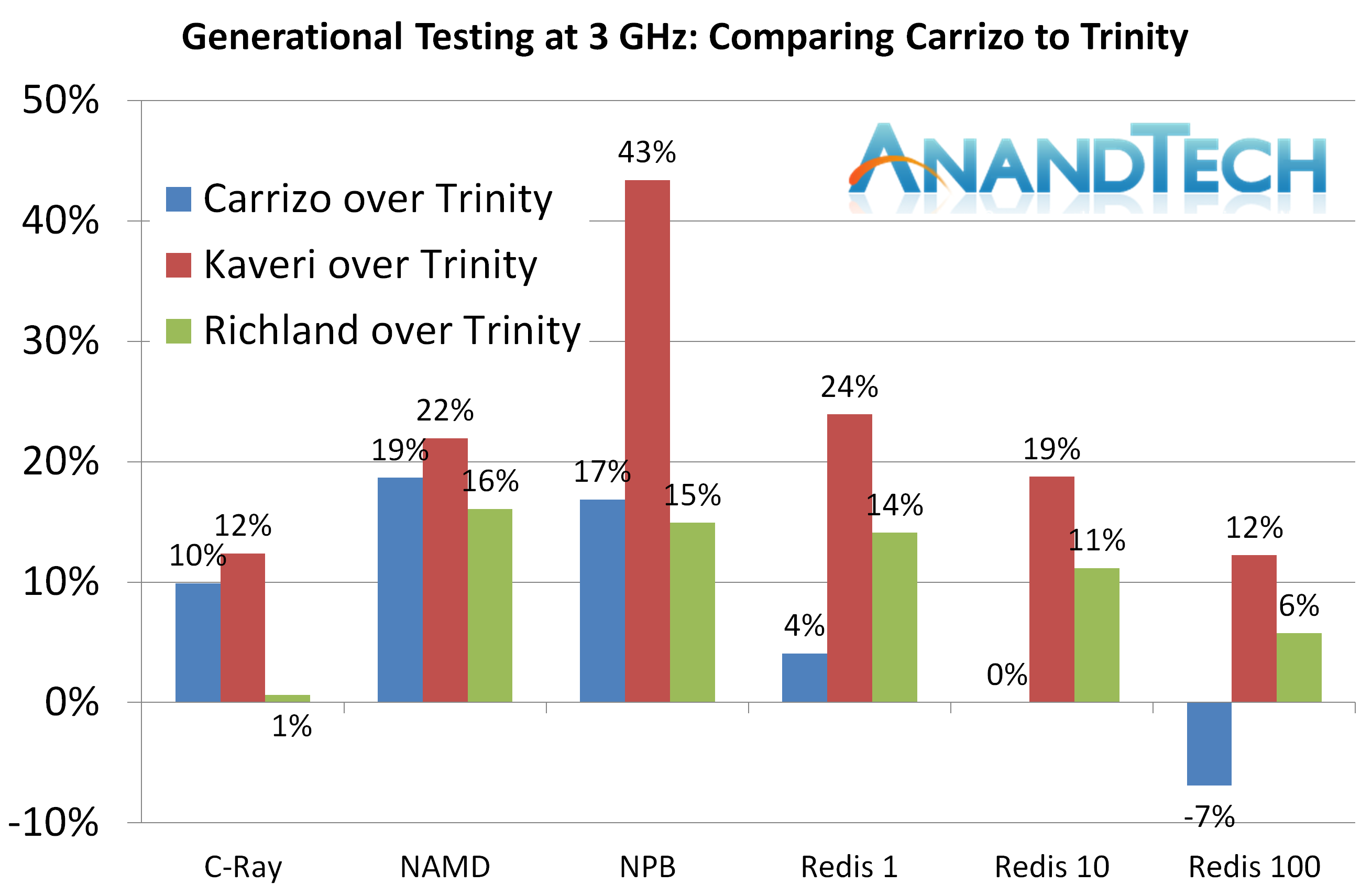
The Linux-Bench tests shows Carrizo behind Kaveri in each instance, and behind Richland for all three Redis tests. As we explained in that section, Redis is very memory dependent and as a result, despite having the larger L1 cache, only having 2 MB of L2 cache is a blow to the Carrizo part.
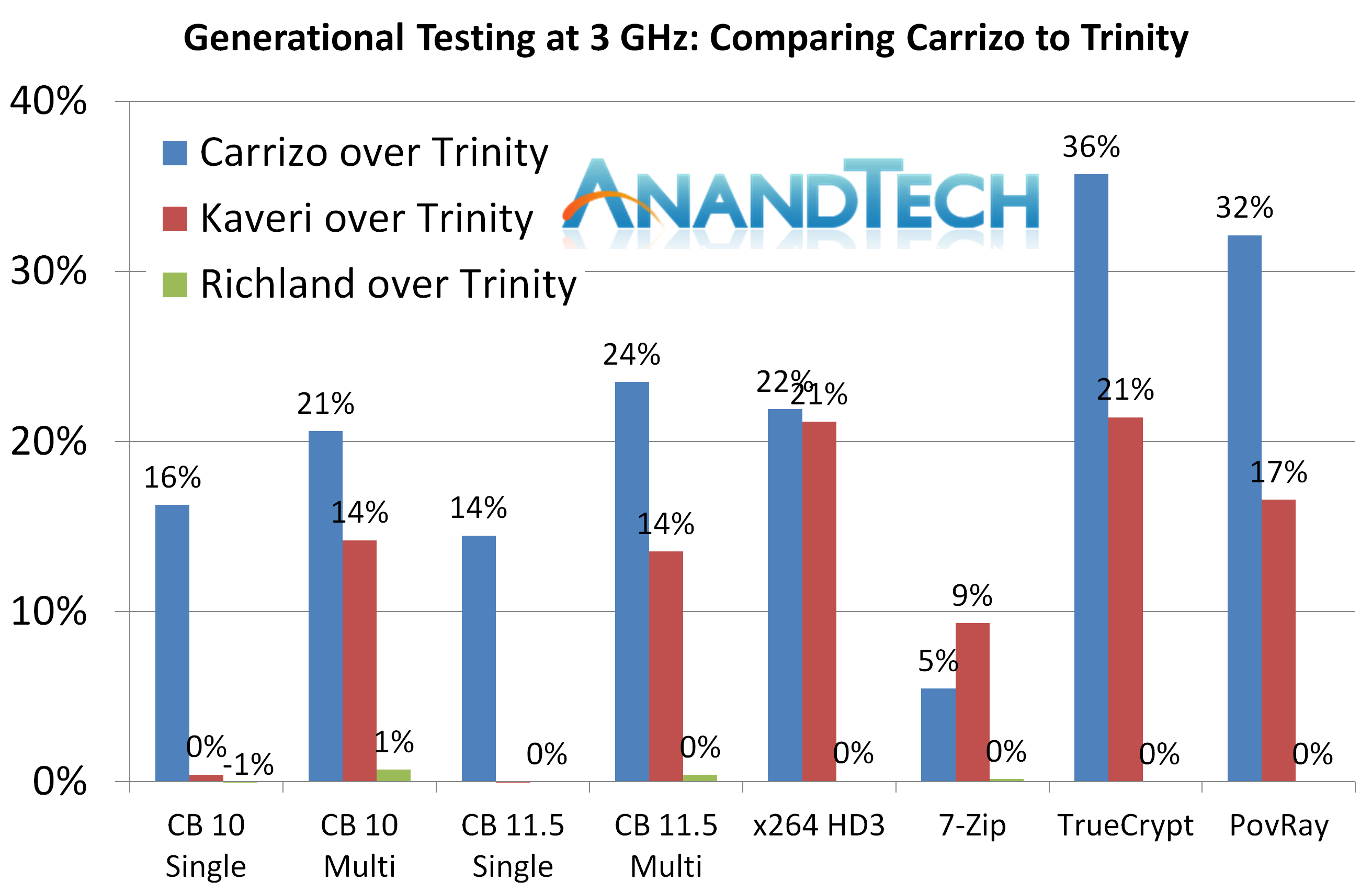
So here is where it is interesting. If you were only looking at synthetic and legacy tests in isolation, like many other review websites do, then you could be forgiven that it shows Carrizo taking a distinct lead in every benchmark (except 7-zip). In many cases there is a 10-20% gain over Kaveri.
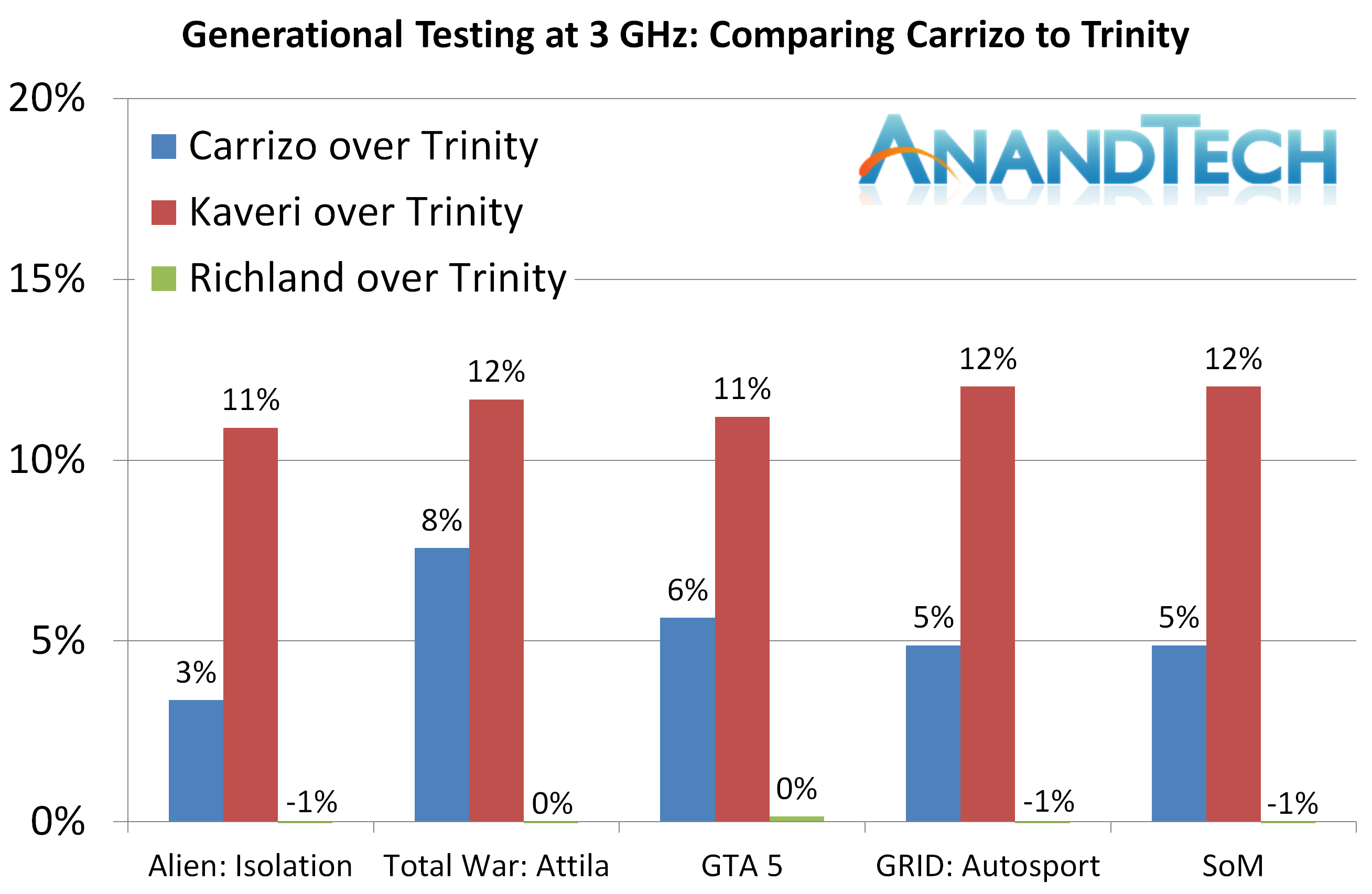
For gaming, as explained in the testing, despite the improvement over Trinity that Carrizo offers, the deficit to Kaveri is consistent across the board.
Comparing IPC
Next, we have the generational updates moving from Trinity to Richland to Kaveri to Carrizo. This is where we typically expect to see single-digit percentage increases moving through the generations, with double digits for large gains or introduction of new IP blocks into the silicon (e.g. encryption or video conversion). Again, we go through each of our five benchmark sections for this.
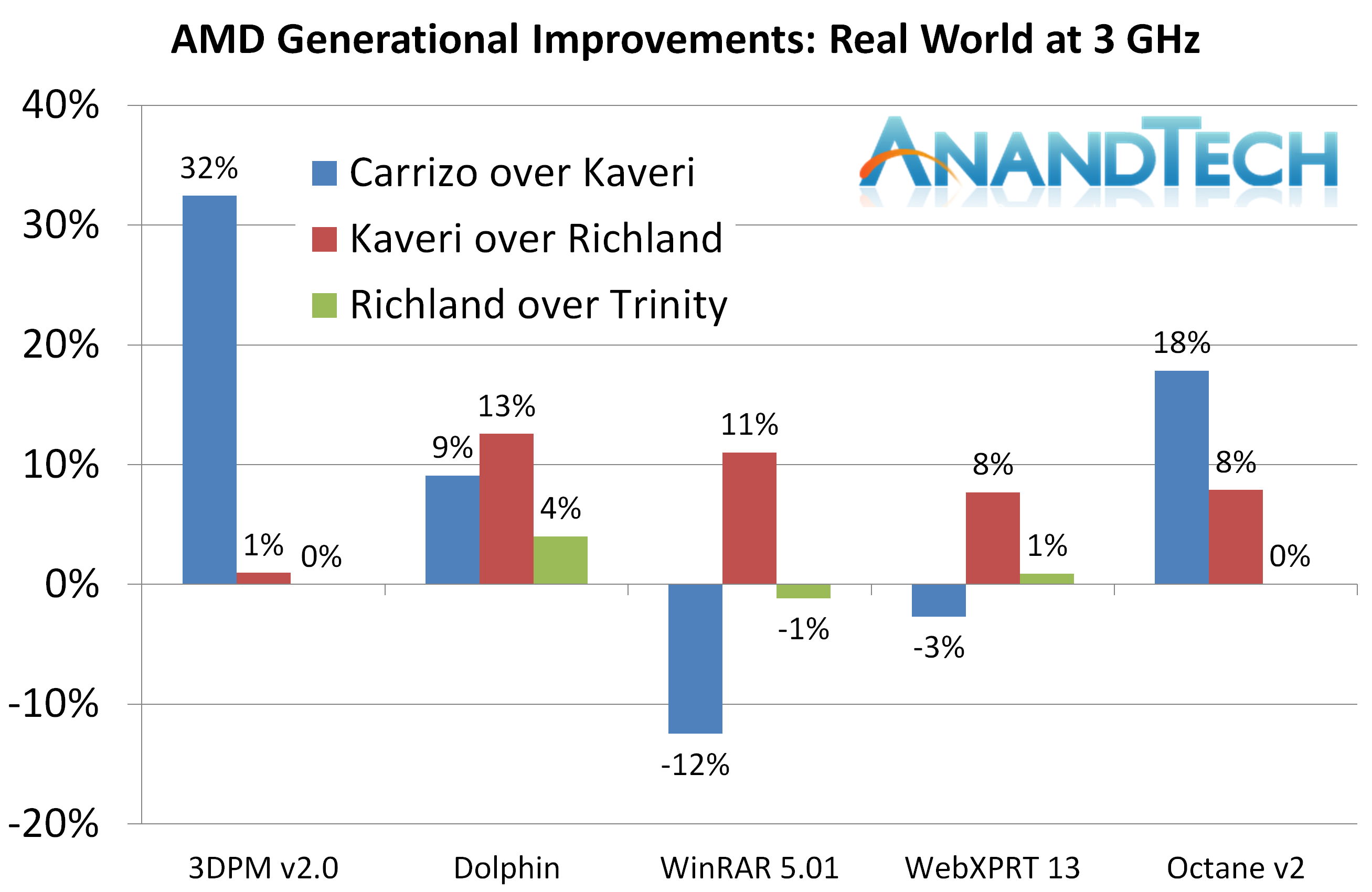
3DPM v2 takes the biggest gain, a massive 32% over Kaveri, due to better memory management and a larger L1 cache. WinRAR, being memory dependent, loses due to the smaller L2.
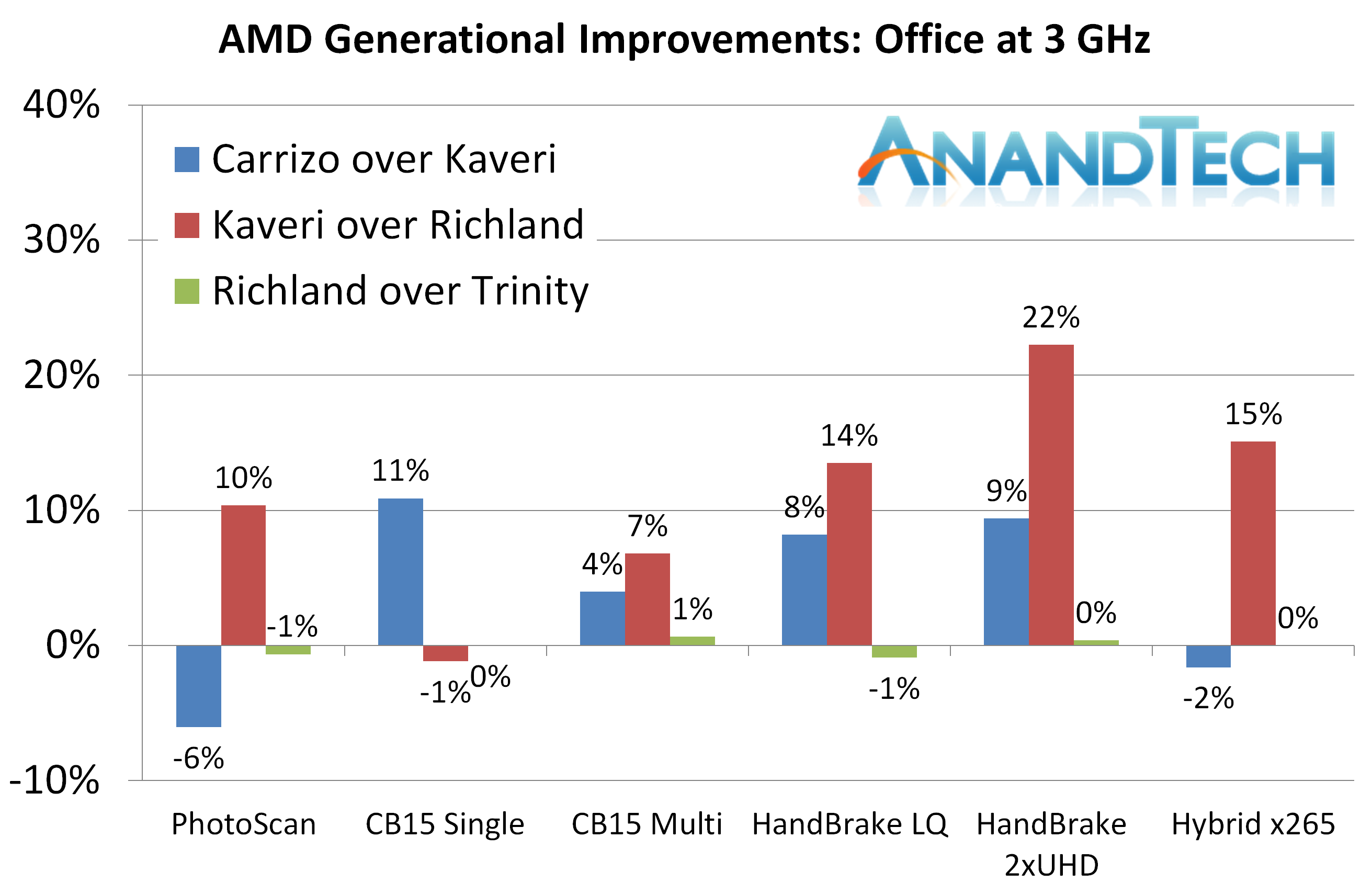
The office tests are a mixed bag - we see a regression in Photoscan due to large memory accesses, but it is clear that Kaveri was a bigger jump for a number of things than Carrizo.
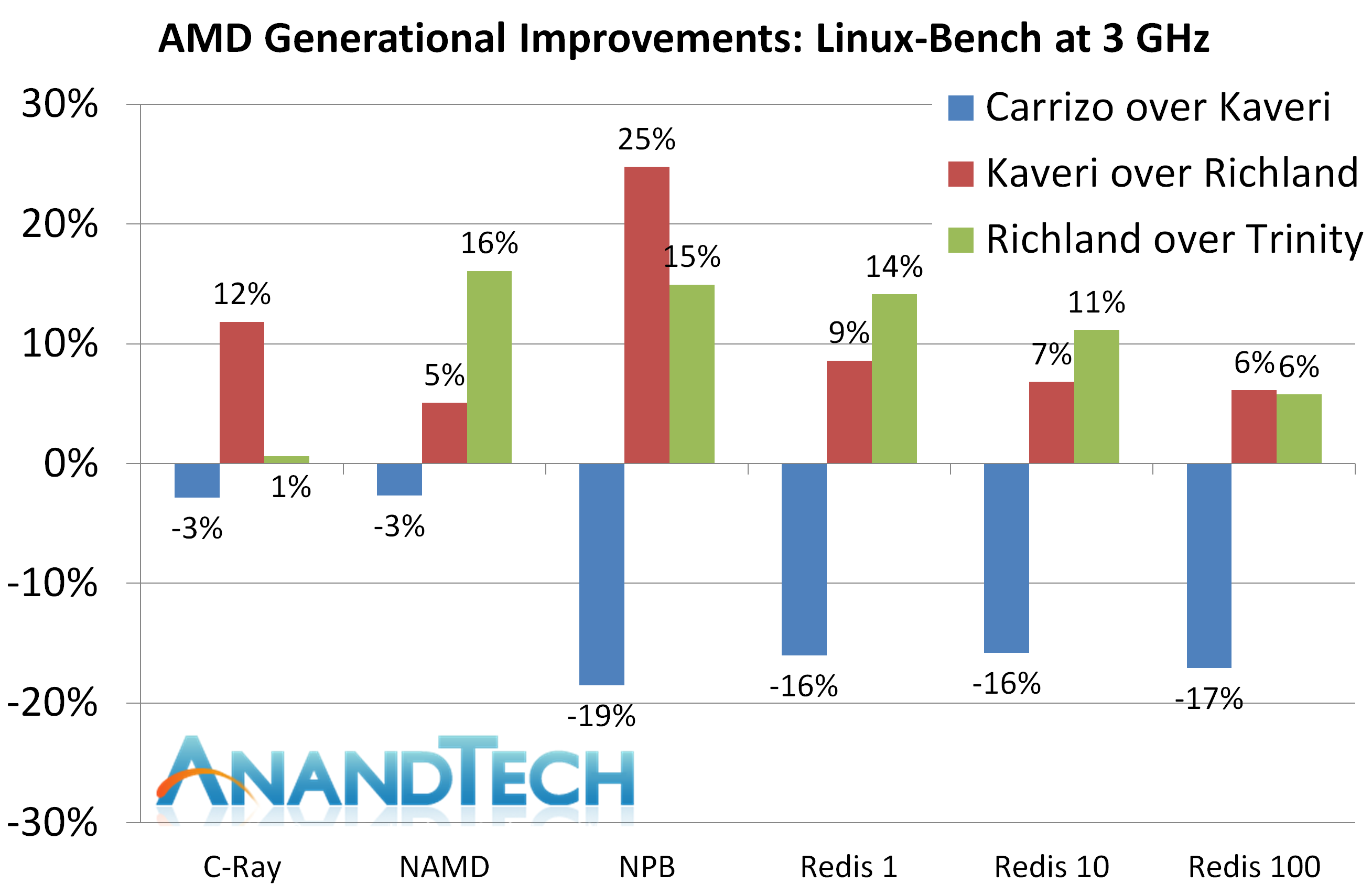
Our Linux tests get a poor showing across the board from Carrizo, which we saw in the results. In each case, the IPC for Carrizo is lower than that of Kaveri.
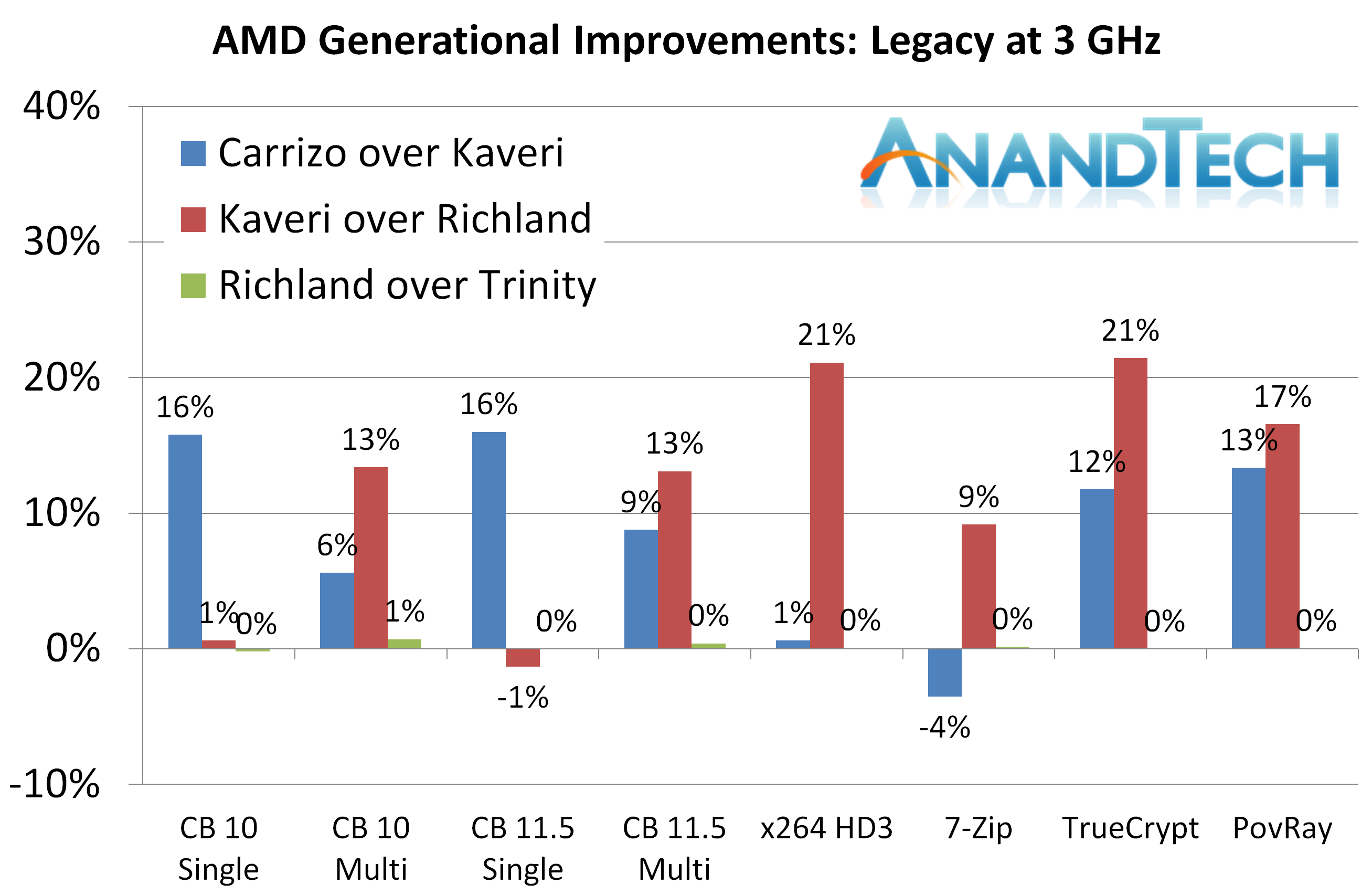
Back with the previous legacy results graph, we saw that Carrizo had a better performance than Kaveri across the board, except 7-zip. Translating this to IPC improvements and we see that in half the cases, moving to Kaveri was better than moving to Carrizo, with CineBench single threaded tests being the exception showing the capability of the core logic in Carrizo.
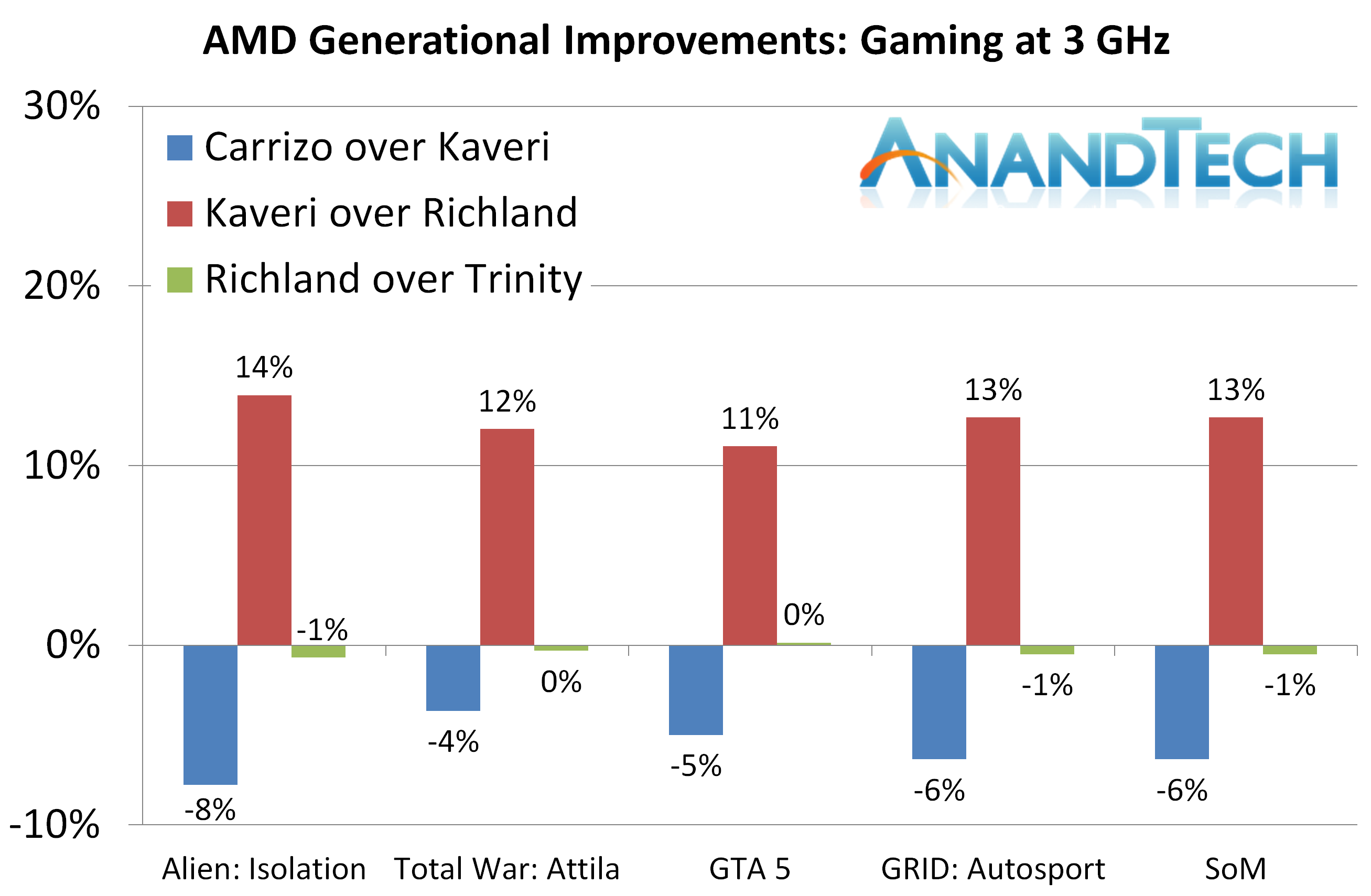
However, the big result will be for gaming. Clock for Clock, Carrizo gives an average 5.8% decrease in performance to Kaveri.
Conclusions
Wrapping all the numbers together, we get the following average IPC improvements for a Carrizo with 2MB of L2 cache over Kaveri with 4MB of L2 cache for each section:
| AMD Average IPC Increases | |||||||
| Benchmark Suite | Richland over Trinity | Kaveri over Richland | Carrizo over Kaveri | ||||
| Real World | 0.8% | 8.0% | 8.8% | ||||
| Office | -0.1% | 11.1% | 4.1% | ||||
| Legacy | 0.1% | 11.8% | 8.5% | ||||
| Overall Windows |
0.3% | 10.3% | 7.3% | ||||
| Linux | 10.4% | 10.5% | -12.1% | ||||
| Gaming | -0.4% | 12.5% | -5.8% | ||||
The headline figure, for CPU compute benchmarks (real world, office and legacy), is that Carrizo offers a +7.3% improvement over AMD's previous microarchitecture, Kaveri. It comes with the caveat that Linux and Gaming performance, which in our tests tend to rely more on memory accesses, perform 6-12% worse.








131 Comments
View All Comments
lefty2 - Thursday, July 14, 2016 - link
I'm predicting Bristol Ridge will be just as bad a failure as Carrizo. I.e. the few design wins will only have single DIMM memory and be universally unavailable, buried somewhere in a dark corner of the OEM's website. It's a pity, because both SoCs are very good in their own right.nandnandnand - Thursday, July 14, 2016 - link
If it's not Zen, it can be thrown straight in the garbage.Samus - Friday, July 15, 2016 - link
I still rock a few Kaveri desktops and they are incredibly powerful for the price. The 860K is half the cost of a comparable Intel chip, which supporting faster memory and a lower cost platform.Carizo on the desktop is an anomaly. I'd like to see what it could do with 4MB cache (would require an entirely new die)
Lolimaster - Saturday, July 16, 2016 - link
They were nice in 2014.We should have a nice 20nm 768SP APU in 2015 with a full L2 cache Excavator and fully mature 896SP 20nm early this year.
Remember the A8 3870K? That APU was a damn monster only hold back from being godly cause of their sub 3Ghz cpu speed, what we had after?
400SP VLIW5 2011 --> 384 VLIW4 2012 --> 384VLIW4 2013 --> 512SP GCN 2015 --> 512SP GCN 2016
Intel improved way faster (non "e" + edram igp's are near A8 level from being utter trash when the A8 3850 was release).
The_Countess - Tuesday, July 19, 2016 - link
yes being able to thrown in a extra billion transistors compared to AMD (1.7 vs 0.75 billion transistors for a quad core with GPU) because of 14nm really does help intel along a lot.but as nobody has been able to make a 20nm class process for anything but flash and ram besides intel, AMD's hands were tied. there is nothing AMD could have done to change that.
BlueBlazer - Friday, July 15, 2016 - link
Formula for failure: FM2 socket (with limited CPU upgradeability), only PCI Express x8 lanes available (which can bottleneck GPUs), and only "4 cores" (which performs more like 2C/4T Core i3 processor).neblogai - Friday, July 15, 2016 - link
Bristol Ridge is not FM2; PCI-E x8 can not bottleneck midrange GPUs; ultra low power mobile APU also sold as desktop chip is not a failure, just additional revenueBlueBlazer - Friday, July 15, 2016 - link
The results in the article shows otherwise, where AMD's Bristol Ridge was slower in most gaming tests, despite having better performance in some applications. Both FM2 and FM2+ are still the same (legacy) socket. AMD will be probably selling these chips at a loss. Note that these are the same (large) dies as Carrizo chips, and at 250mm^2 coupled with low prices typically meant razor thin margins or none at all.silverblue - Friday, July 15, 2016 - link
That L2 cache is probably making more difference than you realise.evolucion8 - Saturday, July 16, 2016 - link
The PCI-E is busted, even at PCI E 2.0 @ 4X, it barely makes a difference on the Fury X and the GTX 980 Ti.