The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTDesigning GP104: Running Up the Clocks
So if GP104’s per-unit throughput is identical to GM204, and the SM count has only been increased from 2048 to 2560 (25%), then what makes GTX 1080 60-70% faster than GTX 980? The answer there is that instead of vastly increasing the number of functional units for GP104 or increasing per-unit throughput, NVIDIA has instead opted to significantly raise the GPU clockspeed. And this in turn goes back to the earlier discussion on TSMC’s 16nm FinFET process.
With every advancement in fab technology, chip designers have been able to increase their clockspeeds thanks to the basic physics at play. However because TSMC’s 16nm node adds FinFETs for the first time, it’s extra special. What’s happening here is a confluence of multiple factors, but at the most basic level the introduction of FinFETs means that the entire voltage/frequency curve gets shifted. The reduced leakage and overall “stronger” FinFET transistors can run at higher clockspeeds at lower voltages, allowing for higher overall clockspeeds at the same (or similar) power consumption. We see this effect to some degree with every node shift, but it’s especially potent when making the shift from planar to FinFET, as has been the case for the jump from 28nm to 16nm.
Given the already significant one-off benefits of such a large jump in the voltage/frequency curve, for Pascal NVIDIA has decided to fully embrace the idea and run up the clocks as much as is reasonably possible. At an architectural level this meant going through the design to identify bottlenecks in the critical paths – logic sections that couldn’t run at as high a frequency as NVIDIA would have liked – and reworking them to operate at higher frequencies. As GPUs typically (and still are) relatively low clocked, there’s not as much of a need to optimize critical paths in this matter, but with NVIDIA’s loftier clockspeed goals for Pascal, this changed things.
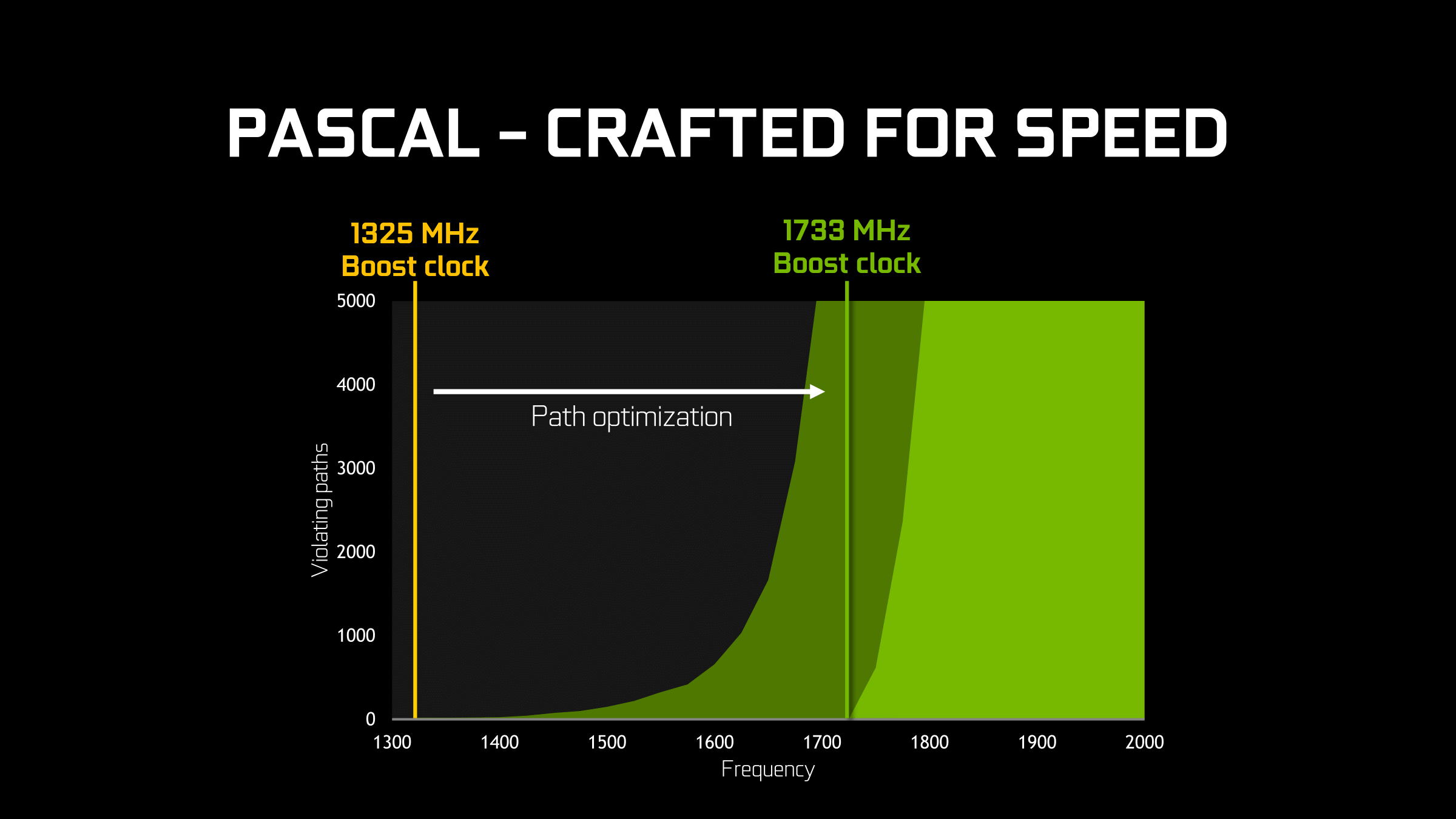
From an implementation point of view this isn’t the first time that NVIDIA has pushed for high clockspeeds, as most recently the 40nm Fermi architecture incorporated a double-pumped shader clock. However this is the first time NVIDIA has attempted something similar since they reined in their power consumption with Kepler (and later Maxwell). Having learned their lesson the hard way with Fermi, I’m told a lot more care went into matters with Pascal in order to avoid the power penalties NVIDIA paid with Fermi, exemplified by things such as only adding flip-flops where truly necessary.
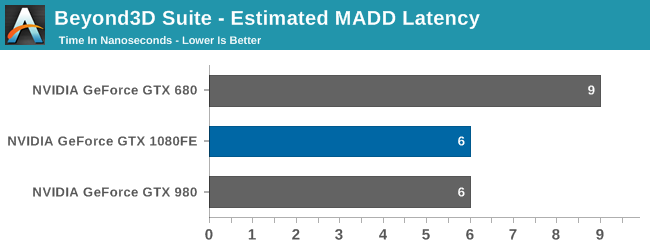
Meanwhile when it comes to the architectural impact of designing for high clockspeeds, the results seem minimal. While NVIDIA does not divulge full information on the pipeline of a CUDA core, all of the testing I’ve run indicates that the latency (in clock cycles) of the CUDA cores is identical to Maxwell. Which goes hand in hand with earlier observations about throughput. So although optimizations were made to the architecture to improve clockspeeds, it doesn’t look like NVIDIA has made any more extreme optimizations (e.g. pipeline lengthening) that detectably reduces Pascal’s per-clock performance.
Finally, more broadly speaking, while this is essentially a one-time trick for NVIDIA, it’s an interesting route for them to go. By cranking up their clockspeeds in this fashion, they avoid any real scale-out issues, at least for the time being. Although graphics are the traditional embarrassingly parallel problem, even a graphical workload is subject to some degree of diminishing returns as GPUs scale farther out. A larger number of SMs is more difficult to fill, not every aspect of the rendering process is massively parallel (shadow maps being a good example), and ever-increasing pixel shader lengths compound the problem. Admittedly NVIDIA’s not seeing significant scale-out issues quite yet, but this is why GTX 980 isn’t quite twice as fast as GTX 960, for example.
Just increasing the clockspeed, comparatively speaking, means that the entire GPU gets proportionally faster without shifting the resource balance; the CUDA cores are 43% faster, the geometry frontends are 43% faster, the ROPs are 43% faster, etc. The only real limitation in this regard isn’t the GPU itself, but whether you can adequately feed it. And this is where GDDR5X comes into play.








200 Comments
View All Comments
Ryan Smith - Wednesday, July 20, 2016 - link
To follow: GTX 1060 Review (hopefully Friday), RX 480 Architecture Writeup/Review, and at some point RX 470 and RX 460 are still due.Chillin1248 - Wednesday, July 20, 2016 - link
Nice, don't worry about the rushers. There are plenty of day one reviewers, but few go into depth the way that makes it interesting.retrospooty - Wednesday, July 20, 2016 - link
Agreed, this is a good review, as the video card reviews here usually are... Agreed about rushing as well. A lot of sites have less thorough stuff out in 1-2 days... I am guessing that Ryan and the others at Anandtech have regular day jobs and doing these reviews and articles is done on their own time. If that is the case, 2 months seems right. If I am incorrect in that assumption and this is a full time job, then they should be coming out with articles alot faster.JoshHo - Wednesday, July 20, 2016 - link
Currently for mobile the only full time editor is Matt Humrick.AndrewJacksonZA - Wednesday, July 20, 2016 - link
Thank you Ryan. I look forward to more and reliable information about the 470 and especially the 460.prophet001 - Wednesday, July 20, 2016 - link
Hi All, I was just wondering if it's worth it to get the FE 1080 or just go with the regular one. Does the stock fan setup offer better thermals than the blower setup?Teknobug - Wednesday, July 20, 2016 - link
FE is a ripoffImSpartacus - Wednesday, July 20, 2016 - link
It's literally just the reference card. It's not a bad reference design, but it's generally considered a poor value for enthusiasts.HomeworldFound - Wednesday, July 20, 2016 - link
A reference design is very useful if you're watercooling though.trab - Wednesday, July 20, 2016 - link
Depends if your custom board has any actual changes, it may just be the reference board with a custom cooler, so it would make no difference. Of course it would also be cheaper to boot.