The NVIDIA GeForce GTX 1080 & GTX 1070 Founders Editions Review: Kicking Off the FinFET Generation
by Ryan Smith on July 20, 2016 8:45 AM ESTGP104’s Architecture
Looking at an architecture diagram for GP104, Pascal ends up looking a lot like Maxwell, and this is not by chance. After making more radical changes to their architecture with Maxwell, for Pascal NVIDIA is taking a bit of a breather. Which is not to say that Pascal is Maxwell on 16nm – this is very much a major feature update – but when it comes to discussing the core SM architecture itself, there is significant common ground with Maxwell.

We’ll start with the GP104 SM. Simply named the SM for this generation – NVIDIA has ditched the generational suffix due to the potential for confusion with the used-elsewhere SMP – the GP104 SM is very similar to the Maxwell SM. We’re still looking at a single SM partially sub-divided into four pieces, each containing a single warp scheduler that’s responsible for feeding 32 CUDA cores, 8 load/store units, and 8 Special Function Units, backed by a 64KB register file. There are two dispatch ports per warp schedule, so when an instruction stream allows it, a warp scheduler can extract a limited amount of ILP with an instruction stream by issuing a second instruction to an unused resource.
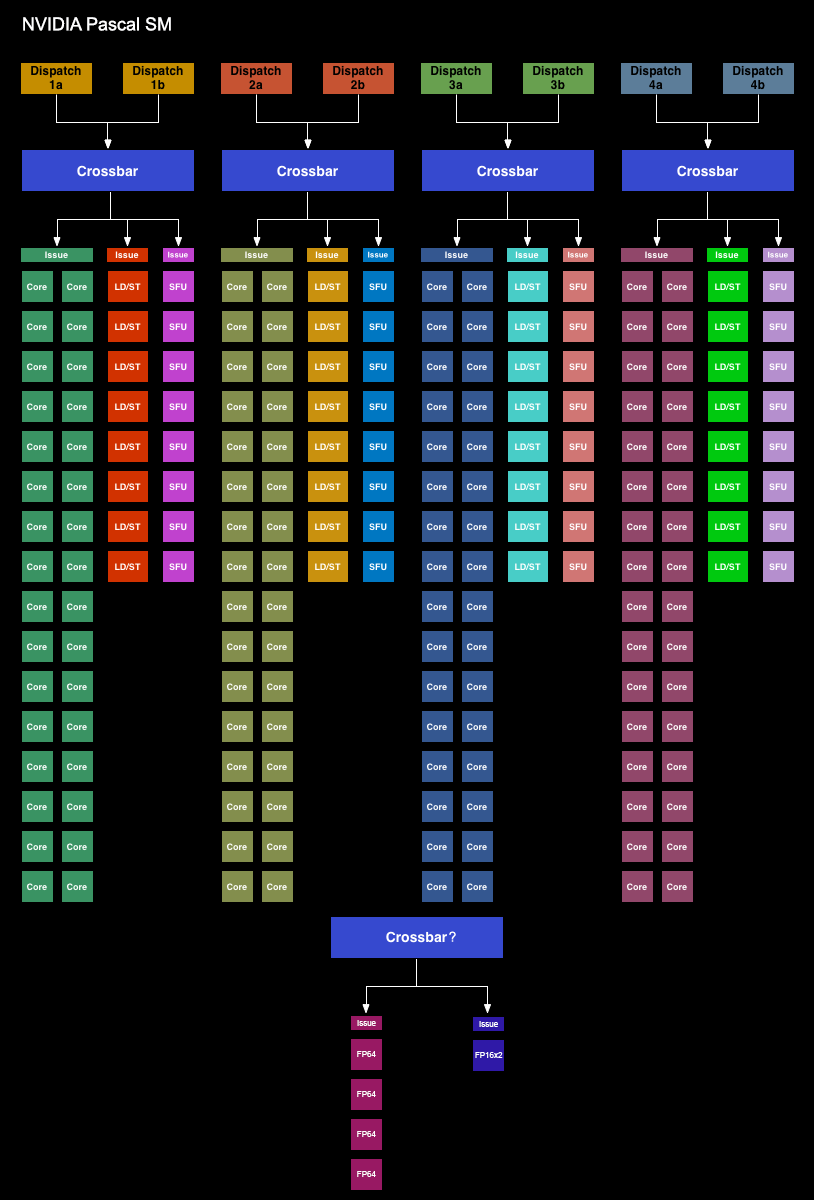
Meanwhile shared between every pair of sub-partitions is 4 texture units and the combined L1/texture cache, again unchanged from Maxwell. Finally, we have the resources shared throughout the whole SM: the 96KB shared memory, the instruction cache, and not pictured on NVIDIA’s diagrams, the 4 FP64 CUDA cores and 1 FP16x2 CUDA core.
Overall then at the diagram level the GP104 SM looks almost identical to the Maxwell SM, but with one exception: the PolyMorph Engine. Although the distinction is largely arbitrary for GP104, the PolyMorph Engine has been moved up a level; it’s no longer part of the SM, but rather part of the newly re-introduced TPC, which itself sits between the GPC and the SM.
The TPC exists because although GP104 still has a 1:1 ratio between PolyMorph Engines and SMs, the Pascal architecture itself allows for different SM configurations, which is in turn used on GP100 to allow it to have multiple smaller SMs of 64 CUDA Cores. For GP100 the TPC allows for multiple SMs to share a PolyMorph Engine, but for GP104 there’s no sharing involved. To that end the TPC as an organizational unit technically exists across all Pascal parts, but it has no real significance for GP104. In fact it doesn’t even have a real name; NVIDIA reused the acronym from earlier DX10 architectures, where the TPC was the name assigned to the Texture Processor Cluster.

Looking at the bigger picture of the complete GP104 GPU, the similarities continue between GP104 and GM204. GP104’s SMs are clustered five-a-piece inside of the GPC, with each cluster sharing a single Raster Engine. Overall there are 4 such GPCs, giving us 20 SMs altogether. Compared to GM204 then, we’re looking at the same number of GPCs, with each GPC having gained 1 SM.
Things get more interesting when we look at the back end of the rendering/execution pipeline, which is comprised of the L2 cache, ROPs, and memory controllers. The ROP/L2 count has not changed relative to GM204 – we still have 64 ROPs paired up with a total of 2MB of L2 cache – however the memory controller count has. And with it the logical configuration of the ROP/L2 blocks have changed as well.
Whereas GM204 had 4 64bit GDDR5 memory controllers, each connected to 2 or 4 memory chips, GP104 breaks that down further to 8 32bit GDDR5X memory controllers, each of which is connected to 1 memory chip on GTX 1080. I’ll go into greater detail on GDDR5X a bit later, but the significance of this backend organizational change has to do with the introduction of GDDR5X. Because GDDR5X reads and writes data in 64B amounts (versus 32B amounts on GDDR5), NVIDIA has reorganized the memory controllers to ensure that each memory controller still operates on the same amount of data. With GDDR5 they teamed up two GDDR5 channels to get 64B operations, whereas with GDDR5X this can be accomplished with a single memory channel.
This in turn is where the ROP reorganization comes from. As there’s a 1:1 relationship between ROP partitions and memory controllers, the 64 ROPs are now broken up into 8 partitions for GP104, as opposed to 4 partitions on GM204. There are some performance tradeoffs that come from having more ROP partitions, but to the best of my knowledge these should not be significant.
Meanwhile the new GDDR5X memory controllers are also backwards compatible with traditional GDDR5, which in turn is used to drive the GTX 1070 with its 8Gbps GDDR5. The difference in operation between GDDR5 and GDDR5X does make the ROP situation a bit trickier overall for NVIDIA’s architects – now they need to be able to handle two different memory access patterns – though for NVIDIA this isn’t a wholly new problem. Previous generation architectures have supported both GDDR5 and DDR3, the two of which have their own differences in memory access patterns.
In a by-the-numbers comparison then, Pascal does not bring any notable changes in throughput relative to Maxwell. CUDA cores, texture units, PolyMorph Engines, Raster Engines, and ROPs all have identical theoretical throughput-per-clock as compared to Maxwell. So on a clock-for-clock, unit-for-unit basis, Pascal is not any faster on paper. And while NVIDIA does not disclose the size/speed of most of their internal datapaths, so far I haven’t seen anything to suggest that these have radically changed. This continuity means that outside of its new features, GP104 behaves a lot like GM204. Though it should be noted that real world efficiency isn’t quite as cut and dry, as various factors such as the increased SM count and changes in memory technology can greatly influence this.








200 Comments
View All Comments
Ryan Smith - Wednesday, July 20, 2016 - link
To follow: GTX 1060 Review (hopefully Friday), RX 480 Architecture Writeup/Review, and at some point RX 470 and RX 460 are still due.Chillin1248 - Wednesday, July 20, 2016 - link
Nice, don't worry about the rushers. There are plenty of day one reviewers, but few go into depth the way that makes it interesting.retrospooty - Wednesday, July 20, 2016 - link
Agreed, this is a good review, as the video card reviews here usually are... Agreed about rushing as well. A lot of sites have less thorough stuff out in 1-2 days... I am guessing that Ryan and the others at Anandtech have regular day jobs and doing these reviews and articles is done on their own time. If that is the case, 2 months seems right. If I am incorrect in that assumption and this is a full time job, then they should be coming out with articles alot faster.JoshHo - Wednesday, July 20, 2016 - link
Currently for mobile the only full time editor is Matt Humrick.AndrewJacksonZA - Wednesday, July 20, 2016 - link
Thank you Ryan. I look forward to more and reliable information about the 470 and especially the 460.prophet001 - Wednesday, July 20, 2016 - link
Hi All, I was just wondering if it's worth it to get the FE 1080 or just go with the regular one. Does the stock fan setup offer better thermals than the blower setup?Teknobug - Wednesday, July 20, 2016 - link
FE is a ripoffImSpartacus - Wednesday, July 20, 2016 - link
It's literally just the reference card. It's not a bad reference design, but it's generally considered a poor value for enthusiasts.HomeworldFound - Wednesday, July 20, 2016 - link
A reference design is very useful if you're watercooling though.trab - Wednesday, July 20, 2016 - link
Depends if your custom board has any actual changes, it may just be the reference board with a custom cooler, so it would make no difference. Of course it would also be cheaper to boot.