Original Link: https://www.anandtech.com/show/2481
Opening the Kimono: Intel Details Nehalem and Tempts with Larrabee
by Anand Lal Shimpi on March 17, 2008 5:00 PM EST- Posted in
- CPUs
Prior to its Intel Developer Forum, Intel is revealing a bit more detail on some new products coming down the pipeline - including Nehalem and Larrabee.

IDF is going to be all about scaling Intel Architecture from milli watts all the way up to Peta FLOPs. This is clearly a reference to the Intel Atom on the milli watts side and new high end quad-core Itanium and Larrabee products on the Peta FLOPs side.
First up is Intel's quad-core Itanium product, codenamed Tukwila:

Tukwila is Intel's first chip with a full 2 billion transistors and should be shipping by the end of this year, with full systems available next year. Tukwila, like Nehalem, will support Intel's QuickPath Interconnect (QPI), a point-to-point interconnect similar to AMD's Hyper Transport. Also like Nehalem, Tukwila will feature an integrated memory controller - two in this case.
Next up was the Intel Dunnington processor, a 45nm 6-core Xeon part based on Penryn cores:

With 6 cores (3 dual-core pairs on a single die) and a massive 16MB shared L3 cache, Dunnington is close to Tukwila in transistor count, weighing in at a whopping 1.9 billion transistors. Dunnington is the first shipping product to come out of Intel's India Design Team based out of Bangalore, India.
Architecturally there's not much difference between Dunnington and current Penryn based Xeon parts, you simply get more cores and a very large L3 cache shared by all of the cores. Designing such a beast isn't an insignificant effort, but it's made easier because when Intel designs a core it designs everything up to but not including the L2 cache. The L2 and everything external to it is referred to as the "uncore" and is made somewhat modular, although not quite to the same degree as Nehalem.
Dunnington is the first step in Intel implementing a very Phenom-like cache architecture with its future Core products, culminating in Nehalem.

Nehalem supports QPI and features an integrated memory controller, as well as a large, shared, inclusive L3 cache.

Nehalem is a modular architecture, allowing Intel to ship configurations with 2 - 8 cores, some may have integrated graphics and with various memory controller configurations.

Nehalem allows for 33% more micro-ops in flight compared to Penryn (128 micro-ops vs. 96 in Penryn), this increase was achieved by simply increasing the size of the re-order window and other such buffers throughout the pipeline.
With more micro-ops in flight, Nehalem can extract greater instruction level parallelism (ILP) as well as support an increase in micro-ops thanks to each core now handling micro-ops from two threads at once.
Despite the increase in ability to support more micro-ops in flight, there have been no significant changes to the decoder or front end of Nehalem. Nehalem is still fundamentally the same 4-issue design we saw introduced with the first Core 2 microprocessors. The next time we'll see a re-evaluation of this front end will most likely be 2 years from now with the 32nm "tock" processor, codenamed Sandy Bridge.
Nehalem also improved unaligned cache access performance. In SSE there are two types of instructions: one if your data is aligned to a 16-byte cache boundary, and one if your data is unaligned. In current Core 2 based processors, the aligned instructions could execute faster than the unaligned instructions. Every now and then a compiler would produce code that used an unaligned instruction on data that was aligned with a cache boundary, resulting in a performance penalty. Nehalem fixes this case (through some circuit tricks) where unaligned instructions running on aligned data are now fast.
In many applications (e.g. video encoding) you're walking through bytes of data through a stream. If you happen to cross a cache line boundary (64-byte lines) and an instruction needs data from both sides of that boundary you encounter a latency penalty for the unaligned cache access. Nehalem significantly reduces this latency penalty, so algorithms for things like motion estimation will be sped up significantly (hence the improvement in video encode performance).
Nehalem also introduces a second level branch predictor per core. This new branch predictor augments the normal one that sits in the processor pipeline and aids it much like a L2 cache works with a L1 cache. The second level predictor has a much larger set of history data it can use to predict branches, but since its branch history table is much larger, this predictor is much slower. The first level predictor works as it always has, predicting branches as best as it can, but simultaneously the new second level predictor will also be evaluating branches. There may be cases where the first level predictor makes a prediction based on the type of branch but doesn't really have the historical data to make a highly accurate prediction, but the second level predictor can. Since it (the 2nd level predictor) has a larger history window to predict from, it has higher accuracy and can, on the fly, help catch mispredicts and correct them before a significant penalty is incurred.
The renamed return stack buffer is also a very important enhancement to Nehalem. Mispredicts in the pipeline can result in incorrect data being populated into Penryn's return stack (a data structure that keeps track of where in memory the CPU should begin executing after working on a function). A return stack with renaming support prevents corruption in the stack, so as long as the calls/returns are properly paired you'll always get the right data out of Nehalem's stack even in the event of a mispredict.

Nehalem will support 2-way SMT (two threads per core), much like the Pentium 4 did before it. With a shorter pipeline than NetBurst and a greater ability to get data to the cores, there's more opportunity for increased parallelism (and thus performance) thanks to SMT on Nehalem than on Pentium 4.

The cache subsystem of Nehalem is almost entirely changed from Penryn. While Nehalem has the same 32KB L1 instruction and data caches of Penryn, the L2 and L3 caches are brand new. Each core in a quad-core Nehalem now has a smaller 256KB L2 cache, which Intel is calling "low latency" (potentially lower latency than Penryn thanks to a smaller cache size). While ditching the shared L2, Intel equipped Nehalem with a large 8MB fully-shared L3 cache that can be used by all cores.
This setup seems very similar to AMD's Phenom architecture, obviously built on Intel's Core 2 base however - the major difference here is that the cache hierarchy is inclusive and not exclusive like AMD's. The inclusive architecture means that each level of cache has a copy of data from the lower cache levels.
Nehalem effectively includes the only remaining advantages AMD held over Intel with respect to memory performance and interconnect speed - you can expect a tremendous performance increase going from Penryn to Nehalem because of this. Intel is expecting memory accesses to be around twice the speed in Nehalem as they are in Penryn, which thanks to its aggressive prefetchers are already incredibly fast. If you think Intel's performance advantage is significant today, Nehalem should completely redefine your perspective - AMD needs its Bobcat and Bulldozer cores if it is going to want to compete.
Intel has also added a new 2nd level TLB in Nehalem, similar in approach to its new 2nd level branch predictor. The first level TLB does a good job of keeping the cores fed quickly, but if there isn't a physical/virtual address mapping found in the first level TLB Nehalem can now look in the second level TLB instead of looking in the cache to keep performance high and latency low.
The TLB enhancements in particular look to be particularly great at server workloads, we suspect that Intel may be looking to really take on Opteron with Nehalem.

Above you see examples of the first Nehalem platforms - they should look very familiar to block diagrams of AMD K8 platforms we've seen for years now. The first high end desktop Nehalem parts will have an integrated 3-channel DDR3 memory controller supporting DDR3-800, 1066 and 1333.

On the server side you'll see registered memory support from Nehalem's IMC.
Intel also provided a small update on its 32nm processors, Westmere (a 32nm die shrink to Nehalem) and Sandy Bridge (32nm, brand new architecture):

Details on Westmere were light, but Intel did detail that they'd be introducing new vector instructions with the CPU:

The Intel Advanced Vector Extensions (AVX) will not be available in Westmere. Instead, we will have to wait for Sandy Bridge which will offer support for 256-bit vector operations. Intel will detail the full instruction specs at its upcoming IDF in China.
The final topic of discussion today was Larrabee, Intel's highly parallel microprocessor architecture that lends itself very well to 3D graphics applications:

Larrabee will be out in the 2009 - 2010 timeframe, most likely as a standalone GPU to compete with offerings from AMD and NVIDIA. The architecture is a many-core design, with many very small, simple IA cores behind a brand new cache architecture:

Each core will support a new vector instruction set that Intel has been working with game developers to perfect. Each core will obviously have a very wide vector processing unit, but Intel isn't detailing much more on Larrabee. You can expect Larrabee to support both DirectX and OpenGL, but it will truly shine if game developers target its ISA directly.

In the usual Intel fashion, it had systems based on Nehalem and Dunnington up and running live demos:

Above we have a one socket, 4 core (8 thread) Nehalem system running a custom graphics demo:
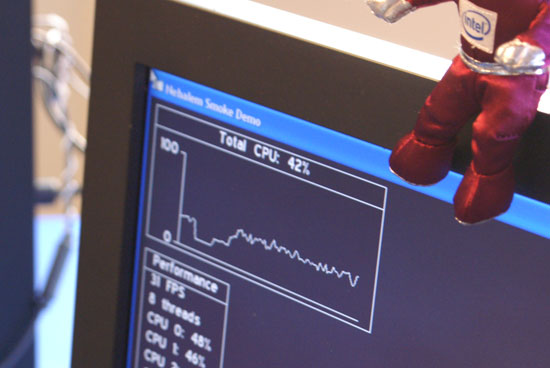
Intel avoided running any real benchmarks most likely to prevent us drawing any early conclusions. Clock speeds weren't reported, but given the transistor counts of Nehalem we'd expect similar clocks to what we've seen with Penryn.
Here we have a two socket Nehalem system, that's 8 cores, 16 threads: