Original Link: https://www.anandtech.com/show/1909
SUN’s UltraSparc T1 - the Next Generation Server CPUs
by Johan De Gelas on December 29, 2005 10:03 AM EST- Posted in
- CPUs
Introduction
SUN's Ultrasparc T1, formerly known as Niagara, is much more than just a new UltraSparc. It is the harbinger of a new generation of CPUs, which focus almost solely on Thread Level Parallelism. No less than 32 independent parts of a different program (threads) can be "in flight" on the chip. It is SUN's first implementation of their Throughput computing philosophy, and compared to what we are used to in the AMD/Intel world, it is a pretty extreme architecture that focuses on network and server performance.

Fig 1. The 2U SUN T2000
Stubborn Server applications
The basic idea behind the UltraSparc T1 is that most modern superscalar Out-Of-Order CPUs may be excellent for games, digital content creation and scientific calculations, but they are not a good match for commercial server loads.
These complex CPUs can decode up to 3 (Opteron) to 8 (Power 5) instructions in parallel, put in a buffer and try to issue them across 9 or more units. In theory, these CPUs can decode, issue, execute and retire up to 3 (Opteron) to 5 (IBM Power) instructions per clock cycle. They have huge buffers (up to 200 instructions) to keep many instructions in flight.
Server workloads, however, cannot make good use of all this parallelism for several reasons. The main reason is that commercial server loads move a lot of data around and perform relatively little calculation on that data. Moving a lot of data around means that you may need a lot of accesses to the memory, which results in many cycles wasted while the CPU has to wait for the data to arrive. As many different users query different parts of the database, caching cannot be as efficient (low locality of reference). In the past years, memory latency has become worse as memory speed increased a lot slower than the speed of the CPU. Memory latency is even worse on MP (Multi-Processor) systems, and has risen from a few tens of CPU cycles to 200-400 clock cycles. The second reason is that many of the calculations performed on that data involve data dependent (read: hard to predict) branches, which makes it even harder to do a lot in parallel.
You might counter these two problems by eliminating the branches through predication and incorporate very large caches. That is what the Itanium family does, but even the mighty Itanium is not capable of running those server loads at high speeds despite predication and gigantic caches. Below, you can see Intel's own numbers for CPU utilization on the 3 different workloads.
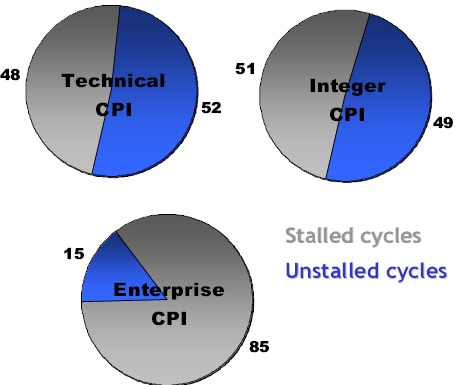
Fig 2: Intel reporting the percentage of stalled cycles of different applications on the Itanium 2 family. Source:Intel.
The applications that can be found inside Spec Integer benchmark are still rather compute-intensive compared to server applications. Compression, FPGA Circuit Placement and Routing, Compiling and interpreting, and computer visualization are representatives of very CPU intensive integer loads. On average, the best desktop CPUs such as the Athlon 64 or Intel Dothan are capable of sustaining 0.8 to 1 instructions per clock cycle in this benchmark, while the Pentium 4 is around 0.5-0.7 IPC. Itanium is capable of a 1.3-1.5 IPC. That may sound like very low numbers, but let us compare SpecInt with typical server loads. In the table below, you find how the 4-way superscalar USIIIi does on the various benchmarks.
| Benchmark | IPC |
| SPECint | 0.9 |
| SPECjbb | 0.5 |
| SPECweb | 0.3 |
| TPC-C | 0.2 |
Rather than focus on the absolute numbers, it is more important to note that web applications have 3 times less IPC than CPU intensive integer apps. OLTP databases (TPC-C) do even worse: the CPU sustains on average 0.2 instructions per clock pulse, or 4.5 less than SpecInt. These numbers are no different for the Opteron or Xeon. So despite Out of Order execution, nifty branch prediction schemes and big caches, commercial server loads utilize a very meagre 10 to 15% of the potential of modern CPUs.
One possible solution is to focus on clock speed instead of trying to process as many instructions in parallel (ILP, instruction level parallelism). The long pipelines of such CPUs make the branch prediction problem worse, and the power consumption goes up exponentially as we discussed in a previous article about dynamic power and power leakage.
Thread Machine Gun
Besides hard-to-predict branches and high memory latency, server applications on MP systems also get slowed down by high latency network communication and cache coherency (keeping all the data coherent across the different caches; read more here).
To summarize, the challenges and problems that server CPUs face are:
- Memory latency, load to load dependencies
- Branch misprediction
- Cache Coherency overhead
- Keeping Power consumption low
- Latency of the Network subsystem
Memory latency is by far the worst problem, causing a typical server CPU to be idle for 75% of the time. So, this is the first problem that the SUN/Afara engineers attacked.
The 8 cores of the 64 bit T1 can process 8 instructions per cycle, each of a different thread, so you might think that it is a just a massive multi-core CPU. However, the register file of each core keeps track of 4 different active threads contexts. This means that 4 threads are "kept alive" all the time by storing the contents of the General Purpose Registers (GPR), the different status registers and the instruction pointer register (which points to the instruction that should be executed next). Each core has a register file of no less than 640 64-bit registers, 5.7 KB big. That is pretty big for a register file, but it can be accessed in 1 cycle.
Each core has only one pipeline. During every cycle, each core switches between the 4 different active threads contexts that share a pipeline. So at each clock cycle, a different thread is scheduled on the pipeline in a round robin order; to put it more violently: it is a machine gun with threads instead of bullets.
In a conventional CPU, such a switch between two threads would cause a context switch where the contents of the different registers are copied to the L1-cache, and this would result in many wasted CPU cycles when switching from one thread to another thread. However, thanks to the large register file which keeps all information in the registers and Special Thread Select Logic, a context switch doesn't require any wasted CPU cycles. The CPU can switch between the 4 active threads without any penalty, without losing a cycle. This is called Fine Grained Multi-threading or FMT.
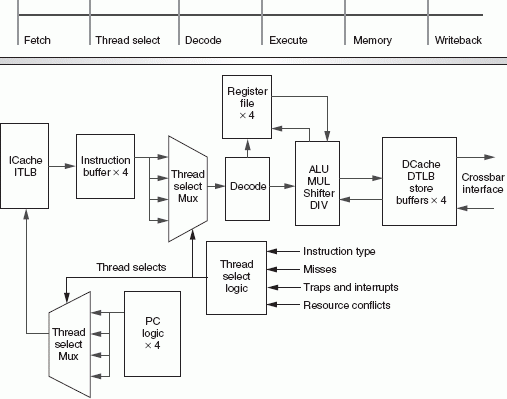
Fig 3: The SUN T1 Pipeline. Source:SUN [1].
If a branch is encountered, no branch prediction is performed: it would only waste power and transistors. No, the condition on which the branch is based is simply resolved. The CPU doesn't have to guess anymore. The pipeline is not stalled because other threads are switched in while the branch is resolved. So, instead of accelerating the little bit of compute time (10-15%) that there is, the long wait periods (memory latencies, branches) of each thread is overlapped with the compute time of 3 other threads.
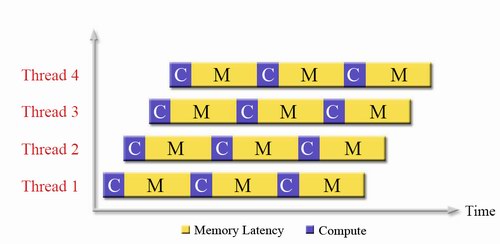
Fig 4: Fine Grained Chip Multi-threading in action. Source:SUN.
So, one core gets an IPC of about 0.7, which is very roughly twice as good as a big 3-way superscalar CPU with branch prediction and big OOO buffers would do, and it takes less chip logic to accomplish.
The 8 little cores that could
Each core is pretty small, as it has only one pipeline, no Branch Prediction Unit, no OOO buffers, and no OOO pipeline stages, which search for independent instructions. Only the large register file and thread select logic make the very simple core a bit fatter and more complex.
An 8 KB data cache and 16 KB instruction cache give an L1-hitrate of 90% or less, but it also helps to keep each core small. To keep 8 cores with such tiny L1-caches running at 70% efficiency with so many threads, a big L2-cache and massive memory bandwidth is needed.
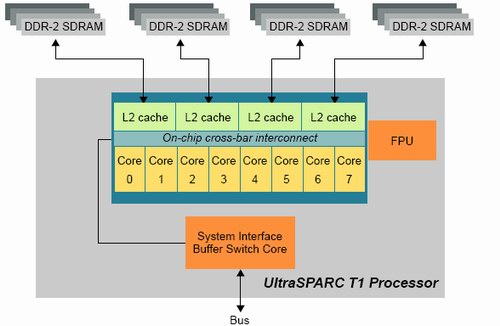
Fig 5: 8 cores fed by a 3 MB L2-cache and 4 integrated memory controllers. Source:SUN.
We have quantified this effect of faster cache coherency in our Linux database server article. A dual core Opteron was about 13% faster than two single core CPUs at the same clock speed. With 8 cores that might share data, cache coherency has an even bigger impact on performance. Sharing the L2-cache also ensures that no coherency traffic is necessary on the level 2 cache.
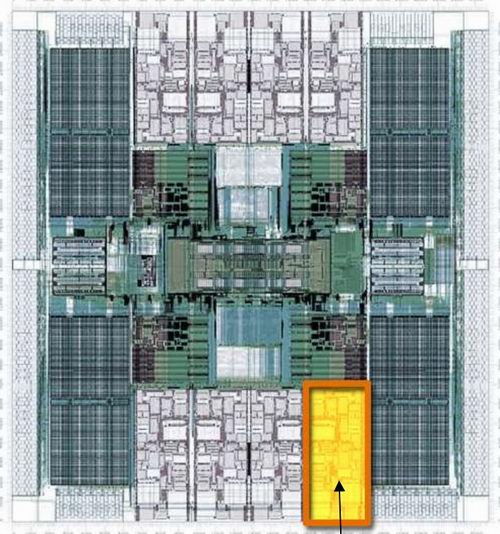
Fig 6: One (yellow) of the 8 cores (gray) of the T1. Source:SUN.
As a rough guideline, performance degrades if the number of floating-point instructions exceeds 1 percent of total instructions.Some instructions like division have long latencies, causing the thread to be skipped. The situation is then similar to a thread with a long latency load. To keep power consumption and die size per core low, each core has a very shallow six-stage pipeline: fetch, thread select, decode, execute, memory, and write back. The result is an architecture that does not need branch prediction, thanks to a shallow pipeline and FMT. However, this limits clock speed to 1.2 GHz in 90 nm, while competing chips are clocking between 2 and 4 GHz.
There is more. Each core has a modular arithmetic unit (MAU) that supports modular multiplication and exponentiation to speed up Secure Sockets Layer (SSL) processing. This compensates for the lack of the FPU and the low clock speed. A single 1.2 GHz MAU seems to "sign" as fast as a 1.8 GHz Opteron, but quite a bit slower at verifying authenticity.
The SUN benchmarks ...
Although we haven't run benchmarks yet, the benchmarks that SUN presents[2] are still interesting. We'll delve deeper once we have our own benchmarks. The power consumption numbers are estimates. We tried to give you both the typical and the maximum values. Some manufacturers give only typical numbers (Intel, IBM) while others only give maximum numbers (AMD), so we had to find other sources and base our estimates upon them.
JBB2005 represents an order processing application for a wholesale supplier written in Java.
Specjbb2005
| System | CPU | Power Dissipation CPUs (Estimated) | Number of cores | Number of Active threads | Score | Percentage score |
| Sun Fire T2000 | 1x 1.2GHz UltraSPARC T1 | 72-79 W | 8 | 32 | 63,378 | 160% |
| Sun Fire X4200 | 2x 2.4GHz DC Opteron | 150-180 W | 4 | 4 | 45,124 | 114% |
| IBM p5 550 | 2x 1.9GHz POWER5+ | 320-360 W | 4 | 8 | 61,789 | 156% |
| IBM xSeries 346 | 2x 2.8GHz DC Xeon | 270-300 W | 4 | 8 | 39,585 | 100% |
The performance of the T1 is simply amazing. Of course, this is an ideal benchmark for the T1 with many java threads. The Power 5+ is the only one that comes close, as it can process 8 threads simultaneously just like the T1. But it consumes +/- 4 times more than the T1.
SPECweb2005 emulates users sending browser requests over broadband Internet connections to a web server. It provides three new workloads: a banking site (HTTPS), an e-commerce site (HTTP/HTTPS mix), and a support site (HTTP). Dynamic content is implemented in PHP and JSP.
Specweb2005
| System | Processors | Power Dissipation CPUs (Estimated) | Number of cores | Number of Active threads | Score | Percentage score |
| Sun Fire T2000 | 1x 1.2GHz UltraSPARC T1 | 72-79 W | 8 | 32 | 14,001 | 289% |
| IBM p5 550 | 2x 1.9GHz POWER5+ | 320-360 W | 4 | 8 | 7,881 | 162% |
| IBM xSeries 346 | 2x 3.8GHz Xeon | 220-260 W | 4 | 4 | 4,348 | 90% |
| Dell 2850 | 2x 2.8GHz DC Xeon | 260-300 W | 4 | 8 | 4,85 | 100% |
Here, the T1 is by far the best CPU. This is, however, a very hard to interpret benchmark. For example, back in 2003, I did some benchmarking on a JSP server. Our first results were very weird: a single Xeon performed just as well as a dual Xeon, despite the fact that the Gigabit PCI NIC was not at its limits at all (about 180 Mbit/s). Once we used an Intel NIC, things became better, but the network bottleneck wasn't gone before we used a CSA (directly connected to the Northbridge) Intel NIC. The benchmark depends more on the quality of the NIC driver, the latency from the NIC to the memory (DMA) and of course, the quality of the NIC chip itself than on the CPU. That being said, it is clear that Web servers spawn a lot of threads that do not require a lot of processing unless they are encrypted. So, this is the natural habitat of the T1 CPU. As long as you can make sure that the CPU is the bottleneck, the CPU which can perform the most threads per cycle will win.
SAP 2 Tier is based on the number one ERP software. The database back-end and application run on the same machine.
| System | Processors | Power Dissipation CPUs (Estimated) | Number of cores | Number of Active threads | Score | Percentage score |
| Sun Fire T2000 | 1x 1.2GHz UltraSPARC T1 | 72-79 W | 8 | 32 | 4780 | 97% |
| IBM p5 550 | 2x 1.9GHz POWER5+ | 320-360 W | 4 | 8 | 5020 | 102% |
| HP DL580 | 4x 3.33GHz Xeon MP | 440-520 W | 4 | 8 | 4700 | 96% |
| HP DL385 | 2x 2.2GHz DC Opteron | 140-180 W | 4 | 4 | 4920 | 100% |
SAP 2-tier is a typical example of a benchmark with very low IPC. However, some of the queries are more complex, so the T1 cannot outperform the fatter cores. Still, the performance per watt is unbeatable.
Unbeatable?
The words "paradigm shift" and "disruptive" technology have been abused so many times that we don't like to use them. But in the case of the T1 CPU, it wouldn't be exaggerated to say that it is the herald of a new generation of server CPUs, and that it has disrupted the server market. Single core, single threaded CPUs do not have a chance in this market anymore. Does this also signal the end of superscalar CPUs in the server environment? Is the massive multi-core with scalar cores the future for the entire server world? The SUN UltraSparc T1 simply wipes the floor with the competition when it comes to performance per Watt. According to this metric, the UltraSparc T1 is 4 to 12 times better.

Fig 7: The cores of the T1 processor are hardly warmer than the rest of the die. A "fat" core has much more hotspots.
These kinds of CPUs consume quite a bit more power, but as long as this extra power usage is not dramatically higher, fat cores might still have a good chance in the market. After all, it is total system power that counts, and large RAID arrays and AC units often represent larger power draws than just the CPU. With the exception of the web server market, power consumption is not the number one priority most of the time, although it is important.
A study sponsored by SUN[3] shows that the best results in commercial server loads are achieved with 4 to 6 threads per core, combined with 2 to 3-way superscalar in order cores. This is another indication that there is a lot of room for very different multi-core approaches such as Intel's Montecito, IBM Power 6+ and upcoming multi-core Xeons and Opterons. A multi-threaded 64-bit version of Sossaman (31 Watt TDP per two cores) could also threaten the UltraSparc T1.
In some server related markets, fat multi-cores might even be more preferable. Once such market is the OLAP databases, where very complex queries are sent by a limited number of users. The response time of the T1 could be rather mediocre there, while a higher clocked CPU with fewer cores could be quite a bit more responsive in these loads. Also, OLAP queries that calculate statistical data will use more FP instructions.
Virtualization
Virtualization is an important trend in the server world. Our own experiences with it (for example, VMWare ESX server and MS Virtual Server) show that it is not completely ready for prime time. As an example, we experienced a crash of the Console OS, the linux based OS that controls the Virtual Layer. There is also no support for a 64-bit Guest OS, the OS needs to be binary translated and so on. All this will change with the introduction of hardware supported Virtualization.
The UltraSparc T1 has support for a Hypervisor, which is IBM talk for Virtual Monitor or the virtual layer that runs under the Guest OS. Solaris has excellent support for containers or zones. These are software based partitions[4] in Solaris, and the objective is similar to virtualization: high isolation. Each zone can be individually re-booted, dynamically created and errors in one zone won't affect other zones. This makes the T1 even more suited as a host for multiple tens of websites supporting different clients, as each web server can run in a separate zone on the Solaris OS.
However, when it comes to running different OS, Intel has the advantage. VMWare is going to introduce several server products that make use of Intel's VT technology, and Vmware workstation, Xen and MS Virtual Server can already use Intel's VT technology. (It must be noted that MS Virtual Server is not really a Virtual Machine Monitor as Xen and VMWare ESX server: it needs Windows 2003 or XP to run). So, Intel has the advantage in this arena, while SUN is apparently working hard to get Xen and Linux support for the T1.
Niagara 2
Right now, SUN is definitely a few steps ahead of the competition and it is not sitting still. The 65 nm Niagara 2 is due in 2007 and will feature a slightly higher clock speed (1.4 GHz and higher) and two pipelines [3] per core instead of one. Combined with 8 threads per core, this should allow the new CPU to achieve nearly twice as high IPC per core. The integration will go one step further: X8 PCI Express, a multi-port Gbit Ethernet switch, and more encryption hardware support will be integrated in Niagara-2. The integrated memory controller will also support fully buffered DIMMs.
Based on the technology in the current T1, SUN seems to be on schedule, and they are creating some very compelling designs. There are certainly many ways to tackle computing problems, and it's good to see some new approaches other than the standard "more cache" and "higher clock speeds" that are so common.
References
[1] NIAGARA: A 32-WAY MULTITHREADED SPARC PROCESSOR
- Poonacha Kongetira,Kathirgamar Aingaran, Kunle Olukotun, Sun Microsystems
[2] SUN T1 benchmarks
http://www.sun.com/servers/coolthreads/t1000/benchmarks.jsp [3] Maximizing CMP Throughput with Mediocre Cores - John D. Davis, James Laudon†, Kunle Olukotun
[4] Solaris 10 - What's coming in 2004- Chris Rijk
http://www.aceshardware.com/read_news.jsp?id=75000449 [5] Niagara, a Torrent of threads- Chris Rijk
http://www.aceshardware.com/read.jsp?id=65000292 [6] APPLICATIONS ON ULTRASPARC T1 CHIP MULTITHREADING SYSTEMS
Denis Sheahan, UltraSPARC T1 Architecture Group






