Original Link: https://www.anandtech.com/show/1702
No more mysteries: Apple's G5 versus x86, Mac OS X versus Linux
by Johan De Gelas on June 3, 2005 7:48 AM EST- Posted in
- Mac
Introduction
It is a professional 64 bit Dream machine with supersonic speed! It is beautiful. It is about the ultimate user friendliness. It is about a lifestyle. It is a class apart. You guessed it - I am parroting Apple’s marketing.For some reason, the performance of Apple’s gorgeous machines has been wrapped in a shroud of mystery. Yes, you could find a benchmark here and there, with one benchmark showing that the PowerMac is just a mediocre PC while another shows it off as a supercomputer, the unchallenged king of the personal computer world.

If you like a less performance-obsessed article about Apple, OS X and the G5, you should definitely give Anand’s articles in the Mac section on AnandTech a read...
In this article, you will find a pedal to the metal comparison of the latest Xeon DP 3.6 GHz (Irwindale), Opteron 250, Dual G5 2.5 GHz and Dual G5 2.7 GHz.
Scope and focus
Apple’s PowerMac is an alternative to the x86 PC, but we didn’t bother testing it as a gaming machine. Firstly, you have to pay a big premium to get a fast video card – as a standard, you get the ATI Radeon 9650 - even on the high-end PowerMacs. Secondly, there are fewer games available on this platform than on the x86 PC. Thirdly, hardcore gamers are not the ones buying Apples, but rather, creative professionals.So, we focus on workstation and server applications, especially the open source ones ( MySQL, Apache) as Apple is touting heavily on how important their move to an “open source foundation” is.
The 64 bit Apple Machines were running OS X Server 10.3 (Panther) and OS X Server 10.4.1 (Tiger), while our x86 machines were also running a 64 bit server version of a popular Open Source Operating Unix system: SUSE Linux SLES 9 (kernel 2.6.5). We also included an older Xeon 3.06 GHz ( Galatin, 1 MB L3) running SUSE SLES 8 (kernel 2.4.19) just for reference purposes. Some of the workstation tests were done on Windows XP SP2.
IBM PowerPC 970FX: Superscalar monster
Meet the G5 processor, which is in fact IBM's PowerPC 970FX processor. The RISC ISA, which is quite complex and can hardly be called "Reduced" (The R of RISC), provides 32 architectural registers. Architectural registers are the registers that are visible to the programmer, mostly the compiler programmer. These are the registers that can be used to program the calculations in the binary (and assembler) code.
The 970FX is deeply pipelined, quite a bit deeper than the Athlon 64 or Opteron. While the Opteron has a 12 stage pipeline for integer calculations, the 970FX goes deeper and ends up with 16 stages. Floating point is handled through 21 stages, and the Opteron only needs 17. 21 stages might make you think that the 970FX is close to a Pentium 4 Northwood, but you should remember that the Pentium 4 also had 8 stages in front of the trace cache. The 20 stages were counted from the trace cache. So, the Pentium 4 has to do less work in those 20 stages than what the 970FX performs in those 16 or 21 stages. When it comes to branch prediction penalties, the 970FX penalty will be closer to the Pentium 4 (Northwood). But when it comes to frequency headroom, the 970FX should do - in theory - better than the Opteron, but does not come close to the "old" Pentium 4.
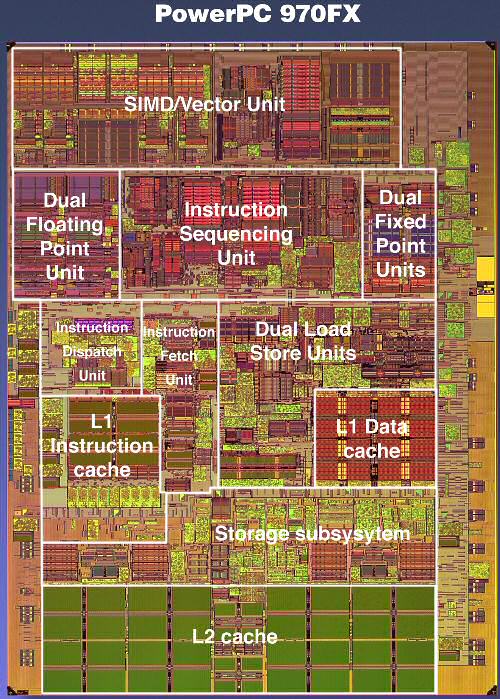
The 970FX works out of order and up to 200 instructions can be kept in flight, compared to 126 in the Pentium 4. The rate at which instructions are fetched will not limit the issue rate either. The PowerPC 970 FX fetches up to 8 instructions per cycle from the L1 and can decode at the same rate of 8 instructions per cycle. So, is the 970FX the ultimate out-of-order CPU?
While 200 instructions in flight are impressive, there is a catch. If there was no limitation except die size, CPUs would probably keep thousands of instructions in flight. However, the scheduler has to be able to pick out independent instructions (instructions that do not rely on the outcome of a previous one) out of those buffers. And searching and analysing the buffers takes time, and time is very limited at clock speeds of 2.5 GHz and more. Although it is true that the bigger the buffers, the better, the number of instructions that can be tracked and analysed per clock cycle is very limited. The buffer in front of the execution units is about 100 instructions big, still respectable compared to the Athlon 64's reorder buffer of 72 instructions, divided into 24 groups of 3 instructions.
The same grouping also happens on the 970FX or G5. But the grouping is a little coarser here, with 5 instructions in one group. This grouping makes reordering and tracking a little easier than when the scheduler would have to deal with 100 separate instructions.
The grouping is, at the same time, one of the biggest disadvantages. Yes, the Itanium also works with groups, but there the compilers should help the CPU with getting the slots filled. In the 970FX, the group must be assembled with pretty strict limitations, such as at one branch per group. Many other restrictions apply, but that is outside the scope of this article. Suffice it to say that it happens quite a lot that a few of the operations in the group consist of NOOP, no-operation, or useless "do nothing" instructions. Or that a group cannot be issued because some of the resources that one member of the group needs is not available ( registers, execution slots). You could say that the whole grouping thing makes the Superscalar monster less flexible.
Branch prediction is done by two different methods each with a gigantic 16K entry history table. A third "selector" keeps another 16K history to see which of the two methods has done the best job so far. Branch prediction seems to be a prime concern for the IBM designers.
Memory Subsystem
The caches are relatively small compared to the x86 competition. A 64 KB I-cache and 32 KB D-cache is relatively "normal", while the 512 KB L2-cache is a little small by today's standards. But, no complaints here. A real complaint can be lodged against the latency to the memory. Apple's own webpage talks about 135 ns access time to the RAM. Now, compare this to the 60 ns access time that the Opteron needs to access the RAM, and about 100-115 ns in the case of the Pentium 4 (with 875 chipset).A quick test with LM bench 2.04 confirms this:
| Host | OS | Mem read (MB/s) | Mem write (MB/s) | L2-cache latency (ns) | RAM Random Access (ns) |
| Xeon 3.06 GHz | Linux 2.4 | 1937 | 990 | 59.940 | 152.7 |
| G5 2.7 GHz | Darwin 8.1 | 2799 | 1575 | 49.190 | 303.4 |
| Xeon 3.6 GHz | Linux 2.6 | 3881 | 1669 | 78.380 | 153.4 |
| Opteron 850 | Linux 2.6 | 1920 | 1468 | 50.530 | 133.2 |
Memory latency is definitely a problem on the G5.
On the flipside of the coin is the excellent FSB bandwidth. The G5/Power PC 970FX 2.7 GHz has a 1.35 GHz FSB (Full Duplex), capable of sending 10.8 GB/s in each direction. Of course, the (half duplex) dual channel DDR400 bus can only use 6.4 GB/s at most. Still, all this bandwidth can be put to good use with up to 8 data prefetch streams.
Summary: the cores compared
Below, you find a comparison of the Intel Xeon/Pentium 4, the Opteron/Athlon 4, the G5 and the previous CPU in the Apple Power: the G4 of Motorola.CPU feature |
Motorola G4+ |
G5 (IBM PowerPC 970) |
Intel Xeon P4 Irwindale |
AMD Opteron Troy |
Process technology |
0.18 µ CU SOI |
0.09 µ CU SOI |
0.09 µ CU |
0.09 µ CU SOI |
GP Register Width (bit) |
32 |
64 |
64 |
64 |
Number of transistors (Million) |
33 |
58 |
169 |
106 |
Die Size (mm²) |
106 |
66 |
+/-130 (112 for 1 MB L2) |
115 |
Maximum Clockspeed (MHz) |
1400 |
2700 (liquid cooled) |
3800 |
2600 |
Pipeline Stages ( fp) |
7 |
16 (21) |
31 - 39* |
12 (17) |
issue rate (Instruction per clockcycle) |
3 + 1 Branch |
4 + 1 branch |
4 ports, max. 6 (3 sustained) |
6 (3 sustained) |
Integer issue rate (IPC) |
3 + 1 Branch |
2 |
4 (3 sustained) |
3 |
Floating point issue rate (IPC) |
1 |
2 |
1 |
3 |
Vector issue rate (IPC) |
2-4 ( Altivec) |
2-4 ( Altivec, velocity) |
4 Single(SSE-2/3) |
4 Single(SSE-2/3) |
2 Double (SSE-2/3) |
2 Double (SSE-2/3) |
|||
Load & Store units |
1 |
2 |
2 |
2 |
"instructions in flight" (OOO Window) |
16 |
215 (100) |
126 |
72 |
Branch History Table size (entries) |
2048 |
16384 |
4096 |
16384 |
L1-cache (Instruction/Data) |
32 KB/32 KB |
64 KB/32 KB |
12k µops (+/- 8-16 KB)/16 KB |
64 KB/64KB |
L2-cache |
256 KB |
512 KB |
2048 KB |
1024 KB |
L3-cache |
2 MB DDR SRAM 64 bit at 1/4 th of core clock |
none |
None |
none |
Front Side Bus (MHz) |
166 |
1350 (675 DDR) |
800 (200 Quad) |
N/A |
Front Side Bus (GB/s) |
1.3 Half Duplex |
10,8 Full Duplex |
6.4 Half Duplex |
N/A |
Memory Bandwidth (GB/s) |
2.7 |
6.4 |
6.4 |
6.4 |
Core Voltage |
1.6V |
1,1V ? |
1.38V |
1.4V |
Power Dissipation |
30W at 1 GHz |
+/- 59 (Typical) -80 Watt (max) |
110 W (Typical) |
92,6W (Max) |
*31 is branch misprediction pipeline length, 39 is the length of the total pipeline including decoding stages before the trace cache.
Let us summarize: in theory, the PowerPc 970FX is a very wide, deeply pipelined superscalar monster chip, with excellent Branch prediction and fantastic features for streaming applications. And let us not forget the two parallel FPUs and the SIMD Altivec unit, which can process up to 4 calculations per clock cycle.
The disadvantages are the rather coarse way that the 970FX handles the instruction flow and the high latency to the RAM.
Enough theory. Let us see how the G5 2.5 GHz and 2.7 GHz compares to the 3.6 GHz Xeon Irwindale and Opteron 250 (2.4 GHz). The Opteron 852 arrived just a day before my deadline, but I think that you will know how the 252 performs compared to the 250. Before we tackle performance, here are a few quick notes about power dissipation.
Power to the PowerPC
How power thirsty is this PowerPC 970FX? His predecessor, the 0.13µ SOI PowerPC 970 was a pretty cool chip. It consumed about 42W at 1.8 GHz (1.3v). The newer 0.09µ SOI PowerPC 970FX CPU is reported to dissipate about 55-59W at 2.5 GHz. However, a few annotations must be made.First of all, IBM and Apple tend to increase the core voltage when running at higher clock speed. This makes the needed power increase more than linearly. For example, the 1.8 GHz PowerPC 970 consumed 42 Watt, but the 2 GHz version (both 0.13µ CPUs) needed 66 Watt.
Secondly, the TDP IBM talks about is typical , not maximum like AMD's.
Let us clarify this by checking IBM's and Apple's numbers. For the 90 nm, IBM's own documents tell us that the PowerPC 970FX only consumes 24.5 Watt at 2 GHz (1V). However, the same 0.09µ SOI PowerPC970FX is reported to consume about 55W at 2.3 GHz (1.1V?) in the Xserve, according to Apple's own website. Typically, you would expect the G5 to consume about 28 Watt (24.5 * 2.3 / 2) at 2.3 GHz, when using the 24.5 Watt at 2 GHz as a reference. Apple talks about "at most" (maximum), and IBM about "typical".
Still, that is a huge gap between "typical" and "maximum" power dissipation. The 55 Watt number seems to indicate that the core voltage must have been increased significantly at 2.3 GHz. The maximum power dissipation of the 2.5/2.7 GHz G5 inside the liquid-cooled PowerMacs might thus be quite a bit higher than in the 1U Xserve, probably around 80 Watt for the 2.7 GHz. That is a lot of power for a 66 mm² CPU, and it probably explains why Apple introduced liquid cooling. The liquid cooling system inside our PowerMac wouldn't get warm and wouldn't be necessary at all if the two 2.5 GHz CPUs were only dissipating a 59 Watt maximum.
Benchmark configuration
We used the MySQL version (4.0.18) that came with the SUSE SLES9 CD's and Mac OS X Tiger 10.4.1, which was certified to work on our OS.Software: Intel, AMD
SUSE SLES 9 (SUSE Entreprise Edition) , Linux kernel 2.6.5, 64 bit.
Workstation tests: Windows XP SP2
Software: Apple PowerMac G5
OS X 10.4.1 Tiger, 64 bit (partially).
Software: common
MySQL 4.0.18, 32 and 64 bit, MyISAM engine
Gcc 3.3.3
Hardware
Here is the list of the different configurations:Apple PowerMac Dual 2.7 GHz, Dual 2.5 GHz
4 GB (8x512 MB) Corsair XMS3200 running at CAS 3-3-3
Intel® Server Board SE7520AF2
4 GB (4x1024 MB) Micron Registered DDR-II PC2-3200R, 400 MHz CAS 3, ECC enabled
NIC: Dual Intel® PRO/1000 Server NIC (Intel® 82546GB controller)
Dual Xeon DP Galatin 3.06 GHz 1 MB L3-cache, 533 MHz FSB
Intel SE7505VB2 board - Dual DDR266
2 GB (4x512 MB) Crucial PC2100R - 250033R, 266 MHz CAS 2.5 (2.5-3-3-6)
NIC: 1 Gb Intel RC82540EM - Intel E1000 driver.
Opteron Server: Dual Opteron 250 (2.4 GHz)
Iwill DK8ES Bios version 1.20
4 GB: 4x1GB MB Reg. Transcend (Hynix 503A) DDR400 - (3-3-3-6)
NIC: Broadcom BCM5721 (PCI-E)
MSI K8T Master1-FAR
4x512 MB infineon PC2700 Registered, ECC enabled
NIC: Broadcom 5705
Shared Components
1 Seagate Cheetah 36 GB - 15000 rpm - 320 MB/s
Maxtor 120 GB DiamondMax Plus 9 (7200 rpm, ATA-100/133, 8 MB cache)
Words of thanks
A lot of people gave us assistance with this project, and we like to thank them of course:Frank Balzer, IBM DB2/SUSE Linux Expert
Jasmin Ul-Haque, Novell Corporate Communications
Matty Bakkeren, Intel Netherlands
Trevor E. Lawless, Intel US
Larry.D . Gray, Intel US
Damon Muzny, AMD US

My team and I at the Technical University in the lab. Notice the slick Power Mac system behind me.
Bert Van Petegem, DB2 Expert
Ruben Demuynck, Vtune and OS X expert
Yves Van Steen, developer Dbconn
David Van Dromme, Iwill Benelux Helpdesk (http://www.iwill-benelux.com)
I also would like to thank Lode De Geyter, manager of the PIH, for letting us use the infrastructure of the TUK ( www.pih.be) to test the database servers.
Micro CPU benchmarks: isolating the FPU
But you can't compare an Intel PC with an Apple. The software might not be optimised the right way." Indeed, it is clear that the Final Cut Pro, owned by Apple, or Adobe Premiere, which is far better optimised for the Intel PC, are not very good choices to compare the G5 with the x86 world.So, before we start with application benchmarks, we performed a few micro benchmarks compiled on all platforms with the same gcc 3.3.3 compiler.
The first one is flops. Flops, programmed by Al Aburto, is a very floating-point intensive benchmark. Analyses show that this benchmark contains:
- 70% floating point instructions;
- only 4% branches; and
- Only 34% of instructions are memory instructions.
Al Aburto, about Flops:
" Flops.c is a 'C' program which attempts to estimate your systems floating-point 'MFLOPS' rating for the FADD, FSUB, FMUL, and FDIV operations based on specific 'instruction mixes' (see table below). The program provides an estimate of PEAK MFLOPS performance by making maximal use of register variables with minimal interaction with main memory. The execution loops are all small so that they will fit in any cache."Flops shows the maximum double precision power that the core has, by making sure that the program fits in the L1-cache. Flops consists of 8 tests, and each test has a different, but well known instruction mix. The most frequently used instructions are FADD (addition), FSUB (subtraction) and FMUL (multiplication). We used gcc -O2 flops.c -o flops to compile flops on each platform.
| MODULE | FADD | FSUB | FMUL | FDIV | Powermac G5 2.5 GHz | Powermac G5 2.7 GHz | Xeon Irwindale 3.6 GHz | Xeon Irwindale 3.6 w/o SSE2* | Xeon Galatin 3.06 GHz | Opteron 250 2.4 GHz |
| 1 | 50% | 0% | 43% | 7% | 1026 | 1104 | 677 | 1103 | 1033 | 1404 |
| 2 | 43% | 29% | 14% | 14% | 618 | 665 | 328 | 528 | 442 | 843 |
| 3 | 35% | 12% | 53% | 0% | 2677 | 2890 | 532 | 1088 | 802 | 1955 |
| 4 | 47% | 0% | 53% | 0% | 486 | 522 | 557 | 777 | 988 | 1856 |
| 5 | 45% | 0% | 52% | 3% | 628 | 675 | 470 | 913 | 995 | 1831 |
| 6 | 45% | 0% | 55% | 0% | 851 | 915 | 552 | 904 | 1030 | 1922 |
| 7 | 25% | 25% | 25% | 25% | 264 | 284 | 358 | 315 | 289 | 562 |
| 8 | 43% | 0% | 57% | 0% | 860 | 925 | 1031 | 910 | 1062 | 1989 |
| Average: | 926 | 998 | 563 | 817 | 830 | 1545 | ||||
The results are quite interesting. First of all, the gcc compiler isn't very good in vectorizing. With vectorizing, we mean generating SIMD (SSE, Altivec) code. From the numbers, it seems like gcc was only capable of using Altivec in one test, the third one. In this test, the G5 really shows superiority compared to the Opteron and especially the Xeons.
The really funny thing is that the new Xeon Irwindale performed better when we disabled support for the SSE-2, and used the "- mfpmath=387" option. It seems that the GCC compiler makes a real mess when it tries to optimise for the SSE-2 instructions. One can, of course, use the Intel compiler, which produces code that is up to twice as fast. But the use of the special Intel compiler isn't widespread in the real world.
Also interesting is that the 3.06 GHz Xeon performs better than the Xeon Irwindale at 3.6 GHz. Running completely out of the L1-cache, the high latency (4 cycles) of the L1-cache of Irwindale hurts performance badly. On the Galatin Xeon, which is similar to Northwood, Flops benefits from the very fast 2-cycle latency.
The conclusion is that the Opteron has, by far, the best FPU, especially when more complex instructions such a FDIV (divisions) are used. When the code is using something close to the ideal 50% FADD/FSUB and 50% FMUL mix and is optimised for Altivec, the G5 can roll its muscles. The normal FPU is rather mediocre though.
Micro CPU benchmarks: isolating the Branch Predictor
To test the branch prediction, we used the benchmark " Queens". Queens is a very well known problem where you have to place n chess Queens on an n x n board. The catch is that no single Queen must be able to attack the other. The exhaustive search strategy for finding a solution to placing the Queens on a chess board so they don't attack each other is the algorithm behind this benchmark, and it contains some very branch intensive code.Queens has about:
- 23% branches
- 45% memory instructions
- No FP operations
| RUN TIME (sec) | |
| Powermac G5 2.5 GHz | 134.110 |
| Xeon Irwindale 3.6 GHz | 125.285 |
| Opteron 250 2.4 GHz | 103.159 |
At 2.7 GHz, the G5 was just as fast as the Xeon. It is pretty clear that despite the enormous 31 stage pipeline, the fantastic branch predictor of the "Xeon Pentium 4" is capable of keeping the damage to a minimum. The Opteron's branch predictor seems to be at the level of G5's: the branch misprediction penalty of the G5 is 30% higher, and the Opteron does about 30% better.
The G5 as workstation processor
It is well known that the G5 is a decent workstation CPU. The G5 is probably the fastest CPU when it comes to Adobe After Effects and Final Cut Pro, as this kind of software was made to be run on a PowerMac. Unfortunately, we didn't have access to that kind of software.First, we test with Povray, which is not optimised for any architecture, and single-threaded.
| Povray Seconds |
|
| Dual Opteron 250 (2.4 GHz) | 804 |
| Dual Xeon DP 3.6 GHz | 1169 |
| Dual G5 2.5 GHz PowerMac | 1125 |
| Dual G5 2.7 GHz PowerMac | 1049 |
Povray runs mostly out of the L2- and L1-caches and mimics almost perfectly what we have witnessed in our Flops benchmarks. As long as there are little or no Altivec or SSE-2 optimisations present, the Opteron is by far the fastest CPU. The G5's FPU is still quite a bit better than the one of the Xeon.
The next two tests are the only 32 bit ones, done in Windows XP on the x86 machines.
| Lightwave 8.0 Raytrace |
Lightwave 8.0 Tracer Radiosity |
|
| Dual Opteron 250 (2,4 GHz) | 47 | 204 |
| Dual Xeon DP 3,6 GHz | 47.3 | 180 |
| Dual G5 2,5 GHz PowerMac | 46.5 | 254 |
The G5 is capable of competing in one test. Lightwave rendering engine has been meticulously optimised for SSE-2, and the " Netburst" architecture prevails here. We have no idea how much attention the software engineers gave Altivec, but it doesn't seem to be much. This might of course be a result of Apple's small market share.
| Cinema 4D Cinebench |
|
| Dual Opteron 250 (2.4 GHz) | 630 |
| Dual Xeon DP 3.6 GHz | 682 |
| Dual G5 2.5 GHz PowerMac | 638 |
| Dual G5 2.7 GHz PowerMac | 682 |
Maxon has invested some time and effort to get the Cinema4D engine running well on the G5 and it shows. The G5 competes with the best x86 CPUs.
The G5 as Server CPU
While it is the Xserve and not the PowerMac that is Apple's server platform, we could not resist the temptation to test the G5 based machine as a server too. Installed on the machine was the server version of Mac OS X Tiger. So in fact, we are giving the Apple platform a small advantage: the 2.5 GHz CPUs are a bit faster than the 2.3 GHz of the Xserve, and the RAM doesn't use ECC as in the Xserve.

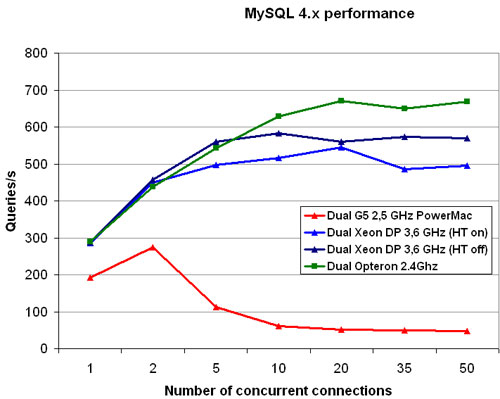
| Dual G5 2,5 GHz PowerMac | Dual Xeon DP 3,6 GHz (HT on) | Dual Xeon DP 3,6 GHz (HT out) | Dual Opteron 2.4Ghz | |
| 1 | 192 | 286 | 287 | 290 |
| 2 | 274 | 450 | 457 | 438 |
| 5 | 113 | 497 | 559 | 543 |
| 10 | 62 | 517 | 583 | 629 |
| 20 | 50 | 545 | 561 | 670 |
| 35 | 50 | 486 | 573 | 650 |
| 50 | 47 | 495 | 570 | 669 |
Performance is at that point only 1/10th of the Opteron and Xeon. We have tested this on Panther (10.3) and on Tiger (10.4.1), triple-checked every possible error and the result remains the same: something is terribly wrong with the MySQL server performance.
SPEC CPU 2000 Int numbers compiled with GCC show that the G5 reaches about 75% of the integer performance of an equally clocked Opteron. So, the purely integer performance is not the issue. The Opteron should be quite faster, but not 10 times faster.
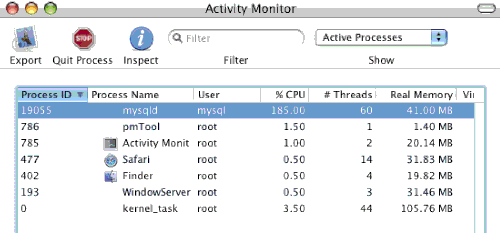
We checked with the activity monitor, and the CPUs were indeed working hard: up to 185% CPU load on the MySQL process. Notice that the MySQL process consists of no less than 60 threads.
| Concurrency | Dual Powermac G5 2.5 GHz (Panther) | Dual Powermac G5 2.7 GHz (Tiger) | Dual Xeon 3.6 GHz |
| 5 | 216.34 | 217.6 | 3776.44 |
| 20 | 216.24 | 217.68 | 3711.4 |
| 50 | 269.38 | 218.32 | 3624.63 |
| 100 | 249.51 | 217.69 | 3768.89 |
| 150 | 268.59 | 256.89 | 3600.1 |
The new OS, Tiger doesn't help: the 2.7 GHz (10.4.1) is as fast as the 2.5 GHz on Panther (10.3). More importantly, Apache shows exactly the same picture as MySQL: performance is 10 times more worse than on the Xeon (and Opteron) on Linux. Apple is very proud about the Mac OS X Unix roots, but it seems that the typical Unix/Linux software isn't too fond of Apple. Let us find out what happened!
Mac OS X: beautiful but...
The Mac OS X (Server) operating system can't be described easily. Apple:
While there are many very good ideas in Mac OS X, it reminds me a lot of fusion cooking, where you make a hotch-potch of very different ingredients. Let me explain.

Hexley the platypus, the Darwin mascot
Everything else is located in smaller programs, servers, which communicate with each other via ports and an IPC (Inter Process Communication) system. Explaining this in detail is beyond the scope of this article (read more here). But in a nutshell, a Mach microkernel should be more elegant, easier to debug and better at keeping different processes from writing in eachother's protected memory areas than our typical "monolithic" operating systems such as Linux and Windows NT/XP/2000. The Mach microkernel was believed to be the future of all operating systems.
However, you must know that applications (in the userspace) need, of course, access to the services of the kernel. In Unix, this is done with a Syscall, and it results in two context switches (the CPU has to swap out one process for another): from the application to the kernel and back.
The relatively complicated memory management (especially if the server process runs in user mode instead of kernel) and IPC messaging makes a call to the Mach kernel a lot slower, up to 6 times slower than the monolithic ones!
It also must be remarked that, for example, Linux is not completely a monolithic OS. You can choose whether you like to incorporate a driver in the kernel (faster, but more complex) or in userspace (slower, but the kernel remains slimmer).
Now, while Mac OS X is based on Mach 3, it is still a monolithic OS. The Mach microkernel is fused into a traditional FreeBSD "system call" interface. In fact, Darwin is a complete FreeBSD 4.4 alike UNIX and thus monolithic kernel, derived from the original 4.4BSD-Lite2 Open Source distribution.
The current Mac OS X has evolved a bit and consists of a FreeBSD 5.0 kernel (with a Mach 3 multithreaded microkernel inside) with a proprietary, but superb graphical user interface (GUI) called Aqua.
Performance problems
As the mach kernel is hidden away deep in the FreeBSD kernel, Mach (kernel) threads are only available for kernel level programs, not applications such as MySQL. Applications can make use of a POSIX thread (a " pthread"), a wrapper around a Mach thread.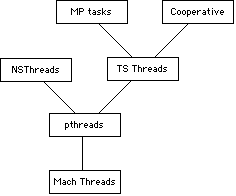
Mac OS X thread layering hierarchy (Courtesy: Apple)
In order to maintain binary compatibility, Apple might not have been able to implement some of the performance improvements found in the newer BSD kernels.
Another problem is the way threads could/can get access to the kernel. In the early versions of Mac OS X, only one thread could lock onto the kernel at once. This doesn't mean only one thread can run, but that only one thread could access the kernel at a given time. So, a rendering calculation (no kernel interaction) together with a network access (kernel access) could run well. But many threads demanding access to the memory or network subsystem would result in one thread getting access, and all others waiting.
This "kernel locked bottleneck" situation has improved in Tiger, but kernel locking is still very coarse. So, while there is a very fine grained multi-threading system (The Mach kernel) inside that monolithic kernel, it is not available to the outside world.
So, is Mac OS X the real reason why MySQL and Apache run so slow on the Mac Platform? Let us find out... with benchmarks, of course!
Mac OS X versus Linux
Lmbench 2.04 provides a suite of micro benchmarks that measure the bottlenecks at the Unix operating system and CPU level. This makes it very suitable for testing the theory that Mac OS X might be the culprit for the terrible server performance of the Apple platform.Signals allow processes (and thus threads) to interrupt other processes. In a database system such as MySQL 4.x where so many processes/threads (60 in our MySQL screenshot) and many accesses to the kernel must be managed, signal handling is a critical performance factor.
Larry McVoy (SGI) and Carl Staelin (HP):
" Lmbench measure both signal installation and signal dispatching in two separate loops, within the context of one process. It measures signal handling by installing a signal handler and then repeatedly sending itself the signal."
| Host | OS | Mhz | null | null call |
open I/O |
stat | slct clos |
sig TCP |
sig inst |
| Xeon 3.06 GHz | Linux 2.4 | 3056 | 0.42 | 0.63 | 4.47 | 5.58 | 18.2 | 0.68 | 2.33 |
| G5 2.7 GHz | Darwin 8.1 | 2700 | 1.13 | 1.91 | 4.64 | 8.60 | 21.9 | 1.67 | 6.20 |
| Xeon 3.6 GHz | Linux 2.6 | 3585 | 0.19 | 0.25 | 2.30 | 2.88 | 9.00 | 0.28 | 2.70 |
| Opteron 850 | Linux 2.6 | 2404 | 0.08 | 0.17 | 2.11 | 2.69 | 12.4 | 0.17 | 1.14 |
All numbers are expressed in microseconds, lower is thus better. First of all, you can see that kernel 2.6 is in most cases a lot more efficient. Secondly, although this is not the most accurate benchmark, the message is clear: the foundation of Mac OS X server, Darwin handles the signals the slowest. In some cases, Darwin is even several times slower.
As we increase the level of concurrency in our database test, many threads must be created. The Unix process/thread creation is called "forking" as a copy of the calling process is made.
lmbench "fork" measures simple process creation by creating a process and immediately exiting the child process. The parent process waits for the child process to exit. The benchmark is intended to measure the overhead for creating a new thread of control, so it includes the fork and the exit time.
lmbench "exec" measures the time to create a completely new process, while " sh" measures to start a new process and run a little program via /bin/ sh (complicated new process creation).
| Host | OS | Mhz | fork hndl |
exec proc |
Sh proc |
| Xeon 3.06 GHz | Linux | 3056 | 163 | 544 | 3021 |
| G5 2.7 GHz | Darwin | 2700 | 659 | 2308 | 4960 |
| Xeon 3.6 GHz | Linux | 3585 | 158 | 467 | 2688 |
| Opteron 850 | Linux | 2404 | 125 | 471 | 2393 |
Mac OS X is incredibly slow, between 2 and 5(!) times slower, in creating new threads, as it doesn't use kernel threads, and has to go through extra layers (wrappers). No need to continue our search: the G5 might not be the fastest integer CPU on earth - its database performance is completely crippled by an asthmatic operating system that needs up to 5 times more time to handle and create threads.
Workstation, yes; Server, no.
The G5 is a gigantic improvement over the previous CPU in the PowerMac, the G4e. The G5 is one of the most superscalar CPUs ever, and has all the characteristics that could give Apple the edge, especially now that the clock speed race between AMD and Intel is over. However, there is still a lot of work to be done.First of all, the G5 needs a lower latency access to the memory because right now, the integer performance of the G5 leaves a lot to be desired. The Opteron and Xeon have a better integer engine, and especially the Pentium 4/Xeon has a better Branch predictor too. The Opteron's memory subsystem runs circles around the G5's.
Secondly, it is clear that the G5 FP performance, despite its access to 32 architectural registers, needs good optimisation. Only one of our flops tests was " Altivectorized", which means that the GCC compiler needs to improve quite a bit before it can turn those many open source programs into super fast applications on the Mac. In contrast, the Intel compiler can vectorize all 8 tests.
Altivec or the velocity engine can make the G5 shine in workstation applications. A good example is Lightwave where the G5 takes on the best x86 competition in some situations, and remains behind in others.
The future looks promising in the workstation market for Apple, as the G5 has a lot of unused potential and the increasing market share of the Power Mac should tempt developers to put a little more effort in Mac optimisation.
The server performance of the Apple platform is, however, catastrophic. When we asked Apple for a reaction, they told us that some database vendors, Sybase and Oracle, have found a way around the threading problems. We'll try Sybase later, but frankly, we are very sceptical. The whole "multi-threaded Mach microkernel trapped inside a monolithic FreeBSD cocoon with several threading wrappers and coarse-grained threading access to the kernel", with a "backwards compatibility" millstone around its neck sounds like a bad fusion recipe for performance.
Workstation apps will hardly mind, but the performance of server applications depends greatly on the threading, signalling and locking engine. I am no operating system expert, but with the data that we have today, I think that a PowerPC optimised Linux such as Yellow Dog is a better idea for the Xserve than Mac OS X server.
References
Threading on OS Xhttp://developer.apple.com/technotes/tn/tn2028.html
Basics OS X
http://developer.apple.com/documentation/macosx/index.html






