Low level benchmarking on Mac OS X and Linux
Lmbench 3.0 provides a suite of micro-benchmarks that measure the bottlenecks at the Unix operating system and CPU level. We were not able to install Yellow Dog Linux on the 2.7 GHz Apple machine, although the paper specs (excluding the CPU) were exactly the same as our 2.5 GHz PowerMac. Some small chipset tweak or firmware change is probably the cause of our YDL installation failure on the newest and latest Apple PowerMac.So, we'll give Mac OS X a small advantage by running it on the 2.7 GHz and Linux on the 2.5 GHz machine. Frankly, I don't care much about an 8% clock difference, as the main goal is to find out why MySQL runs between 5 and 8 times slower on Mac OS X!
The Unix process/thread creation is called "forking" as a copy of the calling process is made. lmbench "fork" measures simple process creation by creating a process and immediately exiting the child process. The parent process waits for the child process to exit. lmbench "exec" measures the time to create a completely new process, while "sh" measures the time to start a new process and run a little program via /bin/sh (complicated new process creation).
Everything is expressed in micro seconds, lower is better.
| Host | OS | Mhz | fork hndl |
exec proc |
sh proc |
| G5 2.7 GHz | Darwin | 2700 | 659 | 2308 | 4960 |
| G5 2.5 GHz | Linux | 2500 | 182 | 748 | 2259 |
| Xeon 3.6 GHz | Linux | 3585 | 158 | 467 | 2688 |
| Opteron 850 | Linux | 2404 | 125 | 471 | 2393 |
In the previous article, I wrote: "Mac OS X is incredibly slow - between 2 and 5(!) times slower - in creating new threads, as it doesn't use kernelthreads, and has to go through extra layers (wrappers)"
Readers pointed out that there were two errors in this sentence. The first one is that Mac OS X does use kernelthreads, and this is completely true. My confusion came from the fact that FreeBSD 4.x and older - which was part of the OS X kernel until Tiger came along - did not implement kernelthreads; rather, only userthreads. It was one of the reasons why MySQL ran badly on FreeBSD 4.x and older. In the case of userthreads, it is not the kernel that manages the threads, but an application running on top of the kernel in userspace.
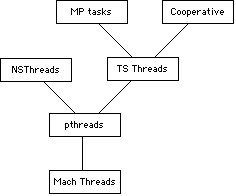
Mac OS X thread layering hierarchy (Courtesy: Apple)[1]
From Apple:
"POSIX thread (commonly referred to as a "pthread") is a lightweight wrapper around a Mach thread that enables it to be used by user-level processes. POSIX threads are the basis for all of the application-level threads."Readers also pointed out that LMBench uses "fork", which is the way to create a process and not threads in all Unix variants, including Mac OS X and Linux. I fully agree, but does this mean that the benchmark tells us nothing about the way that the OS handles threading? The relation between a low number in this particular Lmbench benchmark and a slow creating of threads may or may not be the answer, but it does give us some indication of a performance issue. Allow me to explain.
In the Unix world, threads are often described as lightweight processes. A thread is a sequential flow of control within a program, whereas a process is one or more threads plus its own (virtual) address space. Threads share the same address space and thus, share memory and can exchange information very quickly. However, it is important to understand that threads and processes are not completely different, but they are related to each other.
In the case of Linux, creating a thread is very similar to creating a process. In fact, you use the same procedure, only with different flags or parameters. Linux implements all threads as if they were standard processes. You create a new thread with the clone() call, and the necessary flags, which describe the resources (memory) to be shared. The process creation is done with fork(), but fork() is nothing less than a clone() without the flags that describe the resources that must be shared. So, if you test fork() on Linux, you also get a rough idea of how fast threads are created.
What about Mac OS X? Well, when the Mach kernel is asked to create a Unix process (fork()), the mach kernel creates a task (which describes the resources available) and one thread. So, thread creation time is included in the fork () benchmark of Lmbench.
What can we conclude from this? First, the above tables demonstrate clearly that the creation of UNIX processes is much slower on MAC OS X, and the G5, the CPU, is not to blame. In the first test, the G5 2.5 GHz running Linux is only slightly slower than a Pentium 4 at 3.6 GHz. The third test shows that the G5 is even capable of outperforming the other CPUs, which points towards Mac OS X being the problem here. Even with a faster CPU, the OS X scores are all slower than the Linux scores on the G5.
Does this give us an idea of why MySQL performs so badly? Unfortunately, it makes us suspect that not only process, but thread creation is also slow. We can suspect it, since the process creation, which includes the creation of one thread, takes up to 5 times longer. We can't prove it, as the thread creation time is a small part of the total benchmark time, and we are not sure that the time to create a thread compared to the total time is the same proportionally on both Mac OS X and Linux. LMBench gives us a rough indication that we might be right, but it doesn't give us cold hard facts. We need to look elsewhere for those.
Interprocess Communication (IPC) and Signaling
Signals allow processes (and thus threads) to interrupt other processes. Although MySQL is only one process, it must cooperate with other process via IPC. Benchmarking signal and interprocess communication latency allows to us to understand how quickly the MySQL process can cooperate with other processes and the Operating System. Contrary to workstation and gaming applications, access to the operating system and other processes is critical for database server performance. For example, our client in our database testing setup sends the queries via a Gigabit Ethernet connection (hardware - Layer 1) and via TCP-IP (Network stack Layer 2-4) to the server.Larry McVoy (SGI) and Carl Staelin (HP) on signaling:
"Lmbench measures both signal installation and signal dispatching in two separate loops, within the context of one process. It measures signal handling by installing a signal handler and then repeatedly sending itself the signal."All numbers are expressed in micro seconds; thus, lower is better.
| Host | OS | Mhz | Null | null call |
open I/O |
stat | slct clos |
sig TCP |
sig inst |
| G5 2.7 GHz | Darwin | 2700 | 1.13 | 1.91 | 4.64 | 8.6 | 21.9 | 1.67 | 6.2 |
| G5 2.5 GHz | Linux | 2500 | 0.14 | 0.26 | 3.41 | 4.16 | 18.9 | 0.38 | 1.9 |
| Xeon 3.6 GHz | Linux | 3585 | 0.19 | 0.25 | 2.3 | 2.88 | 9.0 | 0.28 | 2.7 |
| Opteron 850 | Linux | 2404 | 0.08 | 0.17 | 2.11 | 2.69 | 12.4 | 0.17 | 1.14 |
Signaling needs significantly more time in Mac OS X (Darwin) than on Linux. The processor plays a minor role: the Opteron at 2.4 GHz is a bit faster than the Xeon 3.6 GHz running exactly the same (x86) code. However, it is clear that the operating system plays a much bigger role: a 2.5 GHz G5 running Linux easily beats the identical system with a 2.7 GHz G5 running Mac OS X. Despite the FreeBSD heritage, the TCP signals are very slow (4 times slower!) on Mac OS X.
The slower signaling results likely contribute to the overall unimpressive MySQL performance. There are still other factors that also play a part. Let us check out Inter Process Communication (IPC).
| Host | OS | Pipe | AF UNIX |
UDP | TCP | TCP conn |
| G5 2.7 GHz | Darwin | 9.496 | 13.1 | 34.8 | 44.5 | 61 |
| G5 2.5 GHz | Linux | 11.6 | 16.4 | 19.1 | 19.6 | 34 |
| Xeon 3.6 GHz | Linux | 9.909 | 19.0 | 16.0 | 19.3 | 40 |
| Opteron 850 | Linux | 7.645 | 11.2 | 14.2 | 15.9 | 24 |
As TCP is connection based, you get Synchronize (SYN) and Acknowledgement (ACK) messages to establish a reliable connection, before any data can be transferred. Lmbench measures this startup time (TCP conn). Notice how the G5 performs this task quite quickly with Linux, but much slower with Mac OS X. The latency to connect to a TCP server is also measured (TCP) and Mac OS X is measured to be more than twice as slow compared to the Linux based machines, including the same G5 machine. So, although network bandwidth might not be a problem for our benchmark, network latency might have an influence.
Some studies show that there is a direct relationship between these TCP benchmarks and some aspects of Database performance. For example, it was reported that "The TCP latency benchmark is an accurate predictor of the Oracle distributed lock manager's performance." [2]








47 Comments
View All Comments
tthiel - Wednesday, May 24, 2006 - link
You need to redo this entire test. So much has come out about how poorly this was done its hard to believe it came from Anandtech.iggie - Friday, January 13, 2006 - link
I'm surprised you didn't post the raw VM latency results from lmbench. I found http://www-128.ibm.com/developerworks/library/l-yd...">another article that did a similar performance comparison (Darwin vs. Linux on G5).mmap latency is 3x greater, but most tellingly, page fault latency is > 900 x greater!
Did you observe similar results in your tests?
I would imagine that page faults would play a greater and greater role as more and more independent clients connect to a server. I have experienced a huge disparity in http://www.openmicroscopy.org/api/omeis/">our own server software implementation for scientific imaging. In our case, all disk access is done via mmap and page faults (its a shared-VM-based image server system meant to serve many terabytes of image data)
asifyoucare - Sunday, September 4, 2005 - link
Interesting article.If you suspect that thread performance is the bottleneck, why not write a short program to measure how many threads can be created and destroyed per second?
DoctorBooze - Saturday, September 3, 2005 - link
I'm no guru but I don't think that's true now with Native Posix Threads, which you get in 2.6 kernels with a suitable libc (and some distros with 2.4 kernels). Check what your program's linked with: on my Fedora Core 3 system `ldd /usr/libexec/mysqld` shows me MySQL is linked with /lib/tls/libc.so.6 and running that shows it has NPTL. The API may be similar but what happens in the kernel isn't and it makes a big, big difference to MySQL. Still, Linux now has fast native POSIX threads and it looks like OS X doesn't.
ikruusa - Saturday, September 3, 2005 - link
Indeed, as mentioned previously there was some mistakes in gcc options. And SIMD optimization is really basic in 4.0.x - only certain loops can be vectorized automatically. But loops around arrays are most significant part in signal processing and that is where SIMD really matters :)As we know for NetBurst arch it is recommended to use XMM registers (that is registers for SSE/SSE2) for FP calculations. And that is what gcc 3.x does (4.x too): -mfpmath=sse triggers all x87 stuff to run as scalar math using SSE command-set. As I know AltiVec is SIMD unit which is smoothly added to PowerPC pipeline. How useful there is scalar math instead of usual FP - I have no idea.
What I want to say - my opinion is that if MySQL team has something to say about compiler options then they have documents about it. Using SIMD style processing in DB engine is very challenging exercise for coders. Dont expect magic from compiler here. Hint: maybe Intel's own icc compiler provide some magic but you have to prove it ;) I still believe that the most useful options can be -O[2,3] -funroll-loops and -ffast-math (as you mentioned) with -arch=[processor]. The last one should provide basic branching elimination (e.g. using cmov for x86) and correct instr. ordering.
About testing Linux. I have some skills in Apache testing with JMeter. I have been quite stuck but kernel developers were kind enough to help: http://marc.theaimsgroup.com/?l=linux-kernel&m...">http://marc.theaimsgroup.com/?l=linux-kernel&m...
Then I discovered all OS tuning possibilities in /proc Well, most are still unknown for me but I just want to get your attention here. Oracle talks about shared memory and number of semaphores and some particular Linux /proc parameters. Of course there should be all written in MySQL manual too if any parameter needs tuning. But is it enough to read MySQL manual and create profile for OS'es IPC and process management if we need to stress test MySQL on e.g 8-way SMP?
But still - good start of interesting investigation, anandtech.com!! Thank you and keep going!
kvs - Saturday, September 3, 2005 - link
If thread-creation is extremely slow in Darwin, maybe MySQL-performance could be helped by enabled the thread cache? A look at 'mysqladmin extended-status' would show how many threads had been created and cached, and should reveal if thread_cache would be needed.tester2 - Friday, September 2, 2005 - link
Well if ab on Mac OS X was the problem you could have easily tested this from a Linux box over the network.Because you probably did this as well, and found out that performance tuning done by Apple outperformed the Linux/PPC and Linux/Opteron system by a substantial amount you keept this out of the story ...
So I did some testing, and yes when using ab from a Mac OS X I find the exact figures you report. Using a Linux Pentium 4 based system over Gb network gave me 6150 req/sec substantially faster then anything out there.
Look here for numbers from another source; http://www.pcmag.com/article2/0,1895,1637655,00.as...">http://www.pcmag.com/article2/0,1895,1637655,00.as...
The webserver runs around 60 threads ... go figure.
Yes there is a problem with the Mac OS X - Mysql combo if you are looking for performance, but jugging this as Mac OS X for server applications is a nono is drawing the wrong conclusion. I hope someone with good development skills will look at the mysql code and tune it to work well with Mac OS X.
benh - Friday, September 2, 2005 - link
Interesting article ! One thing that is worth looking into however is wether the YDL kernel is actually a 32 or a 64 bits kernel. This would probably have an impact on some of the numbers. I would expect the ppc64 kernel to perform faster overall on a 64 bits CPU with a small overhead on syscalls from 32 bits applications due to the argument size translation.Also, the problem with the 2.7Ghz on linux is indeed a slight change in the firmware. It in fact looks like a bug in Apple Open Firmware device tree on those machine where they left out the properties providing the interrupt routing of the i2c controller in the north bridge used to drive the fan controller among others. The OS X driver silently falls back to a polled mecanism, while the linux driver doesn't and (shame on me!) used to have a small bug that would cause it crash when unable to locate those properties.
I posted a patch a while ago fixing that up, I would expect YDL to have an updated kernel/installer available by now.
Finally, you are right about the U3 northbridge having a quite high memory latency, that is definitely not helping the G5. There have been rumours floating around that Apple now has a new bridge that improves that significantly, though it's pretty much impossible to tell if/when they will release a machine using it. IBM also had multicore G5s available for some time now, though Apple is still not releasing any machine using them.
Regards,
Ben.
JohanAnandtech - Friday, September 2, 2005 - link
Thanks for the very helpful feedback.Do you have any idea why the U3 came with such high latency. Lack of development time? Lack of expertise? A inherent problem with the FSB of the G5? Rather old technology? You see I am very curious, and couldn't find much info on it.
benh - Friday, September 2, 2005 - link
I don't know for sure. I wouldn't blame the FSB though. I remember reading somewhere that the memory controller in U3 was similar if not identical to the old one they used in U2 on G4 machines and was to blame but I can't guarantee the reliability of that information.