The Quest for More Processing Power, Part Three: "Multi core of Intel and AMD compared"
by Johan De Gelas on May 18, 2005 3:15 PM EST- Posted in
- CPUs
SMT Dead?
Simultaneous Multi Threading has been receiving quite a bit of criticism over the past months. Rumours about the demise of Hyper Threading were started, and Fred Weber of AMD even called it "a misuse of resources".The reason why SMT was no longer considered "cool" was because of the very mediocre performance increase that the Pentium 4 gained from Hyper Threading. In fact, we are still encountering applications where Hyperthreading decreases performance.
Anand reported in his "AMD's Athlon 64 X2 4800+ & 4200+ Dual Core Performance Preview":
"The other thing we continue to see is that dual core with Hyper Threading in these multitasking environments is very much the double-edged sword. There are some situations where having both Hyper Threading and dual core gives Intel a huge performance boost, but there are others where the exact opposite is true. As it currently stands, we're not sure how much of a future Hyper Threading will have in future Intel architectures - but it's definitely not a sure win."One of the upcoming AnandTech projects, a Database server comparison on SUSE Linux 9 SP1 (Kernel 2.6.x), is showing similar results - Hyper Threading decreases database read performance by 1% to 6% in many cases.
Why Hyperthreading fails to impress...
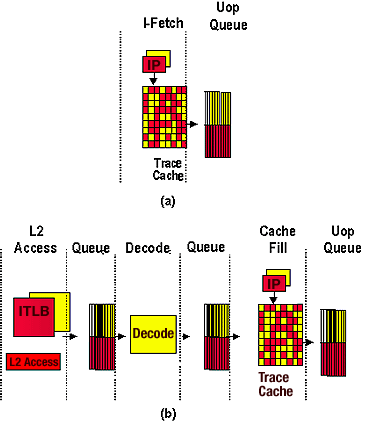
The current form of SMT [1] in the Pentium 4 is quite mediocre, but SMT is not going to disappear. The Netburst architecture is simply not well suited for SMT, and Intel implemented Hyper Threading with the goal of minimizing the die area cost. Only a few small structures were replicated - the die area cost was less than 5% of the total die area of the Pentium 4 (Northwood).The whole idea behind SMT is to execute two (or more) threads at the same time, on the same processor. Normally, a CPU will execute one thread, switch context (save the contents of the registers and CPU state in the cache), and then load the registers for another thread and execute it. The main objective is that a second thread would use the execution units that one thread cannot use at the moment, and vice versa. This implies a wide issue superscalar CPU; in other words, a CPU that is capable of executing many instructions in parallel.
And the Pentium 4 is hardly a wide issue superscalar CPU. It has only 4 execution ports: one Load, one store and two for executing either FP or integer instructions. In the best case, you are using the double-pumped ALU attached to these two ports, and you can achieve a burst of 6 instructions in one clock cycle: 4 additions on the 2 double-pumped ALUs, a load and a store. But the chances that you find 4 independent additions are relatively small.
The trace cache is only capable of delivering 6 micro-ops every two cycles. Those 6 micro-ops are on average about 4 x86 instructions. So, in reality, the Pentium 4 will rarely be able to sustain more than 2 x86 instructions per clock cycle. That is fine for a single threaded CPU. We measured with Intel's Vtune that, for example, an FP intensive program such as Povray is running at an IPC of 0.8-0.9, while Database applications (integer intensive) runs at IPC ranging from 0.3 to 0.5. So, an IPC of 2 is more than enough...for a single threaded CPU, that is!
While Intel's engineers designed the Hyper Threading on the Pentium 4, they made sure that one stalled logical processor would not make the other logical processor stop too. Cache misses and handling branch mispredictions might cause the first logical CPU to fill up buffering queues so that the second logical CPU has no room to run.
Therefore, some buffers and queues are effectively cut in half when you run two threads. Below, you can see how some buffers are shared dynamically between two threads and some are simply cut in two.








28 Comments
View All Comments
Viditor - Friday, May 20, 2005 - link
fitten - Thanks very much for the explanation!fitten - Friday, May 20, 2005 - link
"When a thread is blocked it got swapped out of the processor all together. It is the OS's job to check if some conditions are met to re-waken a thread. So a waiting thread will not be actively checking that data at any time.Only in single-write/multi-read situation (server/consumer model) those consumer threads are not blocked but actively checking for new data."
Only if you are using synchronization primitives (mutex, critical section, semaphore, etc.) which are kernel objects or you call sleep() or something in the midst of reading/writing values. If you are just reading/writing a memory location, the OS doesn't know anything about it. Plus, if you have multiple CPUs/cores, more than one thread can be running simultaneously, which is where the MOESI protocols really come into play.
cz - Friday, May 20, 2005 - link
When a thread is blocked it got swapped out of the processor all together. It is the OS's job to check if some conditions are met to re-waken a thread. So a waiting thread will not be actively checking that data at any time.Only in single-write/multi-read situation (server/consumer model) those consumer threads are not blocked but actively checking for new data.
fitten - Thursday, May 19, 2005 - link
"When you write a program where the threads are effectively fighting over the ownership of data, particularly in the current designs of multiprocessor (this includes multi-core) cache systems, performance will tank because of all the overhead of taking ownership and such"But doesn't AMDs MOESI protocol help avoid this by allowing one cache to copy data from another?"
No, MOESI doesn't help avoid the problem - It is the mechanism of how the problem is arbitrated and resolved.
Simplified example: CPU1 wants some data. The cache subsystem uses MOESI to determine that CPU0 currently owns that data. MOESI protocols are then used to transfer the ownership of that data to CPU1 (including copying the data to a different cache if necessary). Meanwhile, one (definitely the writing core) or both cores must wait while the MOESI stuff is done and then CPU1 is allowed to proceed with its write.
So, you can write a two thread program where each thread does nothing but writes a value into a memory location (both threads write to the same memory location). That cannot be avoided by anything. On every write, MOESI will be invoked to resolve the ownership of the data and make sure the processor currently wanting to write to that memory location owns it. So, these two threads will generate massive amounts of MOESI traffic between the two caches (on a multi-core or multi-processor machine) because both cores want to effectively always own that memory. While MOESI is fast, it still takes time to resolve, longer than not having to do the transfer of ownership and any copying required in any case. So, you have two cores fighting over the data and generating a lot of MOESI overhead which saps performance from both cores (both cores spend a bit of time waiting until the cache tells it that it can do its writing).
"I agree fully that most multi threaded applications are coarse grained. But there are HPC applications where you can not avoid to work on shared data. I believe fluid dynamics, and OLTP applications that mix writes with reads (and use row locking) are examples."
Absolutely. There are times when it simply cannot be avoided and must be done. But, if you can avoid it, then you probably want to avoid it :)
JohanAnandtech - Thursday, May 19, 2005 - link
Ahkorishaan:Good summary, that is most likely what is happening at Intel.
bob661:
"The Quest for More Processing Power, Part Three: ", that doesn't sound like a buyers guide hey? :-)
nserra:
Very astute! Ok, ok, "AMDs current dual core architecture is pretty good, let’s wait Until Intel gets it right :-).
Fitten:
I agree fully that most multi threaded applications are coarse grained. But there are HPC applications where you can not avoid to work on shared data. I believe fluid dynamics, and OLTP applications that mix writes with reads (and use row locking) are examples.
Viditor - Thursday, May 19, 2005 - link
"When you write a program where the threads are effectively fighting over the ownership of data, particularly in the current designs of multiprocessor (this includes multi-core) cache systems, performance will tank because of all the overhead of taking ownership and such"But doesn't AMDs MOESI protocol help avoid this by allowing one cache to copy data from another?
fitten - Thursday, May 19, 2005 - link
Processes that will benefit from fast cache-cache transfers are ones that are multithreaded and the threads are manipulating the same data. There are applications that do this, but usually when you design multi-threaded applications you try to avoid these type situations. When you write a program where the threads are effectively fighting over the ownership of data, particularly in the current designs of multiprocessor (this includes multi-core) cache systems, performance will tank because of all the overhead of taking ownership and such. Shared (L2) caches tend to help this out because the data doesn't actually have to be transfered to the other core's cache as a part of the taking of ownership, the cache line(s) can stay right where they are with only the ownership modified.Anyway, HPC code usually goes through pains to avoid the situation where ownership of data must switch between processes/threads often. That's why data partitioning is one of the most important steps of application design in parallel applications.
blackbrrd - Thursday, May 19, 2005 - link
Uhm.. #19 - that is exactly the point, to check if a row is locked you most likely have to query the other caches to see if it is locked or not...JNo - Thursday, May 19, 2005 - link
"In Part 2, Tim Sweeney, the leading developer behind the Unreal 3 engine, explained the challenges of multi-threaded development of the next generation of games."...before showing off a beautiful working demo of the Unreal 3 engine on the 7-core PS3 cell processor that was put together in only 2 months and that was relatively easy to develop according to the Unreal guys themselves... Ha! (cos Sweeney did downplay the use of multithreading in games if you read his original comments)
cz - Thursday, May 19, 2005 - link
It is an interesting read I would say. But I would like to point out that OLTP programs will not benefit from cache2cache performance very much. That is because the very principle of multi-threaded programming requires the user account to be locked before updating. So only one thread can update an user account at any given time and other threads are blocked. Only programs that use data in single-write and multi-read form will benefit from cache2cache performance. And most likely these applications will be some sort of scientific simulations.