Understanding the Cell Microprocessor
by Anand Lal Shimpi on March 17, 2005 12:05 AM EST- Posted in
- CPUs
Blueprint for a High Performance per Transistor CPU
Given that Cell was designed with a high performance per transistor metric in mind, its architecture does serve as somewhat of a blueprint for the technologies that result in the biggest performance gains, at the lowest transistor counts. Now that we’ve gone through a lot of the Cell architecture, let’s take a look back at what some of those architectural decisions are:1. On-die memory controller
We’ve seen this with the Athlon 64, but an on-die memory controller appears to be one of the best ways to improve overall performance, at minimal transistor expenditure. Furthermore, we also see the use of Rambus’ XDR memory instead of conventional DDR, as the memory of choice for Cell. High frequencies and high bandwidth are what Cell thrives on, and for that, there’s no substitute but Rambus’ technology.
2. SMT
On-die multithreading has also been proven to be a good way of extracting performance at minimal transistor impact. Introducing Hyper Threading to the Pentium 4’s core required a die increase of less than 5%, just to give you an idea of the scale of things. The performance benefits to SMT will obviously vary depending on the architecture of the CPU. In the case of the Pentium 4, performance gains ranged from 0 - 20%. In the case of the in-order PPE core of Cell, the performance gains could be even more. Needless to say, if implemented well, and if proper OS/software support is there, SMT is a feature that makes sense and doesn’t strain the transistor budget.
3. Simpler, in-order, narrow-issue core - but lots of them
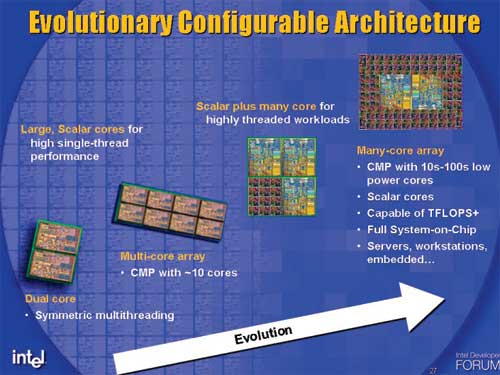
This next design decision is more controversial than the first two, simply because it goes against the design strategies of most current generation desktop microprocessors that we’re familiar with. By making the PPE and SPEs 2-issue only, each individual core still remains a manageable size. Narrower cores obviously sacrifice the ability to extract ILP, but doing so allows you to cram more cores onto a single die - highlighting the ILP for TLP sacrifice that the Cell architects have made.
Getting rid of the additional logic and windows needed for an out-of-order core helps further reduce transistor count, but at the expense of making sure that you have a solid compiler and/or developers that are willing to deal with more of the architecture’s intricacies to achieve good performance.
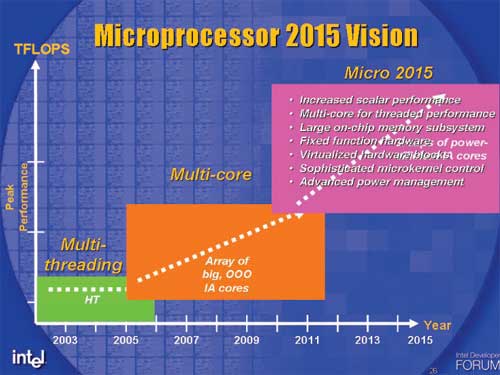
Looking at Intel’s roadmap for Platform 2015, the type of microprocessors that they’re talking about are eerily Cell-like - a handful of strong general purpose cores surrounded by smaller cores, some of which are more specialized hardware.








70 Comments
View All Comments
PhilAnd - Wednesday, October 5, 2005 - link
Thank you SO MUCH!!! I've been looking for an explanation of the cell forever and this did it perfictly!! THANK YOU!!! YOU ARE GOD!!!philpoe - Sunday, July 31, 2005 - link
Under the high-level overview of the cell section, the PPE has 64KB L1 and 512KB L2 cache.On the other hand, under the on-die memory controller section, we see that the XDR memory gives bandwidth of 25.6GB/sec, and the integrated memory controller "significantly reduces memory latencies".
My question then is, what good is the L1 and L2 cache doing? Given the amount of real estate those transistors take up, isn't it more economical to use the system RAM exclusively? The L2 cache takes up about the same amount of space as an SPE, not that it would help but so much to put another one on the die, but what effect on performance would getting rid of the L2 or even L1 cache have on memory with such high bandwidth?
tipoo - Wednesday, December 2, 2015 - link
L1 and L2 latency isn't even approached by the fastest system RAM latencies, XDR included. Nanoseconds vs milliseconds.jiulemoigt - Saturday, March 26, 2005 - link
Oh #59 it's funnier than that the PPE does all the work the modern CPU does with logic, and the easy stuff is done by the extra procs... but that means the messy {think calc equations} can not be done by the extra proc so if your game requires more abstract equations vs simple math {the math understadning simple math} say AI vs drawing boxes adn cubes, your machine will be dependant of the smaller proc, and the pipeline length is a game of balence prediction vs speed meaning that if you can predict a full pipeline it is much faster if the pipe is longer the vs you miss with the prediction at some point in the pipe and everthing after that point is lost so the longer the pipe is after the miss is a loss. So a shorter pipe is not nessacry better as there are tasks the P4 excells at because it has the huge pipe and the longer the pipe the high you can scale the proc speed, which is why intel chose such a huge pipe knowing the misses would hurt but at the time people still wanted every mhz possible. AMD has a 14 stage pipe because they use decent prediction but better register use, as well as fast pathing, but the biggest reason x86 is fast is because as long as it works theres reams of code out there to reach the sun a new system will require human hours to clean up so that is can take all the short cuts that x86 already does. So if the dev's are laughing now it is becasue the know it going to be very unfriendly to code for and are frustrated that the hardware which has years of effort going into it's design is not being designed to be easier to code for and to do the hardwork for us instead of the doing all the easy work faster which doesn't help us and making the hardwork harder! and in some cases run slower because it was cheaper. I understand how much money M$ lost, which was passed on to nvidia, so for them they won't get away with that this time so they will have to make it cheaper this time around.AndyKH - Thursday, March 24, 2005 - link
#55Regarding the interview from GameSpot:
He (the guy who is very upset with having to program for in-order cores) states that code will run very crappy on these new cores. Well... I don't know exactly how many pipeline stages the new cores have, but they will without a doubt have a LOT less stages than modern out-of-order core. If you also spend a great amount of design effort to make sure the branch target is calculated very early in the pipeline and couple that with a high clock frequency, you might not even need to fetch your bag of kleenexes to dry your eyes.
Of course, I don't know how long the pipeline in a Cell PPE or in the Xenon's cores is, but everything points to a very short one. Also I don't know how early the branch target is calculated, but I bet it's pretty early.
As an end remark I might add that "computer engineers are not stupid people". In the interview, the guy make it sound like it will be impossible to run gameplay code on the new console CPUs..... I personally don't think that IBM and Sonys engineers will design a CPU with such a little amount of care.
Regards
Andreas
TheGee - Monday, March 21, 2005 - link
Transputer anyone? The computer on a chip that could be massively parralleled? Difficult to program but this cell is not such a great leap in ideas but with the corporate weight may succeed where others have failed and break the x86 limitations put on PCs. If the busses are big enough it would be nice to be able to plug in extra CPUs on a card or such like to upgrade or speed up a system without to much difficulty as long as the software is not CPU limited. But as before it's best not to hold your breath!Slaimus - Sunday, March 20, 2005 - link
PS1 was easy to program, so that took off. Sony made PS2 very hard to program if you want to use its vector units efficiently, but since the game developers are already on board, they had to live with it. And sony will dump the same heap onto developers again with the PS3.With this kind of complexity, I have a feeling that middleware companies will thrive. Game developers want to create content more than write assembly code, so a few middleware companies will probably supply the libraries while everyone else licenses them. Of course Microsoft has a head start since DirectX already exists and is included in the devkit, but then again, the xbox2 is not as massively parallel.
stephenbrooks - Sunday, March 20, 2005 - link
Ah sod multiple cores. I always preferred playing Tetris anyhow.knitecrow - Friday, March 18, 2005 - link
GAME DEVELOPER @ GDC RANT ON NEXT GEN CONSOLEShttp://www.gamespot.com/news/2005/03/18/news_61204...
All right, here we go. "How Sony and Microsoft are about to screw your game design." These are games in the good old days. We didn't exactly have the best physique, but we were at least a balanced individual, you walk out on the beach, and you were like, you know, pathetic. But you know, you looked like a normal person. These are games today. We've been working really hard--I mean, you can maybe make the argument that this is the game--these are games today. I gotta little more work on that left arm to do, it's going to be as big as our graphics arm soon. This is kind of lame. We really want to be this guy don't we?
Unknown Speaker: No!
[laughter]
Chris Hecker: OK, he was the best guy I could find in like, three seconds in the WiFi network out in the lobby. All right. But how do we get there? Well, I'm going to take a little diversion here. I'm a programmer, so, I have two technical slides, really one technical slide. And that's about it. All right, ready? So there are two kinds of code in a game basically. There's gameplay code and engine code. Engine code, like graphics and physics, takes really giant data structures of homogenous data. I mean, it's all the same, like a lot of vertices are all a big matrix, or whatever, but usually floating point data structures these days. And you have a single small, relatively small hour that grinds away on that. This code is like, wow, it has a lot of math in it, it has to be optimized for super scalar, blah, blah, blah. It's just not actually that hard to write, right? It's pretty well defined what this code does.
The second kind of code we have is AI and gameplay code. Lots of little exceptions. Even if you're doing a simulation-y kind of game, there's tons of tunable parameters, [it's got a lot of interactions], it's a mess. I mean, this code--you look at the gameplay code in the game, and it's crap. Compared to like, my elegant physics simulator or whatever. But this is a code that actually makes the game feel different. This is the kind of code we want to be easy to write and so we can do more experimental stuff. Here is the terrifying realization about the next generation of consoles. I'm about to break about a zillion NDAs, but I didn't sign any NDAs so that's totally cool!
I'm actually a pretty good programmer and mathematician but my real talent is getting people to tell me stuff that they're not supposed to tell me. There we go. Gameplay code will get slower and harder to write on the next generation of consoles. Why is this? Here's our technical slide. Modern CPUs, like the Intel Pentium 4, blah, blah, blah, Pentium [indiscernible] or laptop, whatever is in your desktop, and all the modern power PCs, use what's called 'out of order' execution. Basically, out of order execution is there to make really crappy code run fast.
So, they basically--when out of order execution came out on the P6, the Pentium 6 [indiscernible] the Pentium 5, the original Pentium and the one after that. The Pentium Pro I think they called it, it basically annoyed a whole bunch of low level ASCII coders, because now all of a sudden, like, the crappiest-ass C code, that like, Joe junior programmer could write, is running as fast as their Assembly, and there's nothing they can do about it. Because the CPU behind their back, is like, reordering that guy's crappy ass C code, to run really well and utilize all the parts of the processor. While this annoyed a whole bunch of people in Scandinavia, it actually…
[laughter]
And this is a great change in the bad old days of 'in order execution,' where you had to be an Assembly language wizard to actually get your CPU to do anything. You were always stalling in the cache, you needed to like--it was crazy. It was a lot of fun to write that code. It wasn't exactly the most productive way of doing experimental programming.
The Xenon and the cell are both in order chips. What does this mean? The reason they did this, is it's cheaper for them to do this. They can drop a lot of core--you know--one out of order core is about the size of three to four in order cores. So, they can make a lot of in order cores and drop them on a chip, and keep the power down, and sell it for cheap--what does this do to our code?
Well, it makes--it's totally fine for grinding like, symmetric algorithms out of floating point numbers, but for lots of 'if' statements in directions, it totally sucks. How do we quantify 'totally sucks?' "Rumors" which happen to be from people who are actually working on these chips, is that straight line gameplay code runs at 1/3 to 1/10 the speed at the same clock rate on an in order core as an out of order core.
This means that your new fancy 2 plus gigahertz CPU, and its Xenon, is going to run code as slow or slower than the 733 megahertz CPU in the Xbox 1. The PS3 will be even worse.
This sucks!
[laughter]
There's absolutely nothing you can do about this. Well, you can actually hope that Nintendo uses an out of order core, because they're claiming that they're going to try and make it easy to develop for--except for Nintendo basically totally flailed this generation. So maybe they'll do something next generation. Who knows? You can think about having batchable design simulation-y systems, but like, I'm a huge proponent of simulation in gameplay, but even simulation in gameplay takes kind of messy systems under the hood. And this makes your gameplay harder to write.
You want to just write the gameplay. You don't want to have to like, spend 6 years of a super hardcore engine programmer's time to figure out how to make your gameplay run super scalars. You could do PC games. They are still out of order cores, but a lot of people don't think that's an option nowadays.
tipoo - Thursday, December 3, 2015 - link
It's funny looking back, he wanted them to change the CPU from the Gamecube for the next generation...They ended up using an upclocked Gamecube CPU for the Wii, and a modified tri core version of it for the Wii U.