Quick Note: Intel “Knights Landing” Xeon Phi & Omni-Path 100 @ ISC 2015
by Ryan Smith on July 13, 2015 6:30 PM EST
Taking place this week in Frankfurt, Germany is the 2015 International Supercomputing Conference. One of the two major supercomputing conferences of the year, ISC tends to be the venue of choice for major high performance computing announcements for the second half of the year and is where the summer Top 500 supercomputer list is unveiled.
In any case, Intel sends word over that they are at ISC 2015 showing off the “Knights Landing” Xeon Phi, which is ramping up for commercial deployment later this year. Intel unveiled a number of details about Knights Landing at last year’s ISC, where it was announced that the second-generation Xeon Phi would be based on Intel’s Silvermont cores (replacing the P54C cores in Knights Corner) and built on Intel’s 14nm process. Furthermore Knights Landing would also include up to 16GB of on-chip Multi-Channel DRAM (MCDRAM), an ultra-wide stacked memory standard based around Hybrid Memory Cube.

Having already revealed the major architecture details in the last year, at this year’s show Intel is confirming that Knights Landing remains on schedule for its commercial launch later this year. This interestingly enough will make Knights Landing the second processor to ship this year with an ultra-wide stacked memory technology, after AMD’s Fiji GPU, indicating how quickly the technology is being adopted by processor manufacturers. More importantly for Intel of course, this will be the first such product to be targeted specifically at HPC applications.
Meanwhile after having previously announced that the design would include up to 72 cores - but not committing at the time to shipping a full 72 core part due to potential yield issues - Intel is now confirming that one or more 72 core SKUs will be available. This indicates that Knights Landing is yielding well enough to ship fully enabled, something the current Knights Corner never achieved (only shipping with up to 61 of 62 cores enabled). Notably this also narrows down the expected clockspeeds for the top Knights Landing SKU; with 72 cores capable of processing 32 FP64 FLOPs/core (thanks to 2 AVX-512 vector units per core), Intel needs to hit 1.3GHz to reach their 3 TFLOPs projection.
Moving on, Knights Landing’s partner interconnect technology, Omni-Path, is also ramping up for commercial deployment. After going through a few naming variants, Intel has settled on the Omni-Path Fabric 100 series, to distinguish it from planned future iterations of the technology. We won’t spend too much on this, but it goes without saying that Intel is looking to move to a vertically integrated ecosystem and capture the slice of HPC revenue currently spent on networking with Infiniband and other solutions.

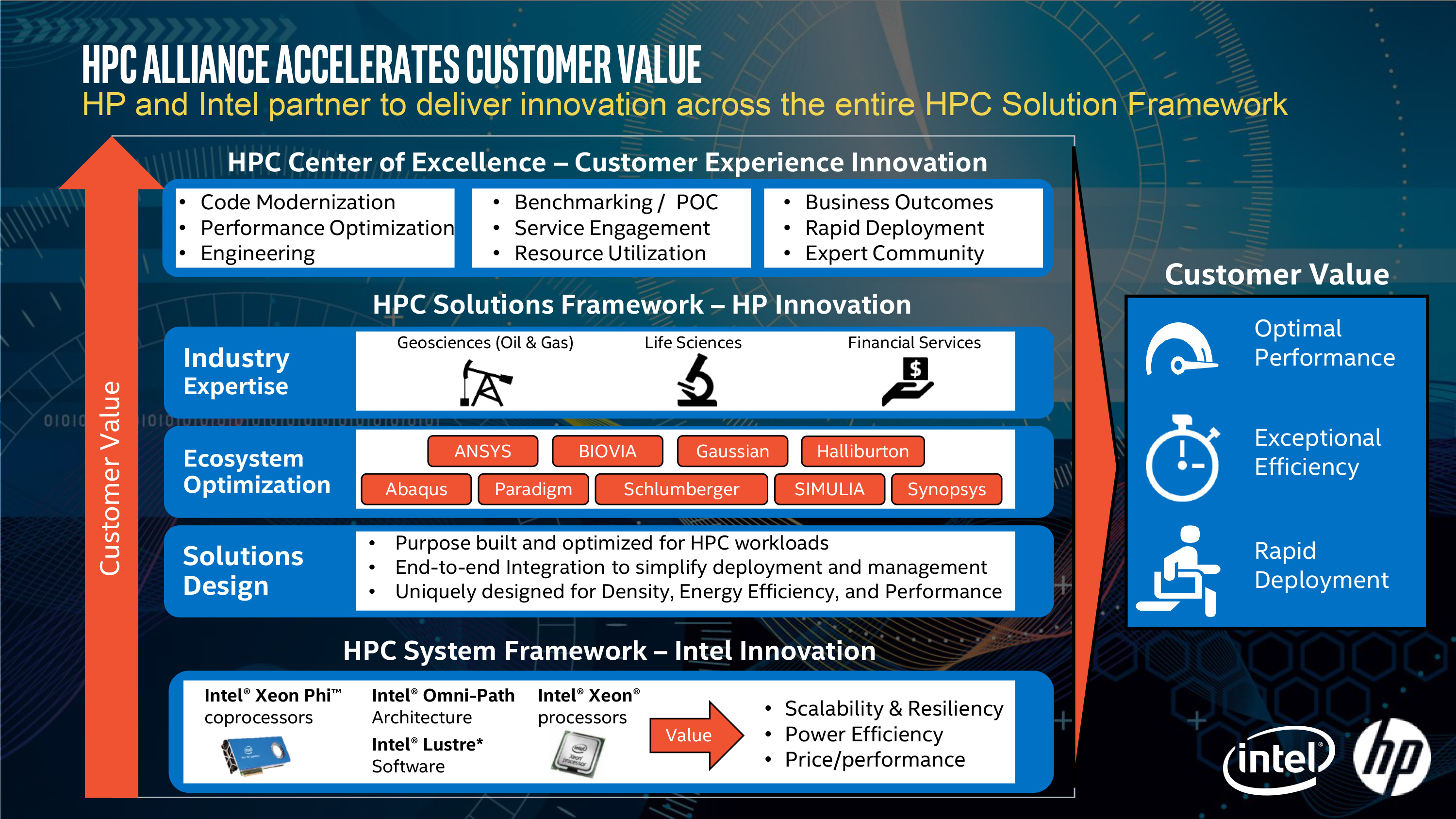
Finally, in order to develop that vertically integrated ecosystem, Intel is announcing that they have teamed up with HP to build servers around Intel’s suite of HPC technologies (or as Intel calls it, their Scalable System Framework). HP will be releasing a series of systems under the company’s Apollo brand of HPC servers that will integrate Knights Landing, Omni-Path 100, and Intel’s software stack. For Intel the Apollo HPC systems serve two purposes: to demonstrate the capabilities of their ecosystem and the value of their first-generation networking fabric, and of course to get complete systems on the market and into the hands of HPC customers.
Source: Intel








53 Comments
View All Comments
SaberKOG91 - Tuesday, July 14, 2015 - link
I'm sorry, but that's simply not true.You must have the Intel Compiler Collection and Intel Parallel Studio to use it, which are not free for non-academic use (not to mention the usual headache of Intel licensing). The Linux that the Phi runs is a highly specialized BSP built by Intel with a ton of proprietary code. It's not as if you can just throw Ubuntu on this thing and start programming. They had to patch the kernel to allow this card to nfs boot the OS, and for the host processor to move data back and forth.
By comparison, CUDA is a package install away and is free for anyone to use for any purpose. OpenCL for AMD requires a little bit of compiling for most distros or a single package on Debian. As a bonus, writing OpenCL code allows me to target both Nvidia and AMD gpus with a negligible performance impact (<5%) compared to CUDA native.
68k - Tuesday, July 14, 2015 - link
OpenCL is supported even on exiting Xeon Phihttps://int2-software.intel.com/en-us/articles/ope...
gcc support to offload OpenMP to Xeon Phi is being worked on for Knights landing
https://gcc.gnu.org/wiki/Offloading
There is a version of GCC for Knights Corner, but it is not recommended for compute intensive code yet as the compiler is not very good at utilize the vector capabilities of Xeon Phi.
And regarding ease of programming: I was under the impression that Xeon Phi cannot match Nvidias/AMDs top of the line GPUs in theoretical FLOPS, but Xeon Phi was still a success in the HPC area just because it was a lot easier to program (i.e. much easier to reach a certain fraction of the theoretical maximum).
Jaybus - Wednesday, July 15, 2015 - link
Yes. The cores are Silvermont with FP and vector enhancements. They will code that normal Silvermont cores will run now. The Intel compiler is needed to take advantage of the enhancements, at least until gcc catches up.What isn't being looked at is that it doesn't exactly compare 1:1 with GPGPU solutions. There is nothing preventing the use of both at the same time. A system could certainly be built with both Phi and GPUs. GPUs are more vector oriented and require thread grouping (SIMD), whereas Phi is MIMD (mostly) and so has an advantage for problems that are more serial or iterative by nature.
patrickjp93 - Tuesday, July 14, 2015 - link
Not true. You can use OpenCL or OepnMP under GCC, Clang, or ICC.patrickjp93 - Tuesday, July 14, 2015 - link
I forgot to mention they also work with OpenACC.darthscsi - Tuesday, July 14, 2015 - link
This isn't true. I've rutinely used gcc to cross-compile native phi binaries. One can use pthread or openmp without problems. From there you ssh into the PHI, run your app from the nfs mounted filesystem you set up, etc. Given the mostly self-contained nature of the old PHIs, it is easy to see wny intel is moving to dropping the host system.As a side note, the PHI networking is run over the in-kernel non-transparent pci-e bridge driver.
beginner99 - Wednesday, July 15, 2015 - link
Reading comprehension? What you say is true for current Xeon Phi, which is only available as an Add-on card. Here we are talking about the next iteration, code named Knights Landing. It is available also as socketed version and also acts as the CPU. It literally can run Windows or Ubuntu. The cores in this new Xeon Phi are beefed up Silvermont cores which are small x86 64-bit capable cores already used in the Atom series of processors.Quote:
Probably most important: Knights Landing is *not* an add-on product that requires a regular system with a regular CPU to run... it is a completely self-hosting Xeon processor that boots & runs Linux or Windows and makes 100% of the computing resources visible to regular software running on the system. Any multi-threaded program that can scale out to the core count and is setup to use the AVX-512 instructions can push this card up to those theoretical numbers.
Anything not using AVX-512 can still use all 72 cores. You can take your existing x86 multi-threaded application and it will run on 72 cores if it is programmed to use all cores. This is huge and a huge thread for NV/AMD.
Loki726 - Friday, July 17, 2015 - link
It depends on what you mean by compatible. If you want to run existing multithreaded or AVX assembly tuned applications on a bunch of Atom cores, then it is much easier to port to Xeon PHI. If you are trying to write a new application that gets good utilization out of thousands of vector lanes, I think GPUs actually have a better programming model.Senti - Tuesday, July 14, 2015 - link
AMD has mostly (but not completely) working OpenCL, NV has working CUDA and sometimes working OpenCL.If Intel delivers non-buggy the usual x86 platform – it _will_ be very interesting for serious computations.
doids - Wednesday, July 15, 2015 - link
Xeon Phi supports OpenCL so it is as trivial as using Cuda/OpenCL on graphics cards