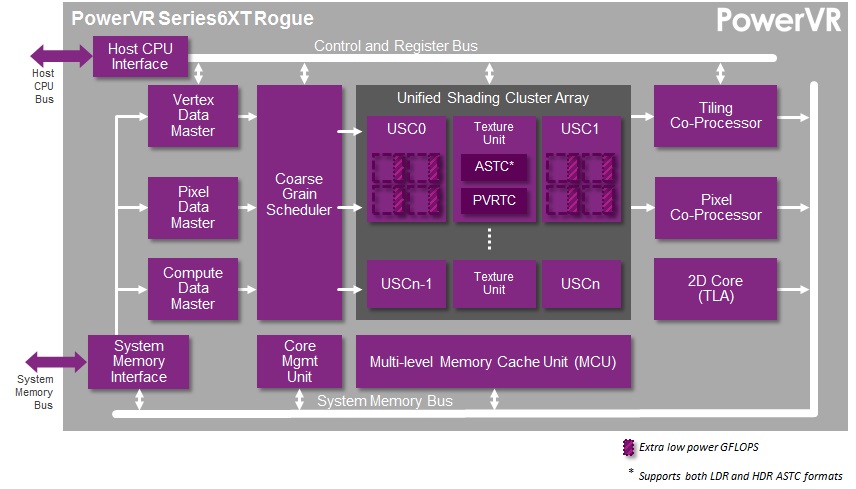
Imagination's PowerVR Rogue Architecture Explored
by Ryan Smith on February 24, 2014 3:00 AM EST- Posted in
- GPUs
- Imagination Technologies
- PowerVR
- PowerVR Series6
- SoCs
Background: How GPUs Work
Seeing as how this is our first in-depth architecture article on a SoC GPU design (specifically as opposed to PC-derived designs like Intel and NVIDIA), we felt it best to start at the beginning. For our regular GPU readers the following should be redundant, but if you’ve ever wanted to learn a bit more about how a GPU works, this is your place to start.
GPUs, like most complex processors, are composed of a number of different functional units responsible for the different aspects of computation and rendering. We have functional units that setup geometry data, frequently called geometry engine, geometry processors, or polymorph engines. We have memory subsystems that provide caching and access to external memory. We have rendering backends (ROPs or pixel co-processors) that take computed geometry and pixels to blend them and finalize them. We have texture mapping units (TMUs) that fetch textures and texels to place them within a scene. And of course we have shaders, the compute cores that do much of the heavy lifting in today’s games.
Perhaps the most basic question even from a simple summary of the functional units in a GPU is why there are so many different functional units in the first place. While conceptually virtually all of these steps (except memory) can be done in software – and hence done in something like a shader – GPU designers don’t do that for performance and power reasons. So-called fixed function hardware (such as ROPs) exists because it’s far more efficient to do certain tasks with hardware that is tightly optimized for the job, rather than doing it with flexible hardware such as shaders. For a given task flexible hardware is bigger and consumes more power than fixed function hardware, hence the need to do as much work in power/space efficient fixed function hardware as is possible. As such the portions of the rendering process that need flexibility will take place in shaders, while other aspects that are by their nature consistent and fixed take place in fixed function units.
The bulk of the information Imagination is sharing with us today is with respect to shaders, so that’s what we’ll focus on today. On a die area basis and power basis the shader blocks are the biggest contributors to rendering. Though every functional unit is important for its job, it’s in the shaders that most of the work takes place for rendering, and the proportion of that work that is bottlenecked by shaders increases with every year and with every generation, as increasingly complex shader programs are created.
So with that in mind, let’s start with a simple question: just what is a shader?
At its most fundamental level, a shader core is a flexible mathematics pipeline; it is a single computational resource that accepts instructions (a shader program) and executes it in order to manipulate the pixels and polygon vertices within a scene. An individual shader core goes by many names depending on who makes it: AMD has Stream Processors, NVIDIA has CUDA cores, and Imagination has Pipelines. At the same time how a shader core is built and configured depends on the architecture and its design goals, so while there are always similarities it is rare that shader cores are identical.
On a lower technical level, a shader core itself contains several elements. It contains decoders, dispatchers, operand collectors, results collectors, and more. But the single most important element, and the element we’re typically fixated on, is the Arithmetic Logic Unit (ALU). ALUs are the most fundamental building blocks in a GPU, and are the base unit that actually performs the mathematical operations called for as part of a shader program.
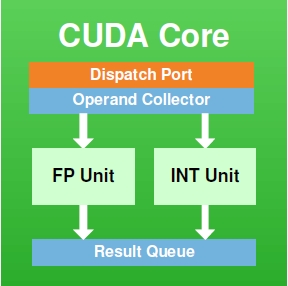
An NVIDIA CUDA Core
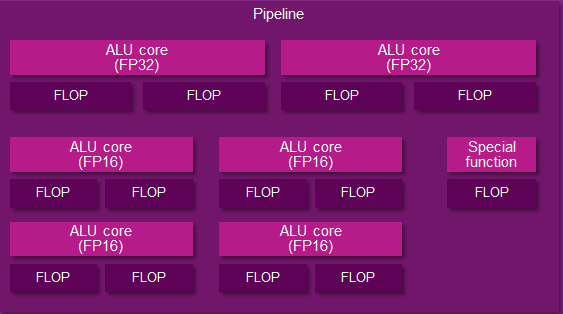
And an Imgination PVR Rogue Series 6XT Pipeline
The number of ALUs within a shader core in turn depends on the design of the shader core. To use NVIDIA as an example again, they have 2 ALUs – an FP32 floating point ALU and an integer ALU – either of which is in operation as a shader program requires. In other designs such as Imagination’s Rogue Series 6XT, a single shader core can have up to 7 ALUs, in which multiple ALUs can be used simultaneously. From a practical perspective we typically count shader cores when discussing architectures, but it is at times important to remember that the number of ALUs within a shader core can vary.
When it comes to shader cores, GPU designs will implement hundreds and up to thousands of these shader cores. Graphics rendering is what we call an embarrassingly parallel process, as there are potentially millions of pixels in a scene, most of which can be operated in in a semi-independent or fully-independent manner. As a result a GPU will implement a large number of shader cores to work on multiple pixels in parallel. The use of a “wide” design is well suited for graphics rendering as it allows each shader core to be clocked relatively low, saving power while achieving work in bulk. A shader core may only operate at a few hundred megahertz, but because there are so many of them the aggregate throughput of a GPU can be enormous, which is just what we need for graphics rendering (and some classes of compute workloads, as it turns out).
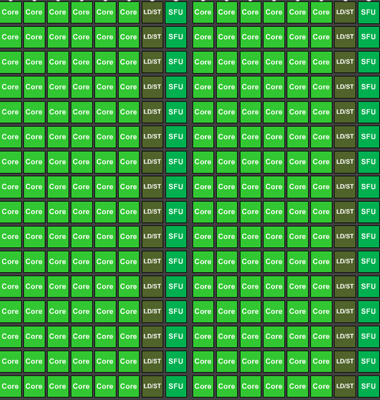
A collection of Kepler CUDA cores, 192 in all
The final piece of the puzzle then is how these shader cores are organized. Like all processors, the shader cores in a GPU are fed by a “thread” of instructions, one instruction following another until all the necessary operations are complete for that program. In terms of shader organization there is a tradeoff between just how independent a shader core is, and how much space/power it takes up. In a perfectly ideal scenario, each and every shader core would be fully independent, potentially working on something entirely different than any of its neighbors. But in the real world we do not do that because it is space and power inefficient, and as it turns out it’s unnecessary.
Neighboring pixels may be independent – that is, their outcome doesn’t depend on the outcome of their neighbors – but in rendering a scene, most of the time we’re going to be applying the same operations to large groups of pixels. So rather than grant the shader cores true independence, they are grouped up together for the purpose of having all of them executing threads out of the same collection of threads. This setup is power and space efficient as the collection of shader cores take up less power and less space since they don’t need the intelligence to operate completely independently of each other.

The flow of threads within a wavefront/warp
Not unlike the construction of a shader core, how shader cores are grouped together will depend on the design. The most common groupings are either 16 or 32 shader cores. Smaller groupings are more performance efficient (you have fewer shader cores sitting idle if you can’t fill all of them with identical threads), while larger groupings are more space/power efficient since you can group more shader cores together under the control of a single instruction scheduler.
Finally, these groupings of threads can go by several different names. NVIDIA uses the term warp, AMD uses the term wavefront, and the official OpenGL terminology is the workgroup. Workgroup is technically the most accurate term, however it’s also the most ambiguous; lots of things in the world are called workgroups. Imagination doesn’t have an official name for their workgroups, so our preference is to stick with the term wavefront, since its more limited use makes it easier to pick up on the context of the discussion.
Summing things up then, we have ALUs, the most basic building block in a GPU shader design. From those ALUs we build up a shader core, and then we group those shader cores into a array of (typically) 16 or 32 shader cores. Finally, those arrays are fed threads of instructions, one thread per shader core, which like the shader cores are grouped together. We call these thread groups wavefronts.
And with that behind us, we can now take a look at the PowerVR Series 6/6XT Unfied Shading Cluster.








95 Comments
View All Comments
Sonicadvance1 - Tuesday, February 25, 2014 - link
Thanks for the response. Good to know. The article didn't really note anything about it.ryszu - Tuesday, February 25, 2014 - link
I misspoke actually, integer is a separate pipe in Rogue.Sonicadvance1 - Thursday, February 27, 2014 - link
Alright, then how much slower is Integer performance compared to floating point? Integer performance is an area that Nvidia struggles with as well.MrSpadge - Saturday, March 1, 2014 - link
This sounds different from any material Ryan showed or discussed. Could you elaborate, may directly to Ryan and have him update the article?Frenetic Pony - Monday, February 24, 2014 - link
I'm not sure what exactly is being babbled on about with tile based deferred rendering. It's just software, anyone can write and run it. Go onto a friendly GPU programming forum and they'll take you through it step by step.Scali - Monday, February 24, 2014 - link
Deferred rendering is a software solution. Tile-based deferred rendering is a hardware solution. The GPU cuts up the triangles in a set of tiles. Inside the GPU, there is a superfast 'framebuffer' the size of a tile (think of a special L1-cache). The GPU renders one tile at a time into this buffer, solving overdraw very quickly and efficiently, then it burst-writes the tile out to the framebuffer in videomemory. PowerVR has been using this technology since the early days of 3D acceleration (I have a PowerVR PCX2 card myself, and did a blog on it a while ago: http://scalibq.wordpress.com/2012/12/18/just-keepi...I suggest you read up on it, it is very interesting technology, and unlike any competing GPU.
Frenetic Pony - Monday, February 24, 2014 - link
No it isn't. Anyone with the proper feature set can do tile based deferred, most next gen games are going to be culling light lists out on something like an 8x8 pixel per tile basis, whether that's for forward rending or deferred. Which sounds exactly like what you described.It might be nice that there's some special little cache for it in PowerVr. But the basic idea as you've described it sounds exactly the same in principle as what DICE/EA's Frostbite does, as well as any number of other papers and games coming do.
Scali - Monday, February 24, 2014 - link
No, I don't think you quite get it. Culling lights in tiles is something different.In this case the geometry is batched up before drawing, then binned to tiles, and then the visibility (z-order) is solved on a per-tile basis.
It may sound the same as deferred rendering tricks in software, but it is not quite the same. These software tricks depend on multiple rendering passes, with z/stenciltesting to determine which pixels to shade. PowerVR can do it in a single pass (as far as the software is concerned).
Again, I suggest you read up on it.
Scali - Monday, February 24, 2014 - link
In fact, the PowerVR PCX2 card did not even need a z-buffer in videomemory at all. What "feature set" on a regular GPU would be able to render properly without a z-buffer?MrPoletski - Sunday, March 9, 2014 - link
Exactly, the Z-buffer is on chip. Incidentally, Multi-sampling AA increases your Z-buffer and framebuffer bandwidth requirements by a factor of x (for 4x AA). What if that were all on chip?I can't believe IMGTEC haven't made more noise about this.