The iPad Air Review
by Anand Lal Shimpi on October 29, 2013 9:00 PM ESTAn Update on Apple’s A7: It's Better Than I Thought
When I reviewed the iPhone 5s I didn’t have much time to go in and do the sort of in-depth investigation into Cyclone (Apple’s 64-bit custom ARMv8 core) as I did with Swift (Apple’s custom ARMv7 core from A6) the year before. I had heard rumors that Cyclone was substantially wider than its predecessor but I didn’t really have any proof other than hearsay so I left it out of the article. Instead I surmised in the 5s review that the A7 was likely an evolved Swift core rather than a brand new design, after all - what sense would it make to design a new CPU core and then do it all over again for the next one? It turns out I was quite wrong.
Armed with a bit of custom code and a bunch of low level tests I think I have a far better idea of what Apple’s A7 and Cyclone cores look like now than I did a month ago. I’m still toying with the idea of doing a much deeper investigation into A7, but I wanted to share some of my findings here.
The first task is to understand the width of the machine. With Swift I got lucky in that Apple had left a bunch of public LLVM documentation uncensored, referring to Swift’s 3-wide design. It turns out that although the design might be capable of decoding, issuing and retiring up to three instructions per clock, in most cases it behaved like a 2-wide machine. Mix FP and integer code and you’re looking at a machine that’s more like 1.5 instructions wide. Obviously Swift did very well in the market and its competitors at the time, including Qualcomm’s Krait 300, were similarly capable.
With Cyclone Apple is in a completely different league. As far as I can tell, peak issue width of Cyclone is 6 instructions. That’s at least 2x the width of Swift and Krait, and at best more than 3x the width depending on instruction mix. Limitations on co-issuing FP and integer math have also been lifted as you can run up to four integer adds and two FP adds in parallel. You can also perform up to two loads or stores per clock.
I don’t yet have a good understanding of the number of execution ports and how they’re mapped, but Cyclone appears to be the widest ARM architecture we’ve ever seen at this point. I’m talking wider than Qualcomm’s Krait 400 and even ARM’s Cortex A15.
I did have some low level analysis in the 5s review, where I pointed out the significantly reduced memory latency and increased bandwidth to the A7. It turns out that I was missing a big part of the story back then as well…
A Large System Wide Cache
In our iPhone 5s review I pointed out that the A7 now featured more computational GPU power than the 4th generation iPad. For a device running at 1/8 the resolution of the iPad, the A7’s GPU either meant that Apple had an application that needed tons of GPU performance or it planned on using the A7 in other, higher resolution devices. I speculated it would be the latter, and it turns out that’s indeed the case. For the first time since the iPad 2, Apple once again shares common silicon between the iPhone 5s, iPad Air and iPad mini with Retina Display.
As Brian found out in his investigation after the iPad event last week all three devices use the exact same silicon with the exact same internal model number: S5L8960X. There are no extra cores, no change in GPU configuration and the biggest one: no increase in memory bandwidth.
Previously both the A5X and A6X featured a 128-bit wide memory interface, with half of it seemingly reserved for GPU use exclusively. The non-X parts by comparison only had a 64-bit wide memory interface. The assumption was that a move to such a high resolution display demanded a substantial increase in memory bandwidth. With the A7, Apple takes a step back in memory interface width - so is it enough to hamper the performance of the iPad Air with its 2048 x 1536 display?
The numbers alone tell us the answer is no. In all available graphics benchmarks the iPad Air delivers better performance at its native resolution than the outgoing 4th generation iPad (as you'll soon see). Now many of these benchmarks are bound more by GPU compute rather than memory bandwidth, a side effect of the relative lack of memory bandwidth on modern day mobile platforms. Across the board though I couldn’t find a situation where anything was smoother on the iPad 4 than the iPad Air.
There’s another part of this story. Something I missed in my original A7 analysis. When Chipworks posted a shot of the A7 die many of you correctly identified what appeared to be a 4MB SRAM on the die itself. It's highlighted on the right in the floorplan diagram below:
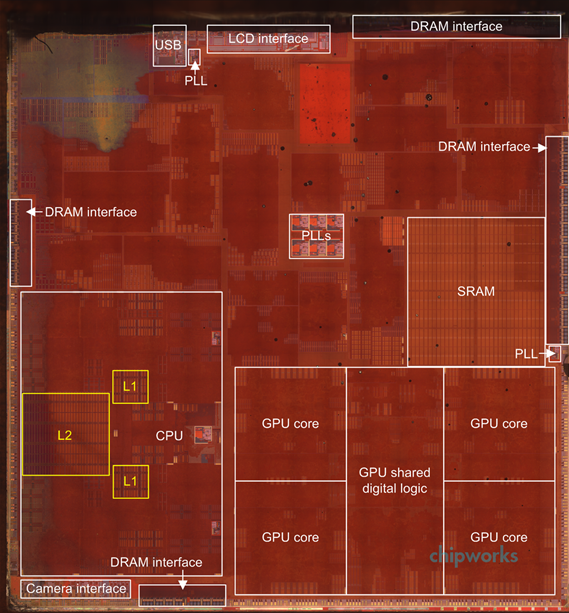
A7 Floorplan, Courtesy Chipworks
While I originally assumed that this SRAM might be reserved for use by the ISP, it turns out that it can do a lot more than that. If we look at memory latency (from the perspective of a single CPU core) vs. transfer size on A7 we notice a very interesting phenomenon between 1MB and 4MB:

That SRAM is indeed some sort of a cache before you get to main memory. It’s not the fastest thing in the world, but it’s appreciably quicker than going all the way out to main memory. Available bandwidth is also pretty good:
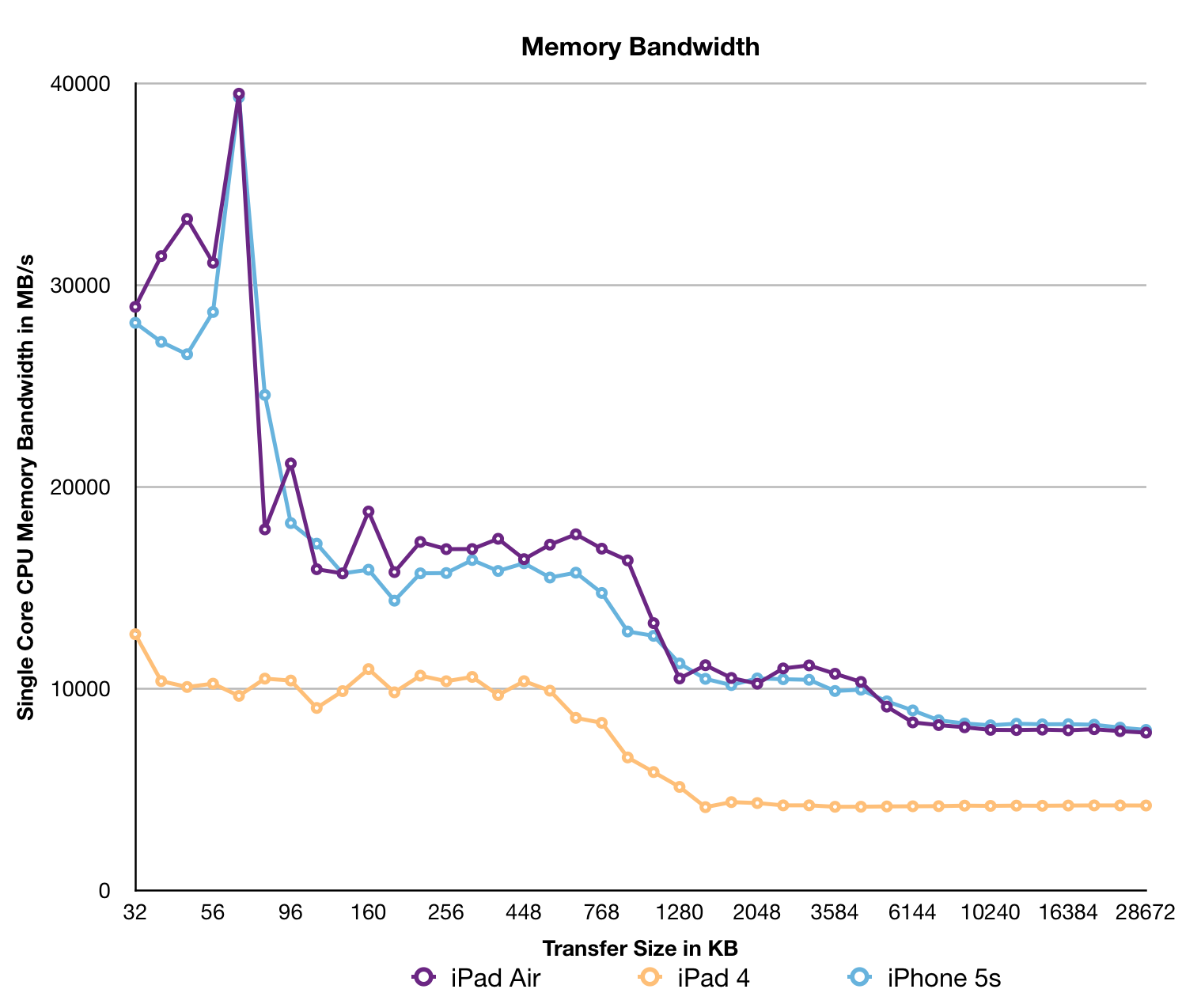
We’re only looking at bandwidth seen by a single CPU core, but even then we’re talking about 10GB/s. Lookups in this third level cache don’t happen in parallel with main memory requests, so the impact on worst case memory latency is additive unfortunately (a tradeoff of speed vs. power).
I don’t yet have the tools needed to measure the impact of this on-die memory on GPU accesses, but in the worst case scenario it’ll help free up more of the memory interface for use by the GPU. It’s more likely that some graphics requests are cached here as well, with intelligent allocation of bandwidth depending on what type of application you’re running.
That’s the other aspect of what makes A7 so very interesting. This is the first Apple SoC that’s able to deliver good amounts of memory bandwidth to all consumers. A single CPU core can use up 8GB/s of bandwidth. I’m still vetting other SoCs, but so far I haven’t come across anyone in the ARM camp that can compete with what Apple has built here. Only Intel is competitive.








444 Comments
View All Comments
stingerman - Sunday, November 3, 2013 - link
Yes, I haven't even seen one of those in use other than commercials. Real failures...stingerman - Sunday, November 3, 2013 - link
lol, you're hilarious! iOS is Unix plus all the major OS X frameworks plus all the new iOS frameworks... It maybe light because of its elegance, but it's a light nuclear weapon...lilo777 - Sunday, November 3, 2013 - link
LOL. Do you know any version of Unix that does not have a file system (exposed to user)?Krysto - Friday, November 1, 2013 - link
Offtopic, but Anand, the announcement of Mali T760 is suspiciously missing from this site.Over 300 GFLOPS, which is more than PS3 and should make it pretty competitive with mobile Kepler, along with ASTC compression by default, much more efficient, and has some interesting features like hardware assisted global illumination.
ARM's announcement:
http://community.arm.com/groups/arm-mali-graphics/...
michael2k - Friday, November 1, 2013 - link
Yeah, the T700 series is for next generation devices, or in other words, products in the next 12 months. The PowerVR6 series is available now for this generation and up to 1000 GFLOPS.Krysto - Saturday, November 2, 2013 - link
Do you see that 1000 GBFLOPS in any smartphone? Just because it can be scaled that much, doesn't mean they WILL for smartphones. This GPU will be used in smartphones a year from now. What does the GPU in Apple's A7 have now? ~100 GFLOPS?Anyway, the Mali T760 seems very competitive with what will be out there a year from now, and Anandtech usually writes about these sort of announcements.
michael2k - Monday, November 4, 2013 - link
I think you've missed the point.1) We aren't in a smartphone thread
2) The PowerVR6 will scale to 1000 GFLOPs; so when the T700 comes out next year, the PowerVR will be ready
3) The Air is at about 115 GFLOPs, about 2x the outgoing iPad 4, and will therefore be approximately 230 GFLOPs in the A8 next year, if 2x, or 340 GFLOPs if 3x
So you are correct that the Mali T760 will be competitive next year, but this article is about this year.
michael2k - Monday, November 4, 2013 - link
You've missed the point.The PVR6 is 115GF today in the Air, and when needed to compete with the T700 can hit 300GF.
Likewise, we are in a thread about tablets, where it is much more likely to scale to the needed 300GF.
Krysto - Saturday, November 2, 2013 - link
What you said also reminded me of how Intel promoted "Haswell graphics"."Hey, look, out "Haswell GPU" (Iris Pro 5200) is 3x faster than IVB!" - and then you only see crappy 4600 in most devices, including the Surface Pro, which is only 20 percent faster than last year's IVB GPU.
Or "look at our awesome new 2.6 Ghz Silvermont CPU's! - and then you only see 1.3 ghz Silvemont for tablets, because the 2.6 Ghz ones are not viable either because of too high TDP or price, which makes them pretty irrelevant. What's relevant is what will be in the market, not their pie-in-the-sky CPU's that never get on the shelves.
ashleyuv - Saturday, November 2, 2013 - link
This is a very interesting review, even for someone without the tech or IT background to follow all of it. In particular, I like the way, in the last part, you show how the increase to 64-bit and the DRAM size (remaining the same), while seeming like a no-brainer and conservative decisions, respectively, are actually a smart play, albeit one with consequences.In agreement with one of your readers, I'd have to say that "review" is really the wrong word for this. It is all but a scientific study. But again, it's written for people who may not have an extensive tech background.
Thank you! I will be reading more in the future (just discovered your site).