The AMD Radeon R9 290X Review
by Ryan Smith on October 24, 2013 12:01 AM EST- Posted in
- GPUs
- AMD
- Radeon
- Hawaii
- Radeon 200
Compute
Jumping into pure compute performance, we’re going to have several new factors influencing the 290X as compared to the 280X. On the front end 290X/Hawaii has those 8 ACEs versus 280X/Tahiti’s 2 ACEs, potentially allowing 290X to queue up a lot more work and to keep itself better fed as a result; though in practice we don’t expect most workloads to be able to put the additional ACEs to good use at the moment. Meanwhile on the back end 290X has that 11% memory bandwidth boost and the 33% increase in L2 cache, which in compute workloads can be largely dedicated to said computational work. On the other hand 290X takes a hit to its double precision floating point (FP64) rate versus 280X, so in double precision scenarios it’s certainly going to enter with a larger handicap.
As always we'll start with our DirectCompute game example, Civilization V, which uses DirectCompute to decompress textures on the fly. Civ V includes a sub-benchmark that exclusively tests the speed of their texture decompression algorithm by repeatedly decompressing the textures required for one of the game’s leader scenes. While DirectCompute is used in many games, this is one of the only games with a benchmark that can isolate the use of DirectCompute and its resulting performance.
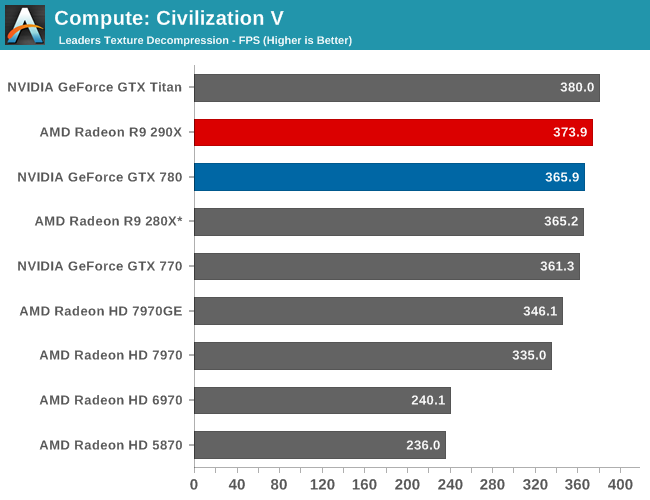
Unfortunately Civ V can’t tell us much of value, due to the fact that we’re running into CPU bottlenecks, not to mention increasingly absurd frame rates. In the 3 years since this game was released high-end CPUs are around 20% faster per core, whereas GPUs are easily 150% faster (if not more). As such the GPU portion of texture decoding has apparently started outpacing the CPU portion, though this is still an enlightening benchmark for anything less than a high-end video card.
For what it is worth, the 290X can edge out the GTX 780 here, only to fall to GTX Titan. But in these CPU limited scenarios the behavior at the very top can be increasingly inconsistent.
Our next benchmark is LuxMark2.0, the official benchmark of SmallLuxGPU 2.0. SmallLuxGPU is an OpenCL accelerated ray tracer that is part of the larger LuxRender suite. Ray tracing has become a stronghold for GPUs in recent years as ray tracing maps well to GPU pipelines, allowing artists to render scenes much more quickly than with CPUs alone.
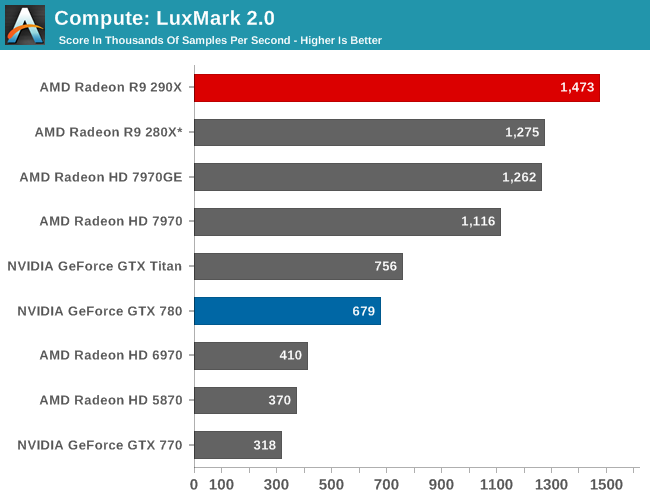
LuxMark by comparison is very simple and very scalable. 290X packs with it a significant increase in computational resources, so 290X picks up from where 280X left off and tops the chart for AMD once more. Titan is barely half as fast here, and GTX 780 falls back even further. Though the fact that scaling from the 280X to 290X is only 16% – a bit less than half of the increase in CUs – is surprising at first glance. Even with the relatively simplistic nature of the benchmark, it has shown signs in the past of craving memory bandwidth and certainly this seems to be one of those times. Feeding those CUs with new rays takes everything the 320GB/sec memory bus of the 290X can deliver, putting a cap on performance gains versus the 280X.
Our 3rd compute benchmark is Sony Vegas Pro 12, an OpenGL and OpenCL video editing and authoring package. Vegas can use GPUs in a few different ways, the primary uses being to accelerate the video effects and compositing process itself, and in the video encoding step. With video encoding being increasingly offloaded to dedicated DSPs these days we’re focusing on the editing and compositing process, rendering to a low CPU overhead format (XDCAM EX). This specific test comes from Sony, and measures how long it takes to render a video.
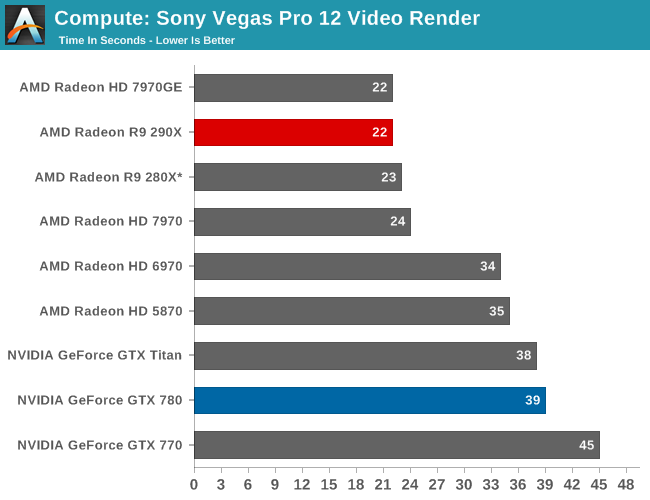
Vegas is another title where GPU performance gains are outpacing CPU performance gains, and as such earlier GPU offloading work has reached its limits and led to the program once again being CPU limited. It’s a shame GPUs have historically underdelivered on video encoding (as opposed to video rendering), as wringing significantly more out of Vegas will require getting rid of the next great CPU bottleneck.
Our 4th benchmark set comes from CLBenchmark 1.1. CLBenchmark contains a number of subtests; we’re focusing on the most practical of them, the computer vision test and the fluid simulation test. The former being a useful proxy for computer imaging tasks where systems are required to parse images and identify features (e.g. humans), while fluid simulations are common in professional graphics work and games alike.
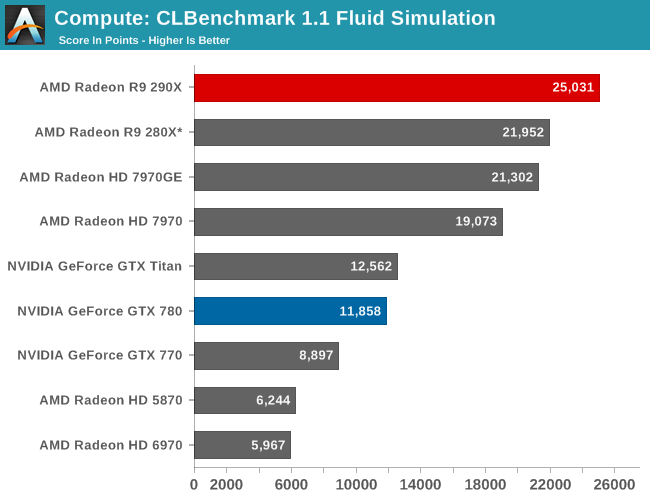

Curiously, the 290X’s performance advantage over 280X is unusual dependent on the specific sub-test. The fluid simulation scales decently enough with the additional CUs, but the computer vision benchmark is stuck in the mud as compared to the 280X. The fluid simulation is certainly closer than the vision benchmark towards being the type of stupidly parallel workload GPUs excel at, though that doesn’t fully explain the lack of scaling in computer vision. If nothing else it’s a good reminder of why professional compute workloads are typically profiled and optimized against specific target hardware, as it reduces these kinds of outcomes in complex, interconnected workloads.
Moving on, our 5th compute benchmark is FAHBench, the official Folding @ Home benchmark. Folding @ Home is the popular Stanford-backed research and distributed computing initiative that has work distributed to millions of volunteer computers over the internet, each of which is responsible for a tiny slice of a protein folding simulation. FAHBench can test both single precision and double precision floating point performance, with single precision being the most useful metric for most consumer cards due to their low double precision performance. Each precision has two modes, explicit and implicit, the difference being whether water atoms are included in the simulation, which adds quite a bit of work and overhead. This is another OpenCL test, as Folding @ Home has moved exclusively to OpenCL this year with FAHCore 17.
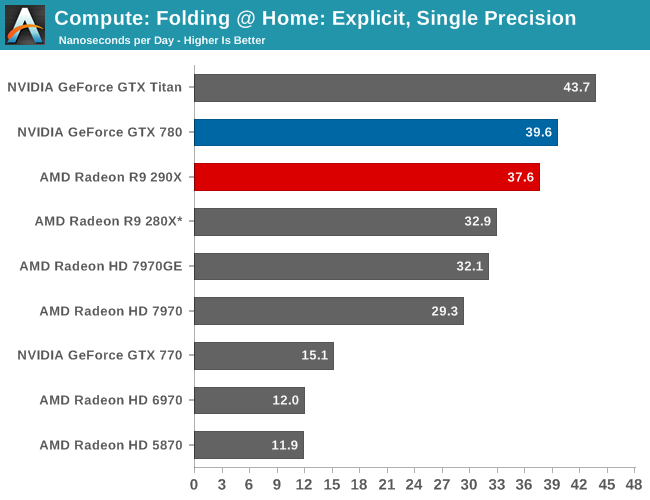

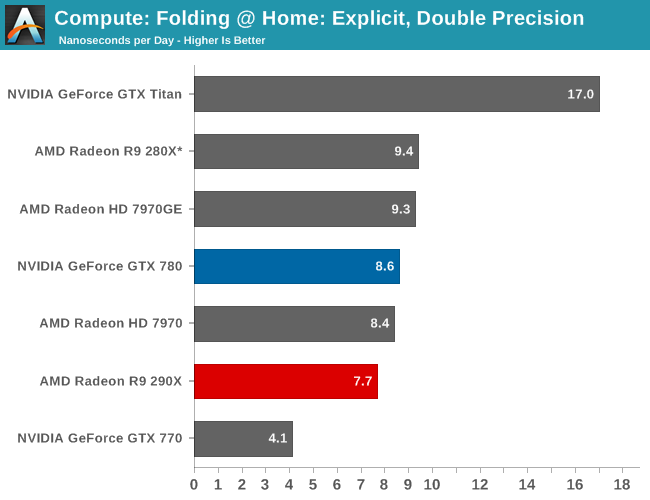
With FAHBench we’re not fully convinced that it knows how to best handle 290X/Hawaii as opposed to 280X/Tahiti. The scaling in single precision explicit is fairly good, but the performance regression in the water-free (and generally more GPU-limited) implicit simulation is unexpected. Consequently while the results are accurate for FAHCore 17, it’s hopefully something AMD and/or the FAH project can work out now that 290X has been released.
Meanwhile double precision performance also regresses, though here we have a good idea why. With DP performance on 290X being 1/8 FP32 as opposed to ¼ on 280X, this is a benchmark 290X can’t win. Though given the theoretical performance differences we should be expecting between the two video cards – 290X should have about 70% of the FP 64 performance of 280X – the fact that 290X is at 82% bodes well for AMD’s newest GPU. However there’s no getting around the fact that the 290X loses to GTX 780 here even though the GTX 780 is even more harshly capped, which given AMD’s traditional strength in OpenCL compute performance is going to be a let-down.
Wrapping things up, our final compute benchmark is an in-house project developed by our very own Dr. Ian Cutress. SystemCompute is our first C++ AMP benchmark, utilizing Microsoft’s simple C++ extensions to allow the easy use of GPU computing in C++ programs. SystemCompute in turn is a collection of benchmarks for several different fundamental compute algorithms, as described in this previous article, with the final score represented in points. DirectCompute is the compute backend for C++ AMP on Windows, so this forms our other DirectCompute test.
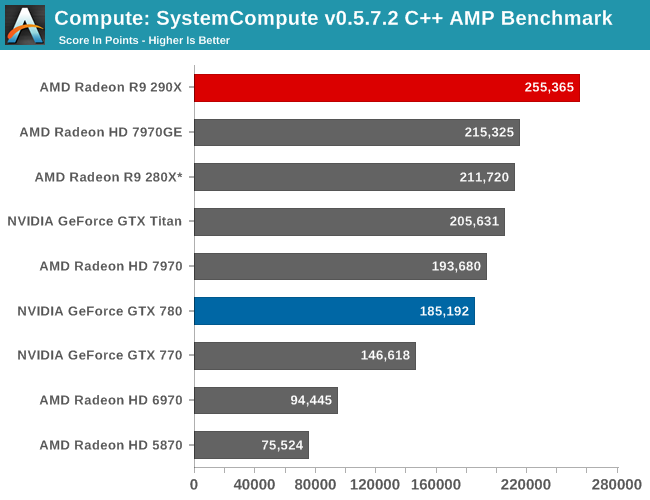
SystemCompute and the underlying C++ AMP environment scales relatively well with the additional CUs offered by 290X. Not only does the 290X easily surpass the GTX Titan and GTX 780 here, but it does so while also beating the 280X by 18%. Or to use AMD’s older GPUs as a point of comparison, we’re up to a 3.4x improvement over 5870, well above the improvement in CU density alone and another reminder of how AMD has really turned things around on the GPU compute side with GCN.








396 Comments
View All Comments
TheJian - Friday, October 25, 2013 - link
Incorrect. Part of the point of gsync is when you can do 200fps in a particular part of the game they can crank up detail and USE the power you have completely rather than making the whole game for say 60fps etc. Then when all kinds of crap is happening on screen (50 guys shooting each other etc) they can drop the graphics detail down some to keep things smooth. Gsync isn't JUST frame rate. You apparently didn't read the anandtech live blog eh? You get your cake and can eat it too (stutter free, no tearing, smooth and extra power used when you have it available).MADDER1 - Friday, October 25, 2013 - link
If Gsync drops the detail to maintain fps like you said, then you're really not getting the detail you thought you set. How is that having your cake and eating it too?Cellar Door - Friday, October 25, 2013 - link
How so? If Mantle gets 760gtx performance in BF4 from a 260X ..will you switch then?Animalosity - Sunday, October 27, 2013 - link
No. You are sadly mistaken sir.Antiflash - Thursday, October 24, 2013 - link
I've usually prefer Nvidia Cards, but they have it well deserved when decided to price GK110 to the stratosphere just "because they can" and had no competition. That's poor way to treat your customers and taking advantage of fanboys. Full implementation of Tesla and Fermi were always priced around $500. Pricing Keppler GK110 at $650+ was stupid. It's silicon after all, you should get more performance for the same price each year. Not more performance at a premium price as Nvidia tried to do this generation. AMD is not doing anything extraordinary here they are just not following nvidia price gouging practices and $550 is their GPU at historical market prices for their flagship GPU. We would not have been having this discussion if Nvidia had done the same with GK110.inighthawki - Thursday, October 24, 2013 - link
" It's silicon after all, you should get more performance for the same price each year"So R&D costs come from where, exactly? Not sure why people always forget that there is actual R&D that goes into these types of products, it's not just some $5 just of plastic and silicon + some labor and manufacturing costs. Like when they break down phones and tablets and calculate costs they never account for this. As if their engineers are basically just selecting components on newegg and plugging them together.
jecastejon - Thursday, October 24, 2013 - link
R&D. Is R&D tied only to a specific Nvidia card? AMD as others also invest a lot in R&D with every product generation, even if they are not successful. Nvidia will have to do a reality cheek with their pricing and be loyal to their fans and the market. Today's advantages don't last for to long.Antiflash - Thursday, October 24, 2013 - link
NVIDIA's logic. Kepler refresh: 30% more performance => 100% increase in priceAMD's logic. GCN refresh: is 30% more preformance => 0% increase in price
I can't see how this is justified by R&D of just a greedy company squishing its more loyal customer base.
Antiflash - Thursday, October 24, 2013 - link
Just for clarification. price comparison between cards at its introduction comparing NVIDIA's 680 vs Titan and AMD's 7970 vs 290xTheJian - Friday, October 25, 2013 - link
AMD way=ZERO PROFITS company going broke, debt high, 6Bil losses in 10yrsNV way=500-800mil profits per year so you can keep your drivers working.
Your love of AMD's pricing is dumb. They are broke. They have sold nearly everything they have or had, fabs, land, all that is left is the company itself and IP.
AMD should have priced this card at $650 period. Also note, NV hasn't made as much money as 2007 for 6 years. They are not gouging you or they would make MORE than before in 2007 right? Intel, Apple, MS are gouging you as they all make more now than then (2007 was pretty much highs for a lot of companies, down since). People like you make me want to vomit as you just are KILLING AMD, which in turn will eventually cost me dearly buying NV cards as they will be the only ones with real power in the next few years. AMD already gave up the cpu race. How much longer you think they can fund the gpu race with no profits? 200mil owed to GF in Dec 31, so the meager profit they made last Q and any they might have made next Q is GONE. They won't make 200mil profit next Q...LOL. Thanks to people like you asking for LOW pricing and free games.
You don't even understand you are ANTI-AMD...LOL. Your crap logic is killing them (and making NV get 300mil less profit than 2007). The war is hurting them both. I'd rather have AMD making 500mil and NV making 1B than what we get now AMD at ZERO and NV at 550mil.