Battle of the 4 TB NAS Drives: WD Red and Seagate NAS HDD Face-Off
by Ganesh T S on September 4, 2013 6:00 AM EST- Posted in
- NAS
- Seagate
- HDDs
- Western Digital
- Enterprise
Performance - Raw Drives
Prior to evaluating the performance of the drives in a NAS environment, we wanted to check up on the best-case performance of the drives by connecting them directly to a SATA 6 Gbps port. Using HD Tune Pro 5.0, we ran a number of tests on the raw drives. The following screenshots present the results for the various drives in an easy-to-compare manner.
Sequential Reads
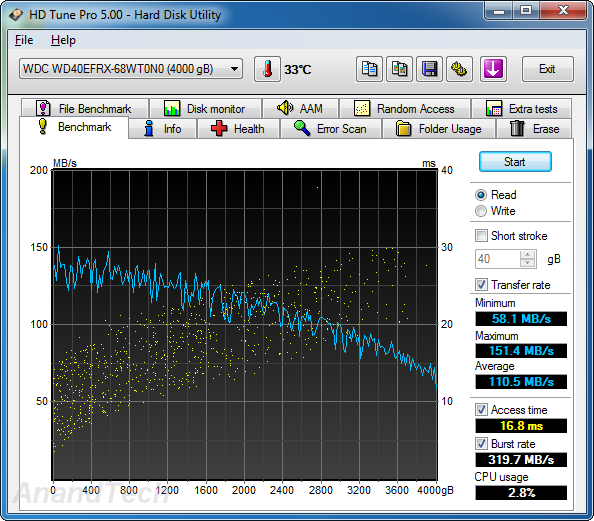
The WD Se and WD Re drives, as expected, lead the benchmark numbers with an average transfer rate of around 136 MBps. The Seagate unit (135 MBps) performs better than the WD Red (111 MBps) in terms of raw data transfer rates, thanks to the higher rotational speed. However, the burst rate of the Seagate NAS HDD is much lower than that of the WD Red. This is probably because the DDR2 memory used in the WD drives is clocked higher than the one in the NAS HDD.
Sequential Writes
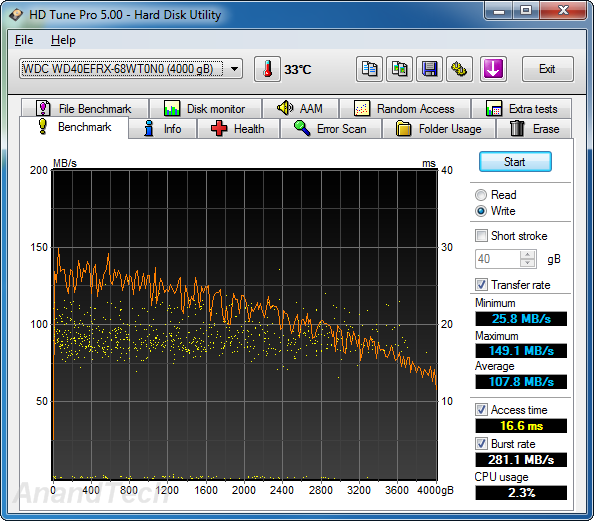
A similar scenario plays out in the sequential write benchmarks. The WD Re leads the pack with an average transfer rate of 135 MBps and the WD Se follows close behind at 133 MBps. The WD Red comes in at 108 MBps and the Seagate NAS HDD clocks in at 131 MBps. The on-board cache in the WD series is faster than that on the Seagate unit, leading to better burst rates.
Random Reads
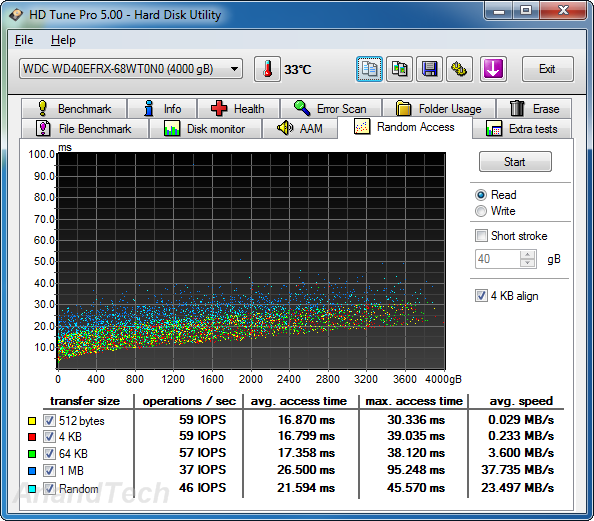
In the random read benchmarks, the WD Red and Seagate NAS HDD perform fairly similar to each other in terms of IOPS as well as average access time. The WD Re edges out the WD Se despite similar rotational speeds and platter structure.
Random Writes
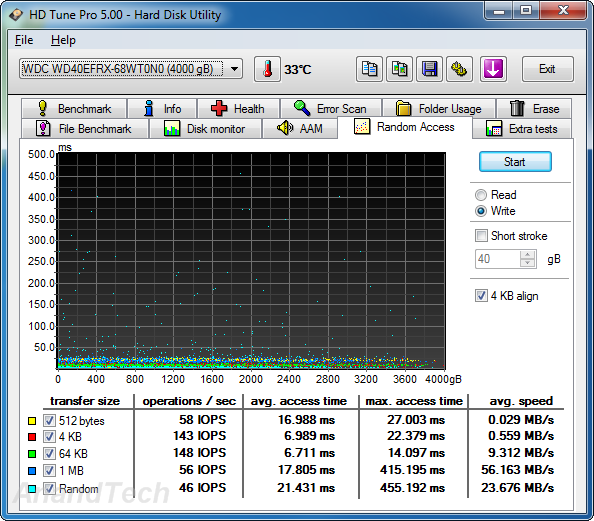
The differences between the enterprise-class drives and the consumer / SOHO NAS drives is even more pronounced in the random write benchmark numbers. The Seagate NAS HDD loses out in terms of both IOPS and average access time to the WD Red. WD Re and WD Se perform much better in this scenario.
Miscellaneous Reads
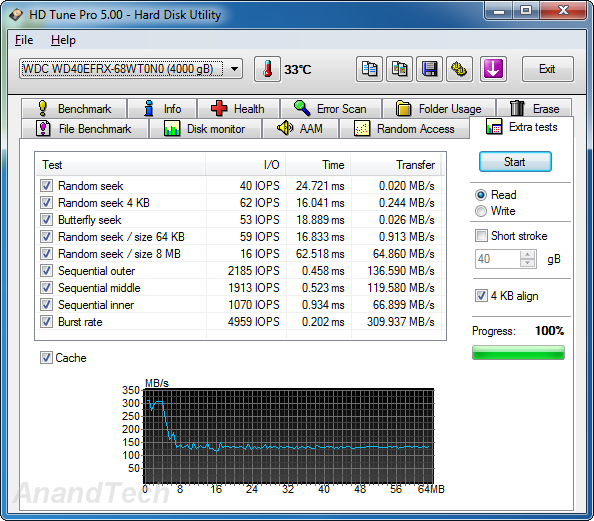
HD Tune Pro also includes a suite of miscellaneous tests such as random seeks and sequential accesses in different segments of the hard disk platters. The numbers above show the WD Red and Seagate NAS HDD matched much more evenly with the NAS HDD emerging slightly better in quite a few of the tests. The cache effects are also visible in the final graph.
Miscellaneous Writes
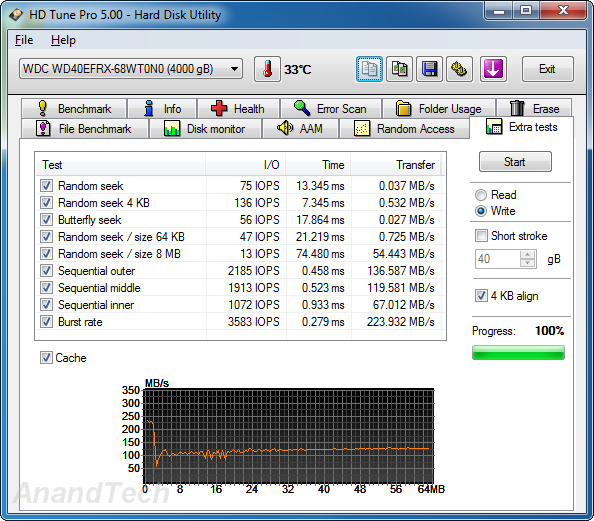
Similar to the previous sub-section, we find that the WD Red edges out the Seagate NAS HDD in the 4KB random seek test, but loses out in a majority of the other tests which are heavily influenced by the rotational speed.
We now have an idea of the standalone performance of the four drives being considered today. In the next section, we will take a look at the performance of these drives when placed inside a typical SOHO / consumer NAS.








54 Comments
View All Comments
dingetje - Thursday, September 5, 2013 - link
thanks GaneshArbie - Wednesday, September 4, 2013 - link
Ignorant here, but I want to raise the issue. In casual research on a home NAS w/RAID I ran across a comment that regular drives are not suitable for that service because of their threshhold for flagging errors. IIRC the point was that they would wait longer to do so, and in a RAID situation that could make eventual error recovery very difficult. Drives designed for RAID use would flag errors earlier. I came away mostly with the idea that you should only build a NAS / RAID setup with drives (eg the WD Red series) designed for that.Is this so?
fackamato - Wednesday, September 4, 2013 - link
Arbie, good point. You're talking about SCTERC. Some consumer drives allow you to alter that timeout, some don't.brshoemak - Wednesday, September 4, 2013 - link
A VERY broad and simplistic explanation is that "RAID enabled" drives will limit the amount of time they spend attempting to correct an error. The RAID controller needs to stay in constant contact with the drives to make sure the arrays integrity is intact.A normal consumer drive will spend much more time trying to correct an internal error. During this time, the RAID controller cannot talk to the drive because it is otherwise occupied . Because the drive is no longer responding to requests from the RAID controller (as it's now doing it's own thing), the controller drops the drive out of the array - which can be a very bad thing.
Different ERC (error recovery control) methods like TLER and CCTL limit the time a drive spends trying to correct the error so it will be able to respond to requests from the RAID controller and ensure the drive isn't dropped from the array.
Basically a RAID controller is like "yo dawg, you still there?" - With TLER/CCTL the drive's all like "yeah I'm here" so everything is cool. Without TLER the drive might just be busy fixing the toilet and takes too long to answer so the RAID controller just assumes no one is home and ditches its friend.
tjoynt - Wednesday, September 4, 2013 - link
brshoemak, that was the clearest and most concise (not to mention funniest) explanation of TLER/CCTL that I've come across. For some reason, most people tend to confuse things and make it more complicated than it is.ShieTar - Wednesday, September 4, 2013 - link
I can't really follow that reasoning, maybe I am missing something. First off, error checking should in general be done by the RAID system, not by the drive electronic. Second off, you can always successfully recover the RAID after replacing one single drive. So the only way to run into a problem is not noticing a damage to one drive before a second drive is also damaged. I've been using cheap drives in RAID-1 configurations for over a decade now, and while several drives have died in that period, I've never had a RAID complain about not being able to restore.Maybe it is only relevant on very large RAID seeing very heavy use? I agree, I'd love to hear somebody from AT comment on this risk.
DanNeely - Wednesday, September 4, 2013 - link
"you can always successfully recover the RAID after replacing one single drive."This isn't true. If you get any errors during the rebuilt and only had a single redundancy drive for the data being recovered the raid controller will mark the array as unrecoverable. Current drive capacities are high enough that raid5 has basically been dead in the enterprise for several years due to the risk of losing it all after a single drive failure being too high.
Rick83 - Wednesday, September 4, 2013 - link
If you have a home usage scenario though, you can schedule surface scans to run every other day, in that case this becomes essentially a non-issue, At worst you'll lose a handful of KB or so.And of course you have backups to cover anything going wrong on a separate array.
Of course, going RAID 5 beyond 6 disks is being slightly reckless, but that's still 20TB.
By the time you manage that kind of data, ZFS is there for you.
Dribble - Wednesday, September 4, 2013 - link
My experience for home usage is raid 1, or no raid at all and regular backups is best. Raid 5 is too complex for it's own good and never seems to be as reliable or repair like it's meant too. Because data is spread over several disks if it gets upset and goes wrong it's very hard to repair and you can loose everything. Also because you think you are safe you don't back up as often as you should so you suffer the most.Raid 1 or no raid means a single disk has a full copy of the data so is most likely to work if you run a disk repair program over it. No raid also focuses the mind on backups so if it goes chances are you'll have a very recent backup and loose hardly any data.
tjoynt - Wednesday, September 4, 2013 - link
++ this too. If you *really* need volume sizes larger than 4TB (the size of a single drive or RAID-1), you should bite the bullet and get a pro-class raid-6 or raid-10 system or use a software solution like ZFS or Windows Server 2012 Storage Space (don't know how reliable that is though). Don't mess with consumer-level striped-parity RAID: it will fail when you most need it. Even pro-class hardware fails, but it does so more gracefully, so you can usually recover your data in the end.