Intel Iris Pro 5200 Graphics Review: Core i7-4950HQ Tested
by Anand Lal Shimpi on June 1, 2013 10:01 AM ESTAddressing the Memory Bandwidth Problem
Integrated graphics solutions always bumped into a glass ceiling because they lacked the high-speed memory interfaces of their discrete counterparts. As Haswell is predominantly a mobile focused architecture, designed to span the gamut from 10W to 84W TDPs, relying on a power-hungry high-speed external memory interface wasn’t going to cut it. Intel’s solution to the problem, like most of Intel’s solutions, involves custom silicon. As a owner of several bleeding edge foundries, would you expect anything less?
As we’ve been talking about for a while now, the highest end Haswell graphics configuration includes 128MB of eDRAM on-package. The eDRAM itself is a custom design by Intel and it’s built on a variant of Intel’s P1271 22nm SoC process (not P1270, the CPU process). Intel needed a set of low leakage 22nm transistors rather than the ability to drive very high frequencies which is why it’s using the mobile SoC 22nm process variant here.
Despite its name, the eDRAM silicon is actually separate from the main microprocessor die - it’s simply housed on the same package. Intel’s reasoning here is obvious. By making Crystalwell (the codename for the eDRAM silicon) a discrete die, it’s easier to respond to changes in demand. If Crystalwell demand is lower than expected, Intel still has a lot of quad-core GT3 Haswell die that it can sell and vice versa.
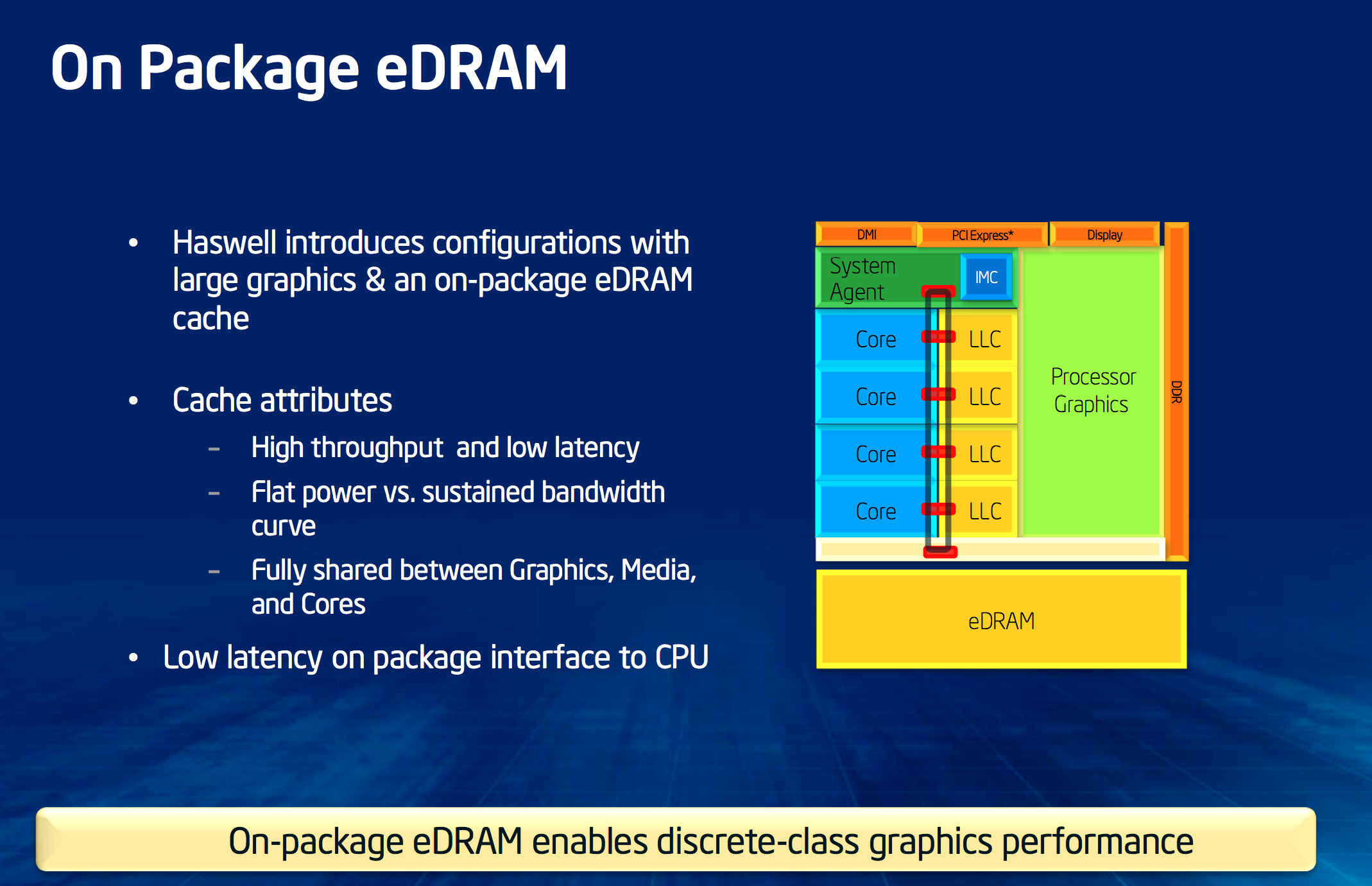
Crystalwell Architecture
Unlike previous eDRAM implementations in game consoles, Crystalwell is true 4th level cache in the memory hierarchy. It acts as a victim buffer to the L3 cache, meaning anything evicted from L3 cache immediately goes into the L4 cache. Both CPU and GPU requests are cached. The cache can dynamically allocate its partitioning between CPU and GPU use. If you don’t use the GPU at all (e.g. discrete GPU installed), Crystalwell will still work on caching CPU requests. That’s right, Haswell CPUs equipped with Crystalwell effectively have a 128MB L4 cache.
Intel isn’t providing much detail on the connection to Crystalwell other than to say that it’s a narrow, double-pumped serial interface capable of delivering 50GB/s bi-directional bandwidth (100GB/s aggregate). Access latency after a miss in the L3 cache is 30 - 32ns, nicely in between an L3 and main memory access.
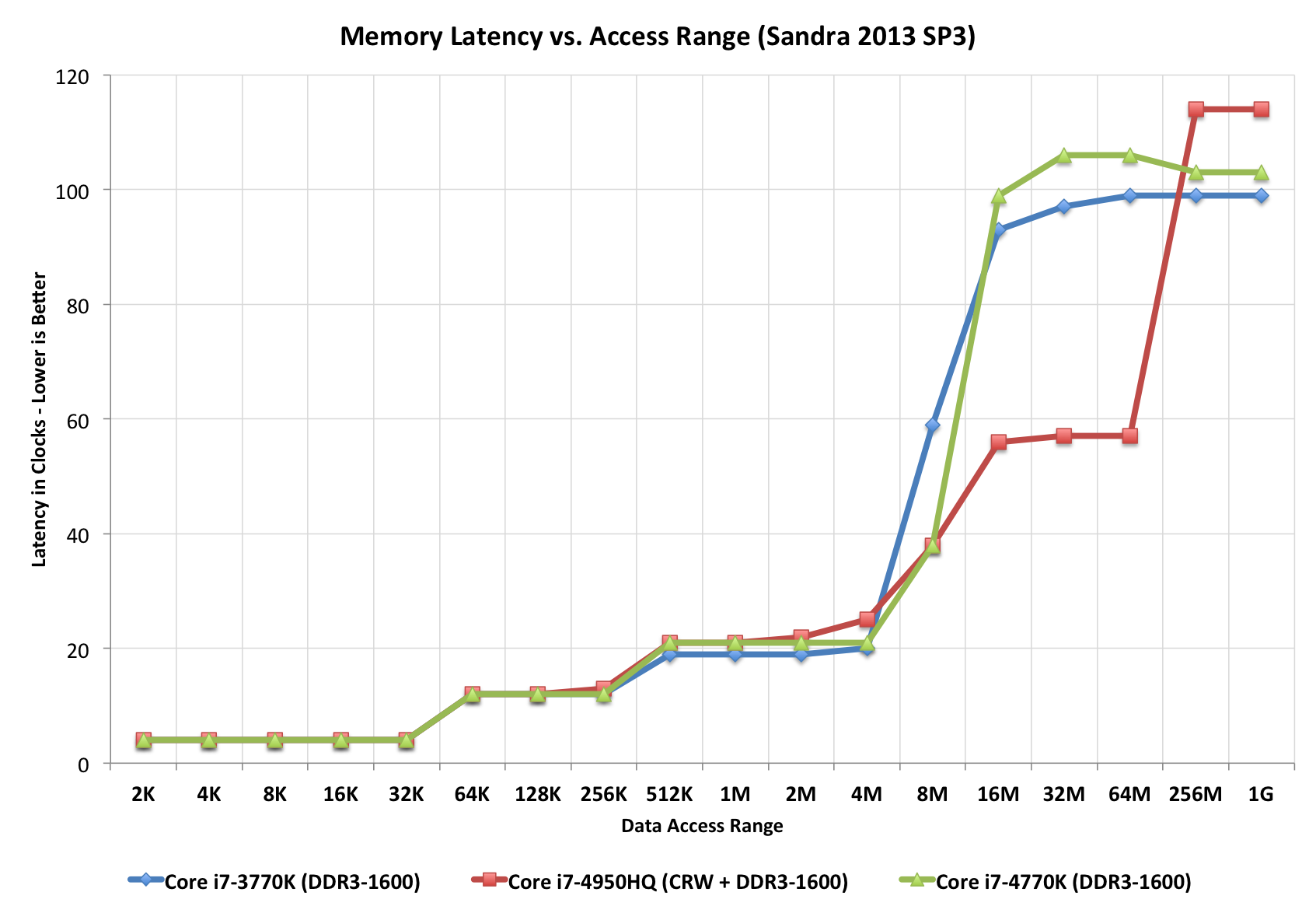
The eDRAM clock tops out at 1.6GHz.
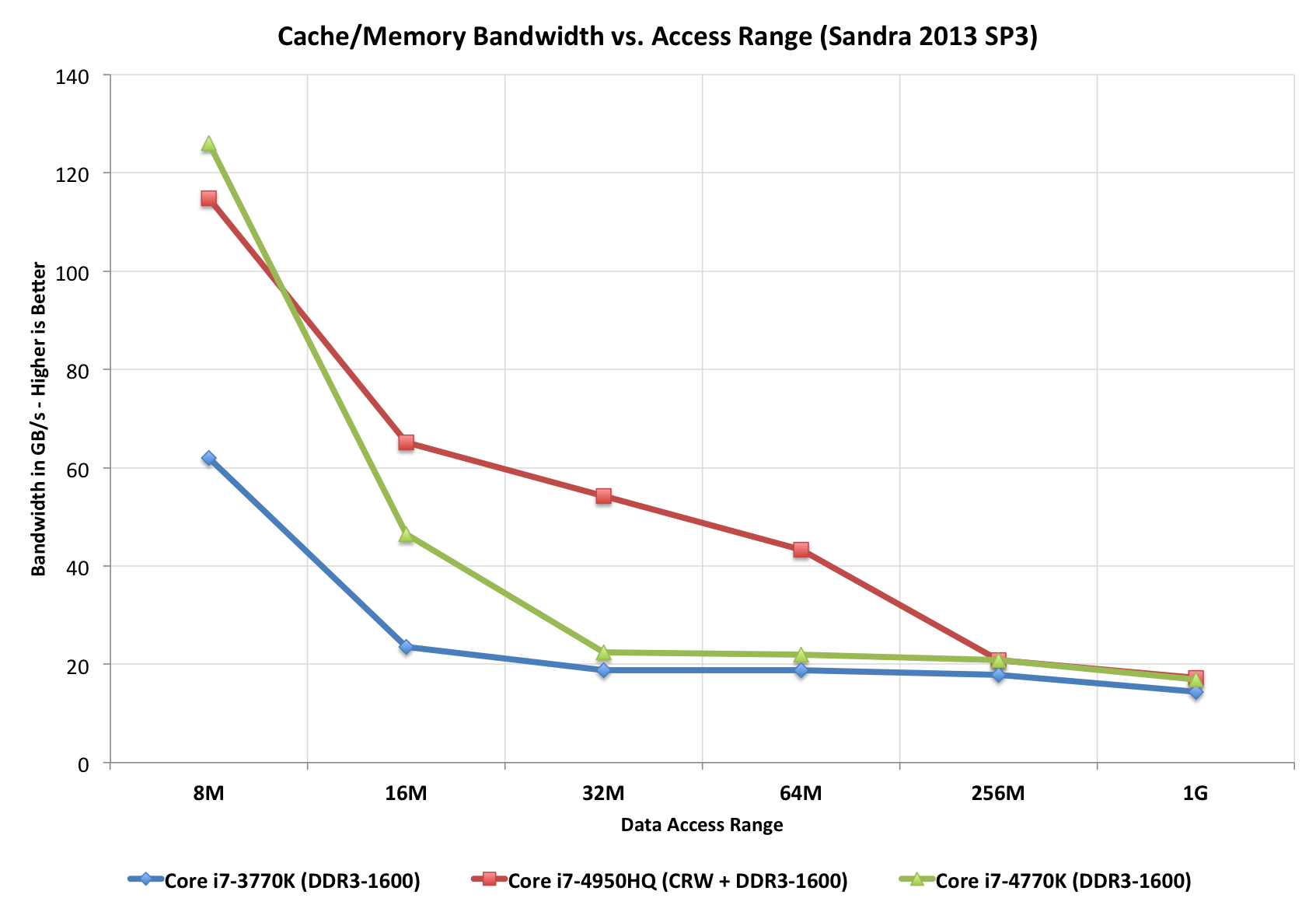
There’s only a single size of eDRAM offered this generation: 128MB. Since it’s a cache and not a buffer (and a giant one at that), Intel found that hit rate rarely dropped below 95%. It turns out that for current workloads, Intel didn’t see much benefit beyond a 32MB eDRAM however it wanted the design to be future proof. Intel doubled the size to deal with any increases in game complexity, and doubled it again just to be sure. I believe the exact wording Intel’s Tom Piazza used during his explanation of why 128MB was “go big or go home”. It’s very rare that we see Intel be so liberal with die area, which makes me think this 128MB design is going to stick around for a while.
The 32MB number is particularly interesting because it’s the same number Microsoft arrived at for the embedded SRAM on the Xbox One silicon. If you felt that I was hinting heavily at the Xbox One being ok if its eSRAM was indeed a cache, this is why. I’d also like to point out the difference in future proofing between the two designs.
The Crystalwell enabled graphics driver can choose to keep certain things out of the eDRAM. The frame buffer isn’t stored in eDRAM for example.
| Peak Theoretical Memory Bandwidth | ||||||||||||||||
| Memory Interface | Memory Frequency | Peak Theoretical Bandwidth | ||||||||||||||
| Intel Iris Pro 5200 | 128-bit DDR3 + eDRAM | 1600MHz + 1600MHz eDRAM | 25.6GB/s + 50GB/s eDRAM (bidirectional) | |||||||||||||
| NVIDIA GeForce GT 650M | 128-bit GDDR5 | 5016MHz | 80.3 GB/s | |||||||||||||
| Intel HD 5100/4600/4000 | 128-bit DDR3 | 1600MHz | 25.6GB/s | |||||||||||||
| Apple A6X | 128-bit LPDDR2 | 1066MHz | 17.1 GB/s | |||||||||||||
Intel claims that it would take a 100 - 130GB/s GDDR memory interface to deliver similar effective performance to Crystalwell since the latter is a cache. Accessing the same data (e.g. texture reads) over and over again is greatly benefitted by having a large L4 cache on package.
I get the impression that the plan might be to keep the eDRAM on a n-1 process going forward. When Intel moves to 14nm with Broadwell, it’s entirely possible that Crystalwell will remain at 22nm. Doing so would help Intel put older fabs to use, especially if there’s no need for a near term increase in eDRAM size. I asked about the potential to integrate eDRAM on-die, but was told that it’s far too early for that discussion. Given the size of the 128MB eDRAM on 22nm (~84mm^2), I can understand why. Intel did float an interesting idea by me though. In the future it could integrate 16 - 32MB of eDRAM on-die for specific use cases (e.g. storing the frame buffer).
Intel settled on eDRAM because of its high bandwidth and low power characteristics. According to Intel, Crystalwell’s bandwidth curve is very flat - far more workload independent than GDDR5. The power consumption also sounds very good. At idle, simply refreshing whatever data is stored within, the Crystalwell die will consume between 0.5W and 1W. Under load, operating at full bandwidth, the power usage is 3.5 - 4.5W. The idle figures might sound a bit high, but do keep in mind that since Crystalwell caches both CPU and GPU memory it’s entirely possible to shut off the main memory controller and operate completely on-package depending on the workload. At the same time, I suspect there’s room for future power improvements especially as Crystalwell (or a lower power derivative) heads towards ultra mobile silicon.
Crystalwell is tracked by Haswell’s PCU (Power Control Unit) just like the CPU cores, GPU, L3 cache, etc... Paying attention to thermals, workload and even eDRAM hit rate, the PCU can shift power budget between the CPU, GPU and eDRAM.
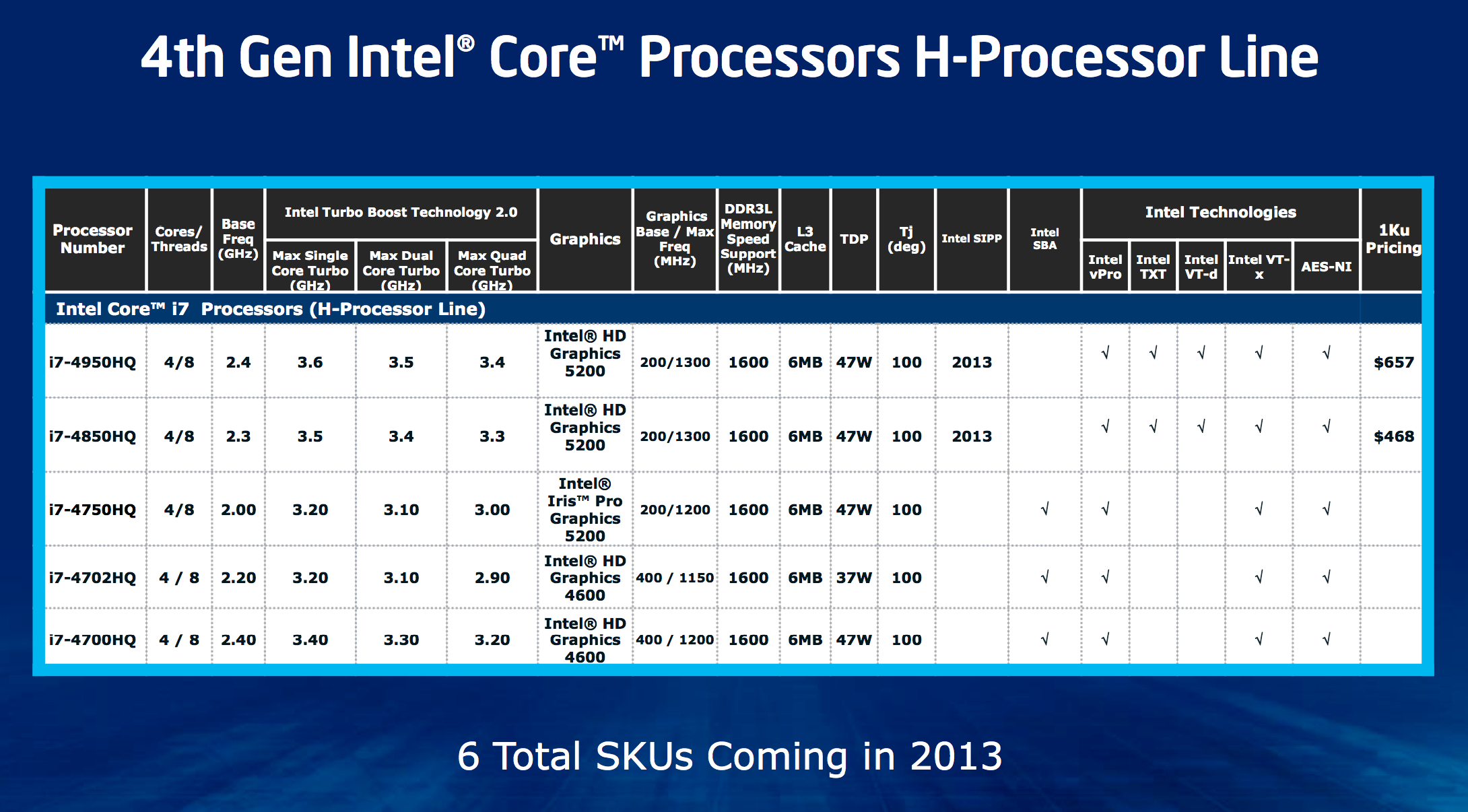
Crystalwell is only offered alongside quad-core GT3 Haswell. Unlike previous generations of Intel graphics, high-end socketed desktop parts do not get Crystalwell. Only mobile H-SKUs and desktop (BGA-only) R-SKUs have Crystalwell at this point. Given the potential use as a very large CPU cache, it’s a bit insane that Intel won’t even offer a single K-series SKU with Crystalwell on-board.
As for why lower end parts don’t get it, they simply don’t have high enough memory bandwidth demands - particularly in GT1/GT2 graphics configurations. According to Intel, once you get to about 18W then GT3e starts to make sense but you run into die size constraints there. An Ultrabook SKU with Crystalwell would make a ton of sense, but given where Ultrabooks are headed (price-wise) I’m not sure Intel could get any takers.








177 Comments
View All Comments
kyuu - Saturday, June 1, 2013 - link
It's probably habit coming from eluding censoring.maba - Saturday, June 1, 2013 - link
To be fair, there is only one data point (GFXBenchmark 2.7 T-Rex HD - 4X MSAA) where the 47W cTDP configuration is more than 40% slower than the tested GT 650M (rMBP15 90W).Actually we have the following [min, max, avg, median] for 47W (55W):
games: 61%, 106%, 78%, 75% (62%, 112%, 82%, 76%)
synth.: 55%, 122%, 95%, 94% (59%, 131%, 102%, 100%)
compute: 85%, 514%, 205%, 153% (86%, 522%, 210%, 159%)
overall: 55%, 514%, 101%, 85% (59%, 522%, 106%, 92%)
So typically around 75% for games with a considerably lower TDP - not that bad.
I do not know whether Intel claimed equal or better performance given a specific TDP or not. With the given 47W (55W) compared to a 650M it would indeed be a false claim.
But my point is, that with at least ~60% performance and typically ~75% it is admittedly much closer than you stated.
whyso - Saturday, June 1, 2013 - link
Note your average 650m is clocked lower than the 650m reviewed here.lmcd - Saturday, June 1, 2013 - link
If I recall correctly, the rMBP 650m was clocked as high as or slightly higher than the 660m (which was really confusing at the time).JarredWalton - Sunday, June 2, 2013 - link
Correct. GT 650M by default is usually 835MHz + Boost, with 4GHz RAM. The GTX 660M is 875MHz + Boost with 4GHz RAM. So the rMBP15 is a best-case for GT 650M. However, it's not usually a ton faster than the regular GT 650M -- benchmarks for the UX51VZ are available here:http://www.anandtech.com/bench/Product/814
tipoo - Sunday, June 2, 2013 - link
I think any extra power just went to the rMBP scaling operations.DickGumshoe - Sunday, June 2, 2013 - link
Do you know if the scaling algorithms are handled by the CPU or the GPU on the rMBP?The big thing I am wondering is that if Apple releases a higher-end model with the MQ CPU's, would the HD 4600 be enough to eliminate the UI lag currently present on the rMBP's HD 4000?
If it's done on the GPU, then having the HQ CPU's might actually get *better* UI performance than the MQ CPU's for the rMPB.
lmcd - Sunday, June 2, 2013 - link
No, because these benchmarks would change the default resolution, which as I understand is something the panel would compensate for?Wait, aren't these typically done while the laptop screen is off and an external display is used?
whyso - Sunday, June 2, 2013 - link
You got this wrong. 650m is 735/1000 + boost to 850/1000. 660m is 835/1250 boost to 950/1250.jasonelmore - Sunday, June 2, 2013 - link
worst mistake intel made was that demo with DIRT when it was side by side with a 650m laptop. That set people's expectations. and it falls short in the reviews and people are dogging it. If they would have just kept quite people would be praising them up and down right now.