Intel Iris Pro 5200 Graphics Review: Core i7-4950HQ Tested
by Anand Lal Shimpi on June 1, 2013 10:01 AM ESTHaswell GPU Architecture & Iris Pro
In 2010, Intel’s Clarkdale and Arrandale CPUs dropped the GMA (Graphics Media Accelerator) label from its integrated graphics. From that point on, all Intel graphics would be known as Intel HD graphics. With certain versions of Haswell, Intel once again parts ways with its old brand and introduces a new one, this time the change is much more significant.
Intel attempted to simplify the naming confusion with this slide:
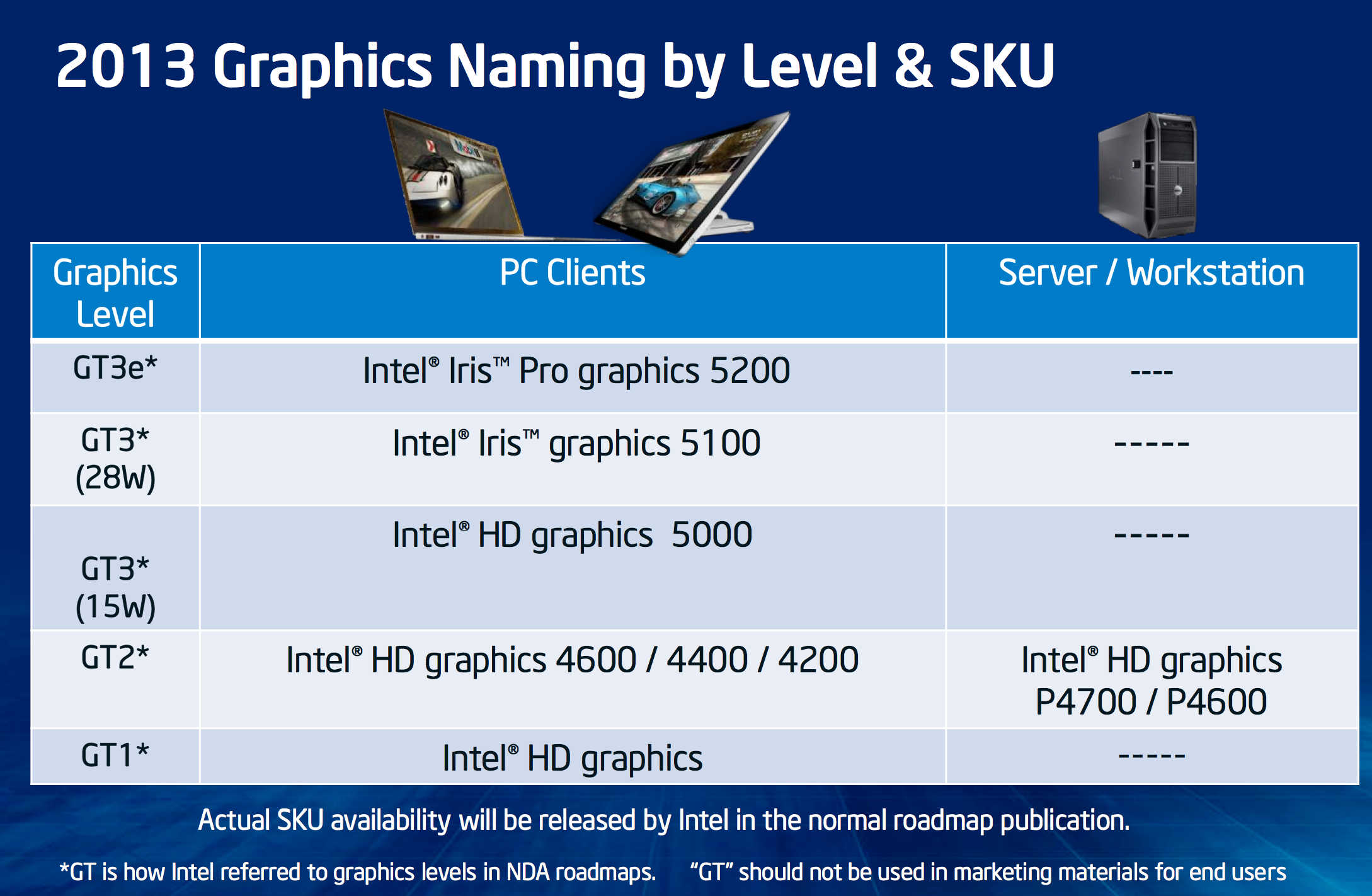
While Sandy and Ivy Bridge featured two different GPU implementations (GT1 and GT2), Haswell adds a third (GT3).
Basically it boils down to this. Haswell GT1 is just called Intel HD Graphics, Haswell GT2 is HD 4200/4400/4600. Haswell GT3 at or below 1.1GHz is called HD 5000. Haswell GT3 capable of hitting 1.3GHz is called Iris 5100, and finally Haswell GT3e (GT3 + embedded DRAM) is called Iris Pro 5200.
The fundamental GPU architecture hasn’t changed much between Ivy Bridge and Haswell. There are some enhancements, but for the most part what we’re looking at here is a dramatic increase in the amount of die area allocated for graphics.
All GPU vendors have some fundamental building block they scale up/down to hit various performance/power/price targets. AMD calls theirs a Compute Unit, NVIDIA’s is known as an SMX, and Intel’s is called a sub-slice.
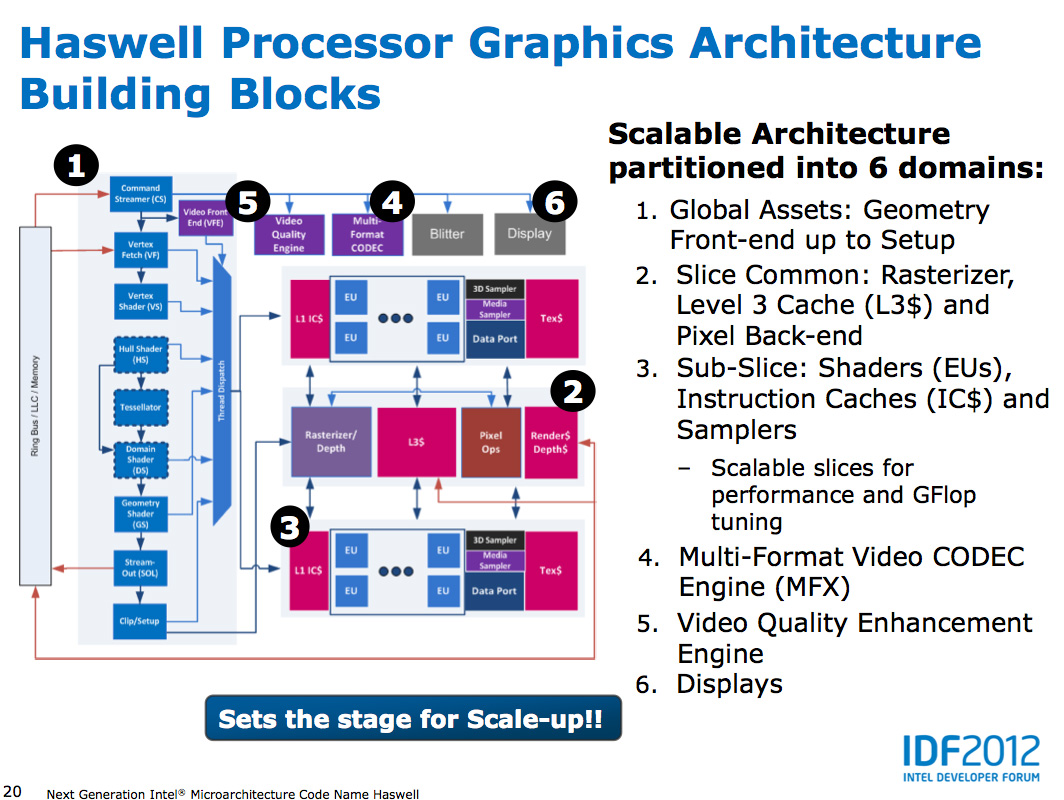
In Haswell, each graphics sub-slice features 10 EUs. Each EU is a dual-issue SIMD machine with two 4-wide vector ALUs:
| Low Level Architecture Comparison | ||||||||||||||||
| AMD GCN | Intel Gen7 Graphics | NVIDIA Kepler | ||||||||||||||
| Building Block | GCN Compute Unit | Sub-Slice | Kepler SMX | |||||||||||||
| Shader Building Block | 16-wide Vector SIMD | 2 x 4-wide Vector SIMD | 32-wide Vector SIMD | |||||||||||||
| Smallest Implementation | 4 SIMDs | 10 SIMDs | 6 SIMDs | |||||||||||||
| Smallest Implementation (ALUs) | 64 | 80 | 192 | |||||||||||||
There are limitations as to what can be co-issued down each EU’s pair of pipes. Intel addressed many of the co-issue limitations last generation with Ivy Bridge, but there are still some that remain.
Architecturally, this makes Intel’s Gen7 graphics core a bit odd compared to AMD’s GCN and NVIDIA’s Kepler, both of which feature much wider SIMD arrays without any co-issue requirements. The smallest sub-slice in Haswell however delivers a competitive number of ALUs to AMD and NVIDIA implementations.
Intel had a decent building block with Ivy Bridge, but it chose not to scale it up as far as it would go. With Haswell that changes. In its highest performing configuration, Haswell implements four sub-slices or 40 EUs. Doing the math reveals a very competent looking part on paper:
| Peak Theoretical GPU Performance | ||||||||||||||||
| Cores/EUs | Peak FP ops per Core/EU | Max GPU Frequency | Peak GFLOPs | |||||||||||||
| Intel Iris Pro 5100/5200 | 40 | 16 | 1300MHz | 832 GFLOPS | ||||||||||||
| Intel HD Graphics 5000 | 40 | 16 | 1100MHz | 704 GFLOPS | ||||||||||||
| NVIDIA GeForce GT 650M | 384 | 2 | 900MHz | 691.2 GFLOPS | ||||||||||||
| Intel HD Graphics 4600 | 20 | 16 | 1350MHz | 432 GFLOPS | ||||||||||||
| Intel HD Graphics 4000 | 16 | 16 | 1150MHz | 294.4 GFLOPS | ||||||||||||
| Intel HD Graphics 3000 | 12 | 12 | 1350MHz | 194.4 GFLOPS | ||||||||||||
| Intel HD Graphics 2000 | 6 | 12 | 1350MHz | 97.2 GFLOPS | ||||||||||||
| Apple A6X | 32 | 8 | 300MHz | 76.8 GFLOPS | ||||||||||||
In its highest end configuration, Iris has more raw compute power than a GeForce GT 650M - and even more than a GeForce GT 750M. Now we’re comparing across architectures here so this won’t necessarily translate into a performance advantage in games, but the takeaway is that with HD 5000, Iris 5100 and Iris Pro 5200 Intel is finally walking the walk of a GPU company.
Peak theoretical performance falls off steeply as soon as you start looking at the GT2 and GT1 implementations. With 1/4 - 1/2 of the execution resources as the GT3 graphics implementation, and no corresponding increase in frequency to offset the loss the slower parts are substantially less capable. The good news is that Haswell GT2 (HD 4600) is at least more capable than Ivy Bridge GT2 (HD 4000).
Taking a step back and looking at the rest of the theoretical numbers gives us a more well rounded look at Intel’s graphics architectures :
| Peak Theoretical GPU Performance | ||||||||||||||||
| Peak Pixel Fill Rate | Peak Texel Rate | Peak Polygon Rate | Peak GFLOPs | |||||||||||||
| Intel Iris Pro 5100/5200 | 10.4 GPixels/s | 20.8 GTexels/s | 650 MPolys/s | 832 GFLOPS | ||||||||||||
| Intel HD Graphics 5000 | 8.8 GPixels/s | 17.6 GTexels/s | 550 MPolys/s | 704 GFLOPS | ||||||||||||
| NVIDIA GeForce GT 650M | 14.4 GPixels/s | 28.8 GTexels/s | 900 MPolys/s | 691.2 GFLOPS | ||||||||||||
| Intel HD Graphics 4600 | 5.4 GPixels/s | 10.8 GTexels/s | 675 MPolys/s | 432 GFLOPS | ||||||||||||
| AMD Radeon HD 7660D (Desktop Trinity, A10-5800K) | 6.4 GPixels/s | 19.2 GTexels/s | 800 MPolys/s | 614 GFLOPS | ||||||||||||
| AMD Radeon HD 7660G (Mobile Trinity, A10-4600M) | 3.97 GPixels/s | 11.9 GTexels/s | 496 MPolys/s | 380 GFLOPS | ||||||||||||
Intel may have more raw compute, but NVIDIA invested more everywhere else in the pipeline. Triangle, texturing and pixel throughput capabilities are all higher on the 650M than on Iris Pro 5200. Compared to AMD's Trinity however, Intel has a big advantage.








177 Comments
View All Comments
kyuu - Saturday, June 1, 2013 - link
It's probably habit coming from eluding censoring.maba - Saturday, June 1, 2013 - link
To be fair, there is only one data point (GFXBenchmark 2.7 T-Rex HD - 4X MSAA) where the 47W cTDP configuration is more than 40% slower than the tested GT 650M (rMBP15 90W).Actually we have the following [min, max, avg, median] for 47W (55W):
games: 61%, 106%, 78%, 75% (62%, 112%, 82%, 76%)
synth.: 55%, 122%, 95%, 94% (59%, 131%, 102%, 100%)
compute: 85%, 514%, 205%, 153% (86%, 522%, 210%, 159%)
overall: 55%, 514%, 101%, 85% (59%, 522%, 106%, 92%)
So typically around 75% for games with a considerably lower TDP - not that bad.
I do not know whether Intel claimed equal or better performance given a specific TDP or not. With the given 47W (55W) compared to a 650M it would indeed be a false claim.
But my point is, that with at least ~60% performance and typically ~75% it is admittedly much closer than you stated.
whyso - Saturday, June 1, 2013 - link
Note your average 650m is clocked lower than the 650m reviewed here.lmcd - Saturday, June 1, 2013 - link
If I recall correctly, the rMBP 650m was clocked as high as or slightly higher than the 660m (which was really confusing at the time).JarredWalton - Sunday, June 2, 2013 - link
Correct. GT 650M by default is usually 835MHz + Boost, with 4GHz RAM. The GTX 660M is 875MHz + Boost with 4GHz RAM. So the rMBP15 is a best-case for GT 650M. However, it's not usually a ton faster than the regular GT 650M -- benchmarks for the UX51VZ are available here:http://www.anandtech.com/bench/Product/814
tipoo - Sunday, June 2, 2013 - link
I think any extra power just went to the rMBP scaling operations.DickGumshoe - Sunday, June 2, 2013 - link
Do you know if the scaling algorithms are handled by the CPU or the GPU on the rMBP?The big thing I am wondering is that if Apple releases a higher-end model with the MQ CPU's, would the HD 4600 be enough to eliminate the UI lag currently present on the rMBP's HD 4000?
If it's done on the GPU, then having the HQ CPU's might actually get *better* UI performance than the MQ CPU's for the rMPB.
lmcd - Sunday, June 2, 2013 - link
No, because these benchmarks would change the default resolution, which as I understand is something the panel would compensate for?Wait, aren't these typically done while the laptop screen is off and an external display is used?
whyso - Sunday, June 2, 2013 - link
You got this wrong. 650m is 735/1000 + boost to 850/1000. 660m is 835/1250 boost to 950/1250.jasonelmore - Sunday, June 2, 2013 - link
worst mistake intel made was that demo with DIRT when it was side by side with a 650m laptop. That set people's expectations. and it falls short in the reviews and people are dogging it. If they would have just kept quite people would be praising them up and down right now.