AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM ESTCompute Unit
Bobcat was pretty simple from a multi-core standpoint. Each Bobcat core had its own private 512KB L2 cache, and all core-to-core communication happened via a bus interface on each of the cores. The cache hierarchy was exclusive, as has been the case with all of AMD’s previous architectures.
Jaguar changes everything. AMD defines a Jaguar compute unit as up to four cores with a single, large, shared L2 cache. The L2 cache can be up to 2MB in size and is 16-way set associative. The L2 cache is also inclusive, a first in AMD’s history. In the past AMD always implemented exclusive caches as the inclusive duplicating of L1 data in L2 meant a smaller effective L2 cache. The larger shared L2 cache is responsible for up to another 5-7% increase in IPC over Bobcat (totaling ~22%).
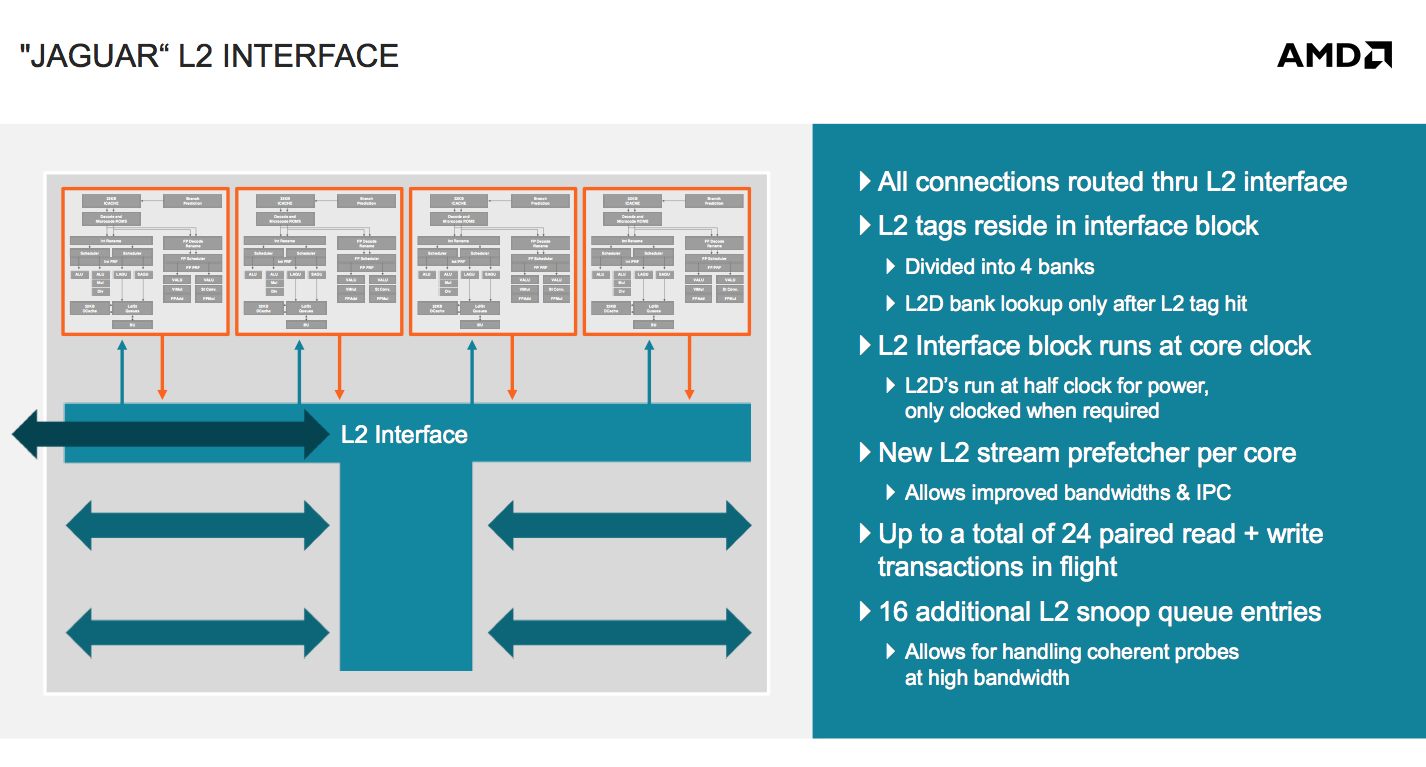
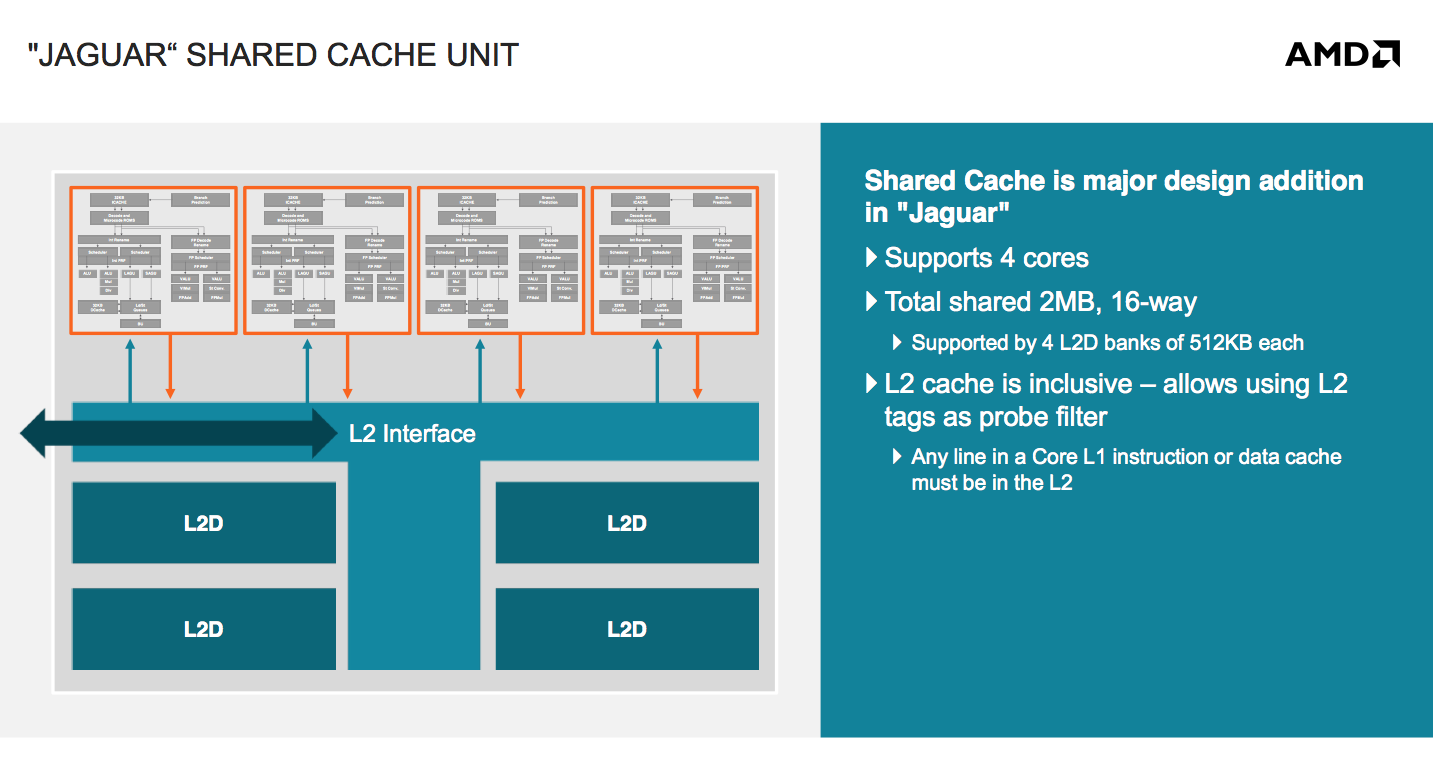
AMD’s new cache architecture and lower latency core-to-core communication within a Jaguar compute unit means an even greater performance advantage over Bobcat in multithreaded workloads:
| Multithreaded Performance Comparison | ||||||||||||||||
| # of Cores | Cinebench 11.5 (Single Threaded) | Cinebench 11.5 (Multithreaded) | ||||||||||||||
| AMD A4-5000 (1.5GHz Jaguar x 4) | 4 | 0.39 | 1.5 | |||||||||||||
| AMD E-350 (1.6GHz Bobcat x 2) | 2 | 0.32 | 0.61 | |||||||||||||
| Advantage | 100% | 21.9% | 145.9% | |||||||||||||
The L1 caches remain unchanged at 32KB/32KB (I/D cache) per core.
Physical Layout and Synthesis
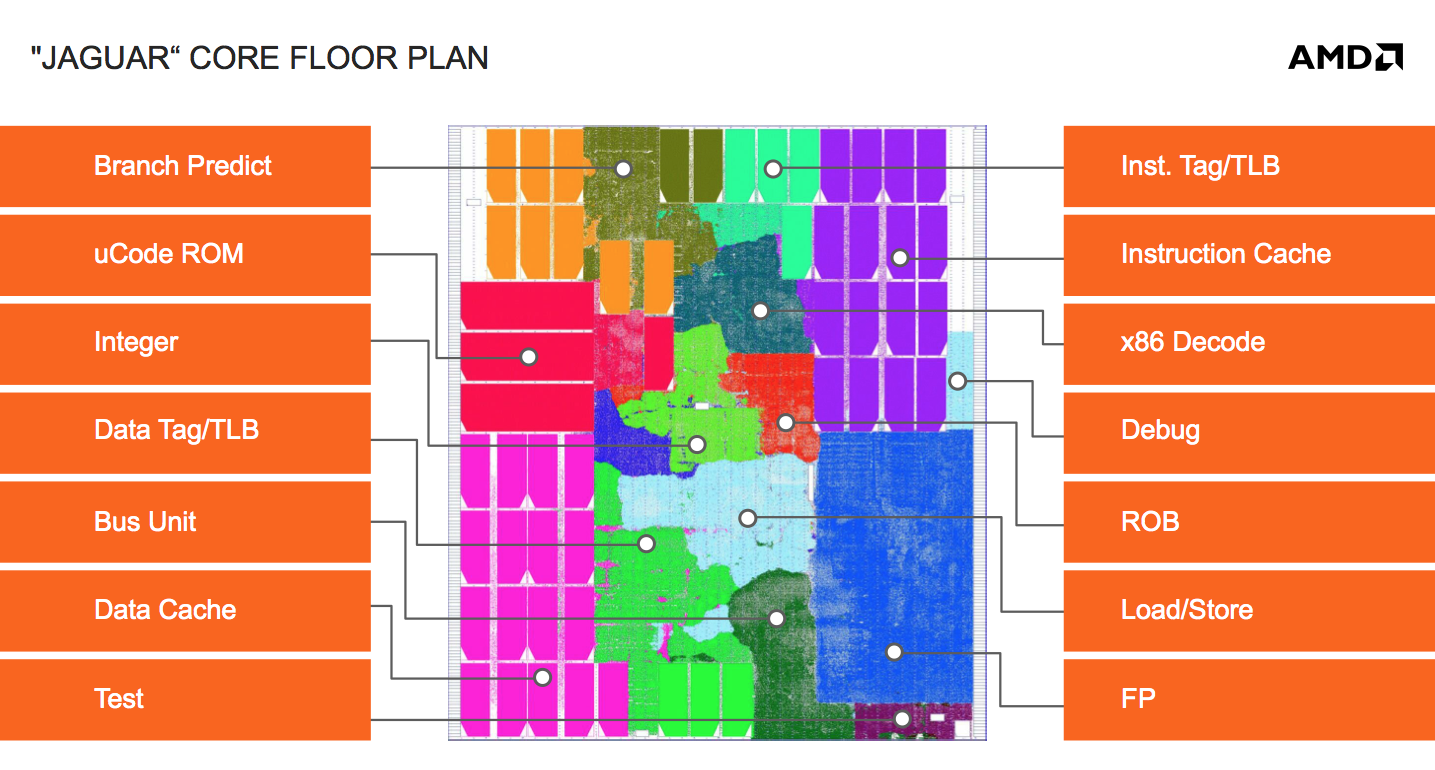
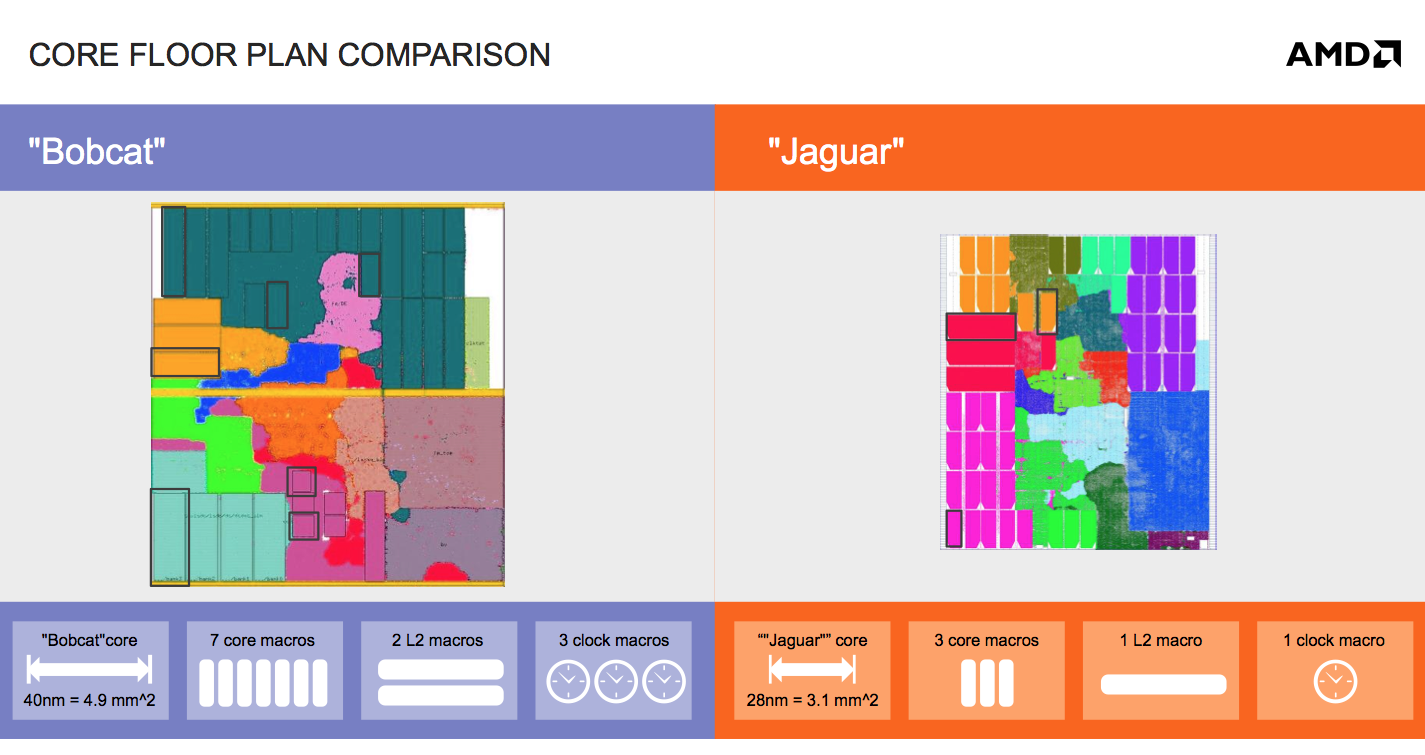
Bobcat was AMD’s first easily synthesized CPU core, it was a direct result of the ATI acquisition years before. With Jaguar, AMD made a conscious effort to further reduce the number of unique macros required by the design. The result was a great simplification, which helped AMD port Jaguar between foundries. There’s of course an area tradeoff when moving away from custom macros to more general designs but it was deemed worthwhile. Looking at the results, you really can’t argue. A single Jaguar core measures only 3.1mm^2 at 28nm compared to 4.9mm^2 for a 40nm Bobcat.








78 Comments
View All Comments
fluxtatic - Thursday, May 23, 2013 - link
Whoa - I think this is the first useful thing I've learned today. I've been wondering the same thing for a long time. Thanks!Ev1l_Ash - Wednesday, May 28, 2014 - link
Thanks for that quasi!Tuna-Fish - Thursday, May 23, 2013 - link
quasi was more accurate than his name implies, but just to expand on it:The count of custom macros is important because when you switch manufacturing processes, the work you have to re-do on the new process is the macros. Old cpus were "all custom macro", meaning that switching the manufacturing process meant re-doing all the physical design. A cpu that has a very limited amount of custom macros can be manufactured at different fabs without breaking the bank.
lmcd - Thursday, May 23, 2013 - link
Sorry, didn't see your post.lmcd - Thursday, May 23, 2013 - link
To suppliment quasi_accurate (as I understand) these are parts of the chip that need checked on, adjusted and corrected, and/or even replaced depending on the foundry.So, reducing these isn't a priority for Intel, but for AMD who wants portability (ability to use both GloFo and TMSC) it's a priority.
tiquio - Thursday, May 23, 2013 - link
Thanks quasi_accurate, Tuna-Fish and lmcd. Your answers were very clear.If I my understanding is correct, would it be safe to assume that Apple's A6 uses custom macros. Anand mentioned in his article that Apple used a custom layout of ARM to maximize performance. Is this one example of custom macros.
name99 - Friday, May 24, 2013 - link
You can customize a variety of things, from individual transistors (eg fast but leaky vs slow but non-leaky), to circuits, to layout.As I understand it the AMD issue is about customized vs automatic CIRCUITS. The Apple issue is about customized vs automatic LAYOUT (ie placement of items and the wiring connecting them).
Transistors are obviously most fab-specific, so you are really screwed if your design depends on them specifically (eg you can't build your finFET design at a non-finFET fab). Circuit design is still somewhat fab-specific --- you can probably get it to run on a different fab, but at lower frequency and higher power, so it's still not where you want to be. Layout, on the other hand, I don't think is very fab-specific at all (unless you do something like use 13 metal layers and then want to move to a fab than can only handle a maximum of 10 metal layers).
I'd be happy to be corrected on any of this, but I think that's the broad outline of the issues.
iwodo - Thursday, May 23, 2013 - link
Really want this to be in Servers. Storage Servers, Home based NAS, caching / front end servers etc.JohanAnandtech - Thursday, May 23, 2013 - link
agree. With a much downsized graphics core, and higher clocks for the CPU.Alex_Haddock - Thursday, May 23, 2013 - link
We will certainly have Kyoto in Moonshot :-) . http://h30507.www3.hp.com/t5/Hyperscale-Computing-...