AMD’s Jaguar Architecture: The CPU Powering Xbox One, PlayStation 4, Kabini & Temash
by Anand Lal Shimpi on May 23, 2013 12:00 AM ESTInteger & FP Execution
On the integer execution side, units and pipelines look largely unchanged from Bobcat. The big performance addition here is the use of Llano’s hardware divider. Bobcat had a microcoded integer divider capable of one bit per cycle, while Jaguar moves to a 2-bits-per-cycle divider. The hardware is all clock gated, so when it’s not in use there’s no power penalty.
The schedulers and re-order buffer are incrementally bigger in Jaguar. Some scheduling changes and other out of order resource increases are at work here as well.
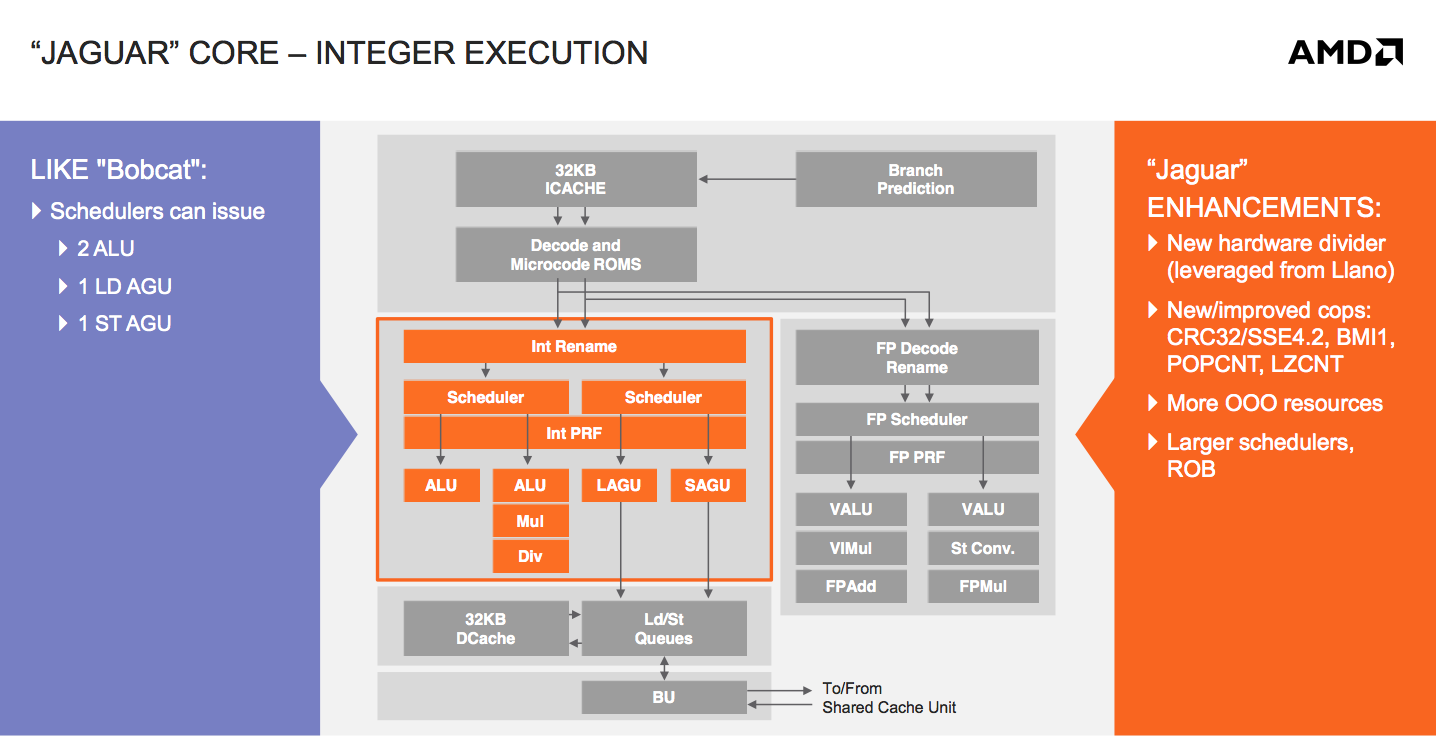
Integer performance wasn’t a huge problem with Bobcat to begin with, but floating point performance was a different issue entirely. In our original Brazos review we found that heavily threaded FP workloads were barely faster on Bobcat than they were on Atom. A big part of that had to do with Atom’s support for Hyper Threading. AMD addressed both issues by beefing up FP execution and doubling up the maximum number of CPU cores with Jaguar (more on this later).
Bobcat’s FP execution units were 64-bits wide. Any 128-bit FP operations had to be chunked up and worked on in stages. In Jaguar, AMD moved all of its units to 128-bits wide. AVX operations complete as 2 x 128-bit operations, while all other 128-bit operations can execute without multiple passes through the pipeline. The increase in vector width is responsible for the gains in FP performance.
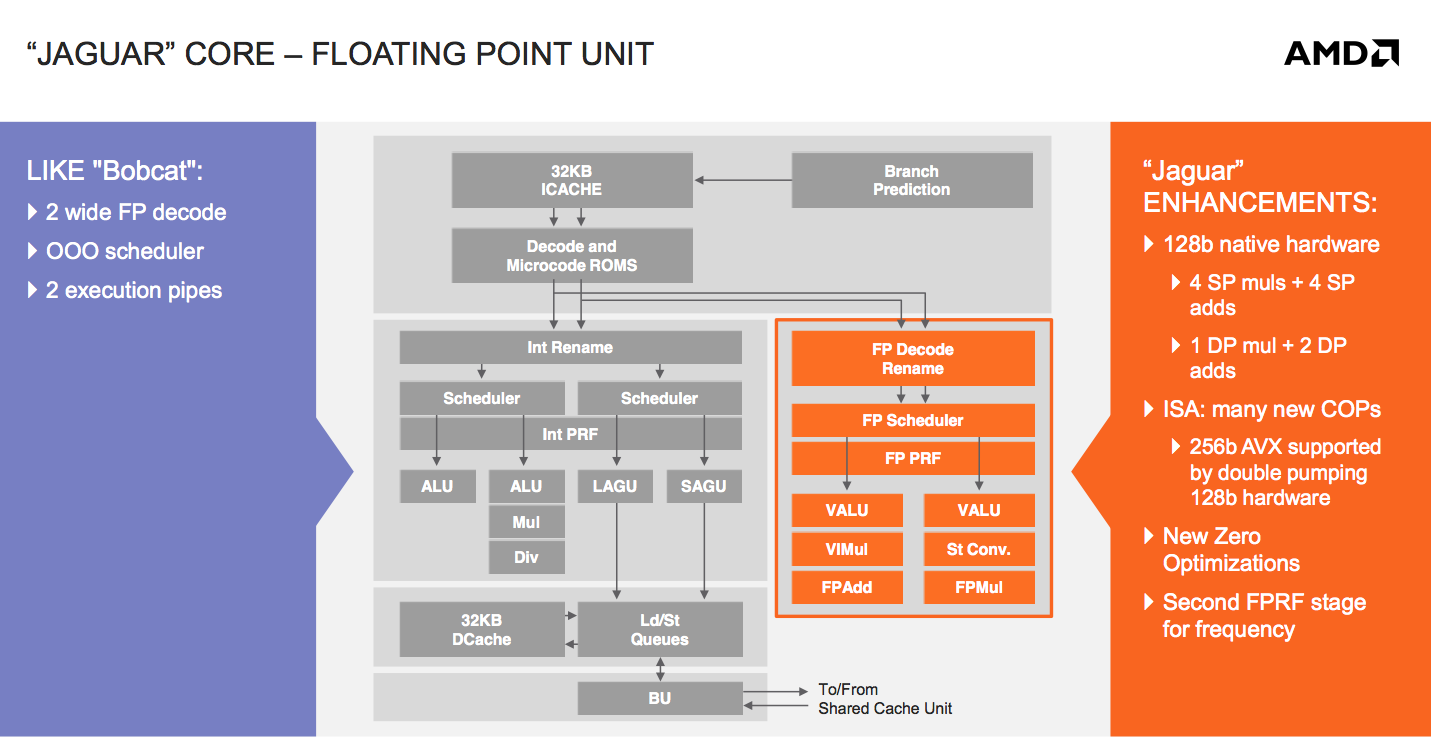
The move to 128-bit vectors in the FPU forced AMD to add another pipeline stage here as well. The increase in FPU size meant that some signals needed a little extra time to get from one location to the next, hence the extra stage.
Load/Store
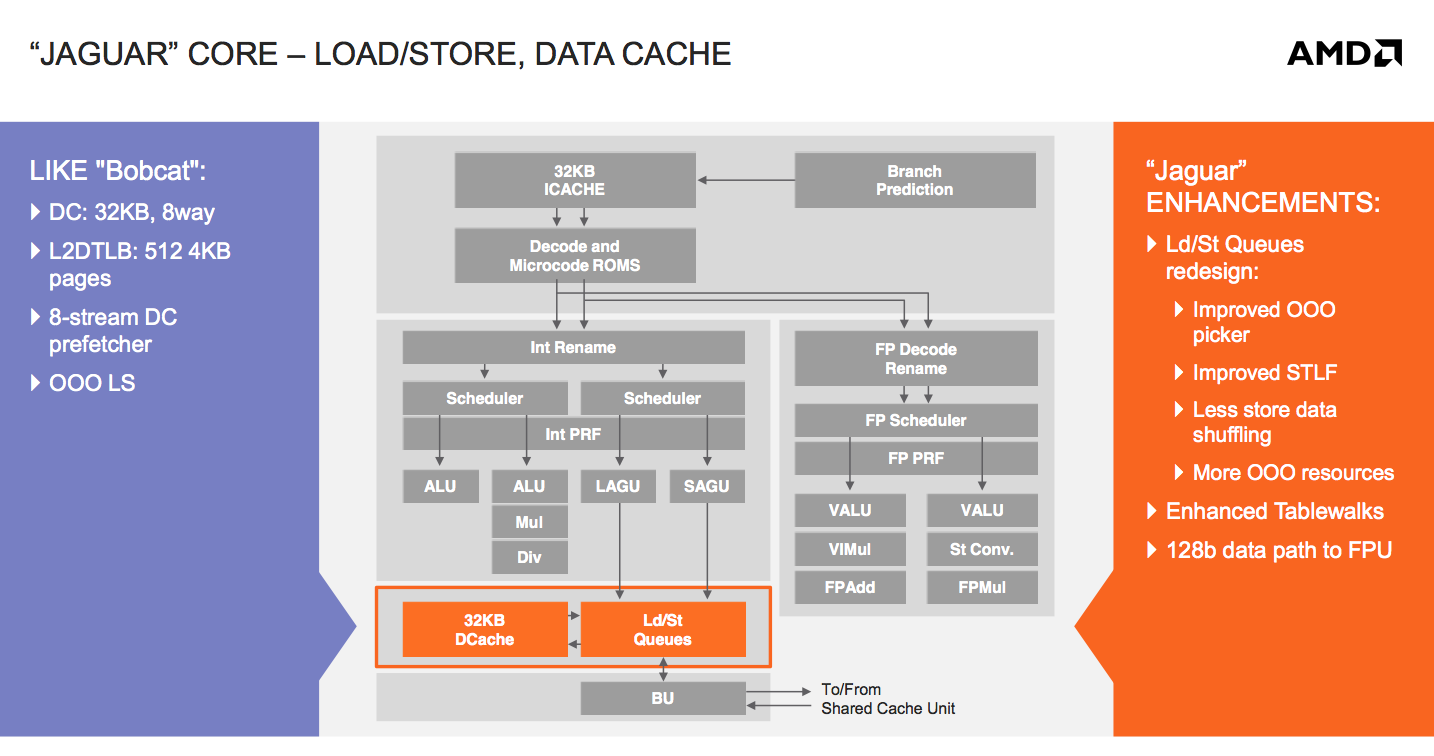
The out-of-order load/store unit in Bobcat was the first one AMD had ever done (Bobcat beat Bulldozer to market, so it gets the claim to fame there). As such there was a good amount of room for improvement, which AMD capitalized on in Jaguar. The second gen OoO load/store unit is responsible for a good amount of the ~15% gains in IPC that AMD promises with Jaguar.









78 Comments
View All Comments
fluxtatic - Thursday, May 23, 2013 - link
Whoa - I think this is the first useful thing I've learned today. I've been wondering the same thing for a long time. Thanks!Ev1l_Ash - Wednesday, May 28, 2014 - link
Thanks for that quasi!Tuna-Fish - Thursday, May 23, 2013 - link
quasi was more accurate than his name implies, but just to expand on it:The count of custom macros is important because when you switch manufacturing processes, the work you have to re-do on the new process is the macros. Old cpus were "all custom macro", meaning that switching the manufacturing process meant re-doing all the physical design. A cpu that has a very limited amount of custom macros can be manufactured at different fabs without breaking the bank.
lmcd - Thursday, May 23, 2013 - link
Sorry, didn't see your post.lmcd - Thursday, May 23, 2013 - link
To suppliment quasi_accurate (as I understand) these are parts of the chip that need checked on, adjusted and corrected, and/or even replaced depending on the foundry.So, reducing these isn't a priority for Intel, but for AMD who wants portability (ability to use both GloFo and TMSC) it's a priority.
tiquio - Thursday, May 23, 2013 - link
Thanks quasi_accurate, Tuna-Fish and lmcd. Your answers were very clear.If I my understanding is correct, would it be safe to assume that Apple's A6 uses custom macros. Anand mentioned in his article that Apple used a custom layout of ARM to maximize performance. Is this one example of custom macros.
name99 - Friday, May 24, 2013 - link
You can customize a variety of things, from individual transistors (eg fast but leaky vs slow but non-leaky), to circuits, to layout.As I understand it the AMD issue is about customized vs automatic CIRCUITS. The Apple issue is about customized vs automatic LAYOUT (ie placement of items and the wiring connecting them).
Transistors are obviously most fab-specific, so you are really screwed if your design depends on them specifically (eg you can't build your finFET design at a non-finFET fab). Circuit design is still somewhat fab-specific --- you can probably get it to run on a different fab, but at lower frequency and higher power, so it's still not where you want to be. Layout, on the other hand, I don't think is very fab-specific at all (unless you do something like use 13 metal layers and then want to move to a fab than can only handle a maximum of 10 metal layers).
I'd be happy to be corrected on any of this, but I think that's the broad outline of the issues.
iwodo - Thursday, May 23, 2013 - link
Really want this to be in Servers. Storage Servers, Home based NAS, caching / front end servers etc.JohanAnandtech - Thursday, May 23, 2013 - link
agree. With a much downsized graphics core, and higher clocks for the CPU.Alex_Haddock - Thursday, May 23, 2013 - link
We will certainly have Kyoto in Moonshot :-) . http://h30507.www3.hp.com/t5/Hyperscale-Computing-...