Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
The Results that Matter
Before you jump ahead to the charts below, we suggest taking some time to properly interpret the results. First of all, we simulate between 5 to 15 "busy" users on the web server per second. As a user clicks somewhere on the website, this can result in a few requests or tens of requests. For example, accessing the forum on the website results in two simple "GET" requests, while posting a reply results in an avalanche of 56 POSTs and GETs. That is why we report performance in "responses per second". Responses are somewhat similar from the CPU load point of view if you look at a statistically large enough number of them. User actions are so wildly different that in some cases performing two user actions per seconds can require more processing power and network bandwidth than 20 user actions per second.
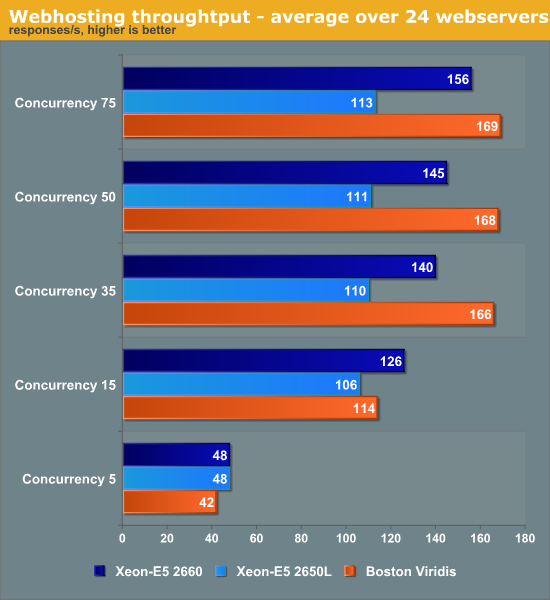
At the low concurrencies, the Intel machine leverages turboboost and its exceptionally high per core performance. At the higher web loads, the total throughput of the 96 (24x quad-core SoCs) ARM Cortex-A9 cores is up to 50% higher than the low power 32 thread/16 core (2x Octal core) Xeons. Even the mighty 2660 cannot beat the herd of ARM SoCs.
While we have lots and lots of experience with x86 servers, we had almost none with ARM based servers, so we met up with the people of Calxeda engineering and got some valuable optimization tips. It turns out that the internal switch fabric can be tuned in various ways. For example, the link speed from one node is by default set to 2.5 gbit/s, which is rather high considering that we are mostly CPU limited and use less than 0.5Gbit/s per node. Setting the link speed of each node to 1Gbit/s should lower power and gives more than enough bandwidth. We also updated to a slightly newer kernel (155) from the Calxeda kernel PPA (Personal Package Archive). This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput.
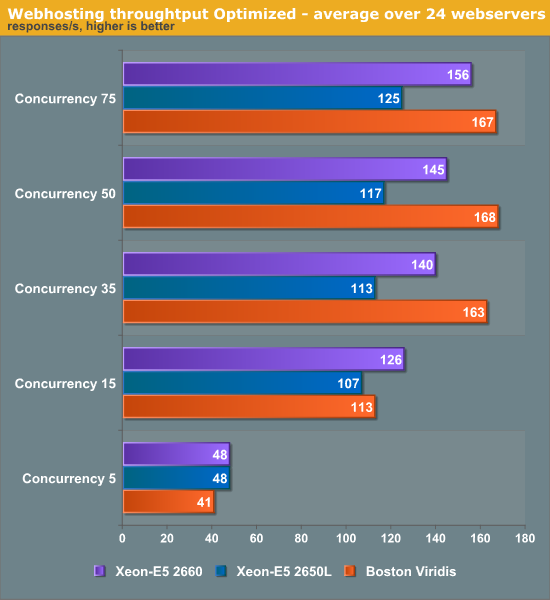
The changes did not give any boost in throughput (in many cases the scores might even be slightly slower), but the changes might lower power use and/or response times. Let's look at that next.
Response Times
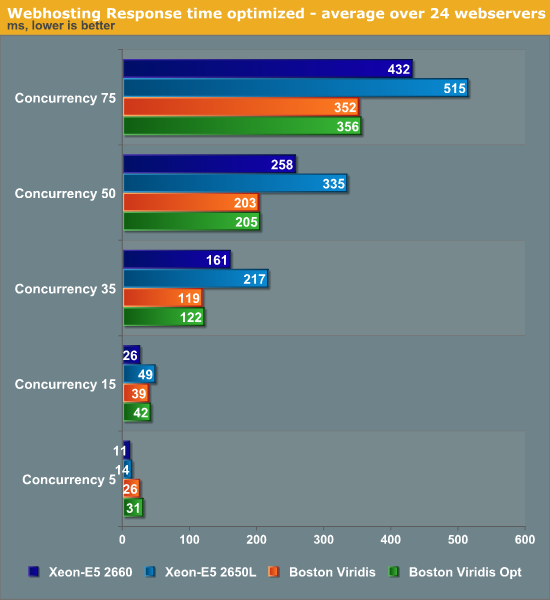
Again, the Intel machine performs better at lower concurrencies, but our ARM server delivers lower response times at high load. Our optimizations have had no effect on response times.








99 Comments
View All Comments
JohanAnandtech - Wednesday, March 13, 2013 - link
Thanks!SunLord - Wednesday, March 13, 2013 - link
Hmm if these didn't cost $20,000 they would make a nice front end for larger websites and forums using less rack space and power. What setup using these would you use for anandtech? Would you guys keep the intel DB server?Gunbuster - Wednesday, March 13, 2013 - link
I just got a Dell R720xd decked out with 384GB and 4.3TB of storage for a hair over that price.JohanAnandtech - Wednesday, March 13, 2013 - link
Intel Xeons are still by far a better choice for relational databases that are very hard to split up (sharding is only a last resort)zachj - Wednesday, March 13, 2013 - link
I'm not sure I agree with the absolutism that seems imlicit in your comment that Xeons are better for relational databases...I think there are cases where that won't be true.Database scale-out doesn't always require sharding...using any of a number of different off-the-shelf capabilities built right into most SQL engines, you can create multiple active replicas of your database. This is generally better-suited to workloads that aren't write-intensive, but both clustering and replication allow for writes. While this may seem like a quick-and-dirty solution that is architecturally "less good" than sharding, hardware is a lot cheaper than paying people to design a sharding solution and the dollars very often drive the conversation. As long as the database size isn't terribly large this can be a very cost-effective way to scale out a database.
I would wager that the Anandtech website database (not the forum database) would probably be well-suited to this type of scale-out. You do waste some money on redundant storage but you more than make up for that cost by not having to pay a development team to implement sharding. If the comments section of the Anandtech website gets stored in the same underlying database, the size constraints and the write activity may appear to be incompatible with this approach, but I would in fact argue that comments don't require relational capabilities of SQL and would be more rightly stored as blobs in Hadoop or Azure Storage Tables. Then the Anandtech database is strictly articles and is both much more compact and almost entirely read-only (except for a few new articles per day).
rwei - Friday, March 15, 2013 - link
To the best of my understanding, replication does well for scaling reads but doesn't do much for writes. I'd still imagine that this would work decently well with AnandTech, where I can't see the volume of writes being that large relative to the volume of reads.Kurge - Wednesday, March 13, 2013 - link
They would make a horrible front end for such websites. Just buy a single Xeon server and don't artificially limit it by using 24 VMs. Just run the app straight on the metal and it will perform massively better.Oldboy1948 - Wednesday, March 13, 2013 - link
Very interesting Johan as your tests often are!Interesting that the memory bw is so much lower than anything from Intel. In fact Iphone 5 looks much better...why? Only Intel has about the same rsults in compress and decompress.
JohanAnandtech - Wednesday, March 13, 2013 - link
Where did you see the stream results on the A6? I might have missed it somewhere. The only ones I could find reported only 1 GB/s in Triad. http://www.anandtech.com/show/6298/analyzing-iphon... The Quad ECX-1000 got 1.8 GB/sPCTC2 - Wednesday, March 13, 2013 - link
Do you know what would be an interesting concept for a future version of these cluster-in-a-box systems? A solution like ScaleMP. ScaleMP is basically a reverse VM. A hypervisor on each server clusters together to run a single OS with an aggregation of all resources (cores, RAM, network, and disk). ScaleMP running on 4x Dual-socket 8-core Xeon systems w/ 32GB RAM results in a usable system with 64-cores and 128GB RAM as if it was running natively on the hardware. This would be an interesting concept to transfer to the ARM space (if a form of hardware virtualization ever is designed). In a box like this, there would be 192 cores and 192GB of RAM available to a single Fedora instance. Cluster 2 of these together and suddenly there's a system with 384 cores and 384GB of RAM in 4U. Just some food for thought.