Calxeda's ARM server tested
by Johan De Gelas on March 12, 2013 7:14 PM EST- Posted in
- IT Computing
- Arm
- Xeon
- Boston
- Calxeda
- server
- Enterprise CPUs
The Results that Matter
Before you jump ahead to the charts below, we suggest taking some time to properly interpret the results. First of all, we simulate between 5 to 15 "busy" users on the web server per second. As a user clicks somewhere on the website, this can result in a few requests or tens of requests. For example, accessing the forum on the website results in two simple "GET" requests, while posting a reply results in an avalanche of 56 POSTs and GETs. That is why we report performance in "responses per second". Responses are somewhat similar from the CPU load point of view if you look at a statistically large enough number of them. User actions are so wildly different that in some cases performing two user actions per seconds can require more processing power and network bandwidth than 20 user actions per second.
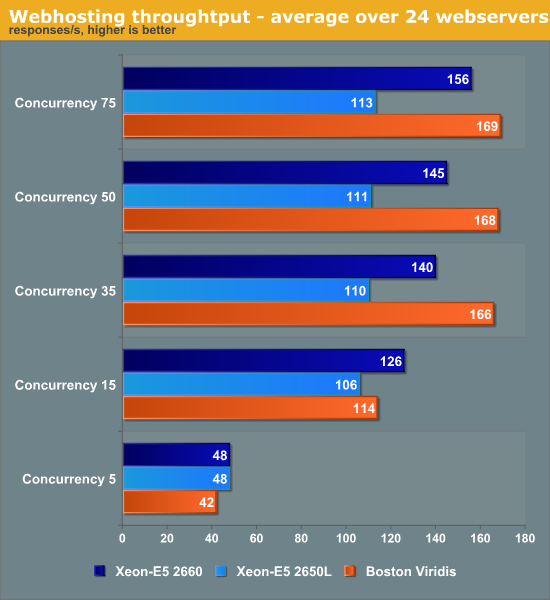
At the low concurrencies, the Intel machine leverages turboboost and its exceptionally high per core performance. At the higher web loads, the total throughput of the 96 (24x quad-core SoCs) ARM Cortex-A9 cores is up to 50% higher than the low power 32 thread/16 core (2x Octal core) Xeons. Even the mighty 2660 cannot beat the herd of ARM SoCs.
While we have lots and lots of experience with x86 servers, we had almost none with ARM based servers, so we met up with the people of Calxeda engineering and got some valuable optimization tips. It turns out that the internal switch fabric can be tuned in various ways. For example, the link speed from one node is by default set to 2.5 gbit/s, which is rather high considering that we are mostly CPU limited and use less than 0.5Gbit/s per node. Setting the link speed of each node to 1Gbit/s should lower power and gives more than enough bandwidth. We also updated to a slightly newer kernel (155) from the Calxeda kernel PPA (Personal Package Archive). This allowed us to make use of Dynamic Voltage and Frequency Scaling (DVFS, P-states) using the CPUfreq tool. First let's see if all these power saving tweaks have reduced the total throughput.
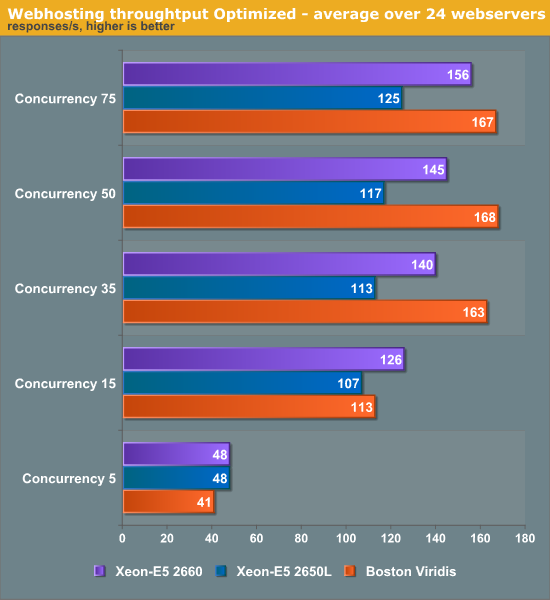
The changes did not give any boost in throughput (in many cases the scores might even be slightly slower), but the changes might lower power use and/or response times. Let's look at that next.
Response Times
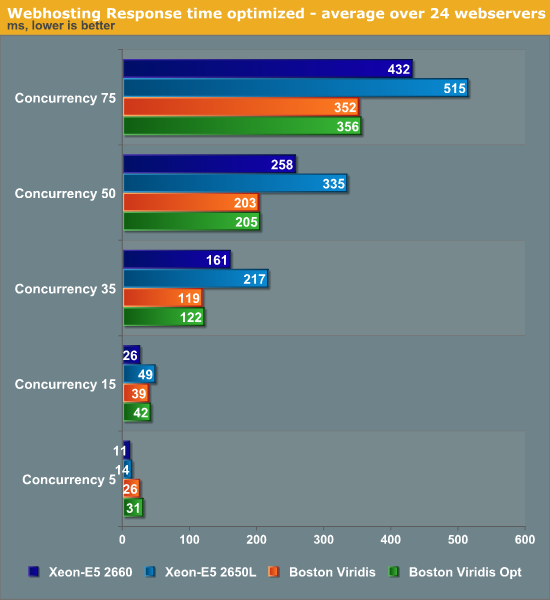
Again, the Intel machine performs better at lower concurrencies, but our ARM server delivers lower response times at high load. Our optimizations have had no effect on response times.








99 Comments
View All Comments
Gigaplex - Tuesday, March 12, 2013 - link
I wouldn't call that a spectacular performance per watt ratio. It's a bit faster than the Xeon under a cherry picked benchmark (much slower under others), and is only marginally lower power. Best case it's an 80% improvement over Sandy Bridge with regards to performance per watt, and Atom wasn't represented. Considering all the hype, I was expecting something a little more... exciting. Ignoring Ivy Bridge improvements, Haswell isn't far off.spronkey - Tuesday, March 12, 2013 - link
Yeah... I agree. It also only seems to really come into its own in high concurrency. The Xeons idle quite similarly in terms of power - what happens if you compare it to more Xeon cores? It seems like on a per core basis, Intel still has the advantage on both fronts?spronkey - Tuesday, March 12, 2013 - link
I would also point out that the A15 has already been compared against Sandy and Ivy cores and come up short in performance per watt; so I'm very interested to see what the next step for these ARM node servers is.JohanAnandtech - Wednesday, March 13, 2013 - link
I warned against the hype in the first sentences. :-) ARM CPUs are still rather weak and not a good match for most applications. However, the fact that we could actually find a case where they do a lot better than the current Xeon systems was surprising to me.wsw1982 - Wednesday, April 3, 2013 - link
No, it should not surprise any people regarding how picky the use case is. I mean, I do think you can find a use case the ARM 11 output perform Xeon. E.g. Serving 1 web request per hour :)LogOver - Tuesday, March 12, 2013 - link
24 servers ran inside 24 VM's on Xeon server, while for ARM server you used the 24 physical server nodes... Hmm... Does not seems to me like apple to apple comparison. Why not to compare, for example, 16 physical nodes on both, xeon and arm servers?haplo602 - Wednesday, March 13, 2013 - link
And how do you slice the Xeon server into 16 physical nodes ? It does not support any kind of HW partitioning that I am aware of. On the other hand the Calxeda machine is a cluster by design. If you try 16 Xeon nodes you'll go through the roof with power.Colin1497 - Wednesday, March 13, 2013 - link
I think the question is this:Was 24 VM's optimal for the Xeon? Since we're visualizing the Xeon, why 24? Just because you had 24 ARM nodes? Would the Xeon done better with 4VM's? Or 16? Or 1000? 24 seems arbitrary.
JohanAnandtech - Wednesday, March 13, 2013 - link
We tested with 16 as I briefly mentioned in the conclusion. The 2650L did 170 responses/s per VM, or about 40% better. Total Throughput = 2.7k/s, while with 24, 2.9 K/s. THe flexibility that the Xeon has to reduce the number of VMs if higher throughput is necessary is definitely an advantage, but the performance numbers are not that different with different VM configs.Kurge - Wednesday, March 13, 2013 - link
How about with 0 VM's? Just run it on the metal.