The ARM vs x86 Wars Have Begun: In-Depth Power Analysis of Atom, Krait & Cortex A15
by Anand Lal Shimpi on January 4, 2013 7:32 AM EST- Posted in
- Tablets
- Intel
- Samsung
- Arm
- Cortex A15
- Smartphones
- Mobile
- SoCs
Modifying a Krait Platform: More Complicated
Modifying the Dell XPS 10 is a little more difficult than Acer's W510 and Surface RT. In both of those products there was only a single inductor in the path from the battery to the CPU block of the SoC. The XPS 10 uses a dual-core Qualcomm solution however. Ever since Qualcomm started doing multi-core designs it has opted to use independent frequency and voltage planes for each core. While all of the A9s in Tegra 3 and both of the Atom cores used in the Z2760 run at the same frequency/voltage, each Krait core in the APQ8060A can run at its own voltage and frequency. As a result, there are two power delivery circuits that are needed to feed the CPU cores. I've highlighted the two inductors Intel lifted in orange:

Each inductor was lifted and wired with a 20 mΩ resistor in series. The voltage drop across the 20 mΩ resistor was measured and used to calculate CPU core power consumption in real time. Unless otherwise stated, the graphs here represent the total power drawn by both CPU cores.
Unfortunately, that's not all that's necessary to accurately measure Qualcomm CPU power. If you remember back to our original Krait architecture article you'll know that Qualcomm puts its L2 cache on a separate voltage and frequency plane. While the CPU cores in this case can run at up to 1.5GHz, the L2 cache tops out at 1.3GHz. I remembered this little fact late in the testing process, and we haven't yet found the power delivery circuit responsible for Krait's L2 cache. As a result, the CPU specific numbers for Qualcomm exclude any power consumed by the L2 cache. The total platform power numbers do include it however as they are measured at the battery.
The larger inductor in yellow feeds the GPU and it's instrumented using another 20 mΩ resistor.
Visualizing Krait's Multiple Power/Frequency Domains
Qualcomm remains adament about its asynchronous clocking with multiple voltage planes. The graph below shows power draw broken down by each core while running SunSpider:
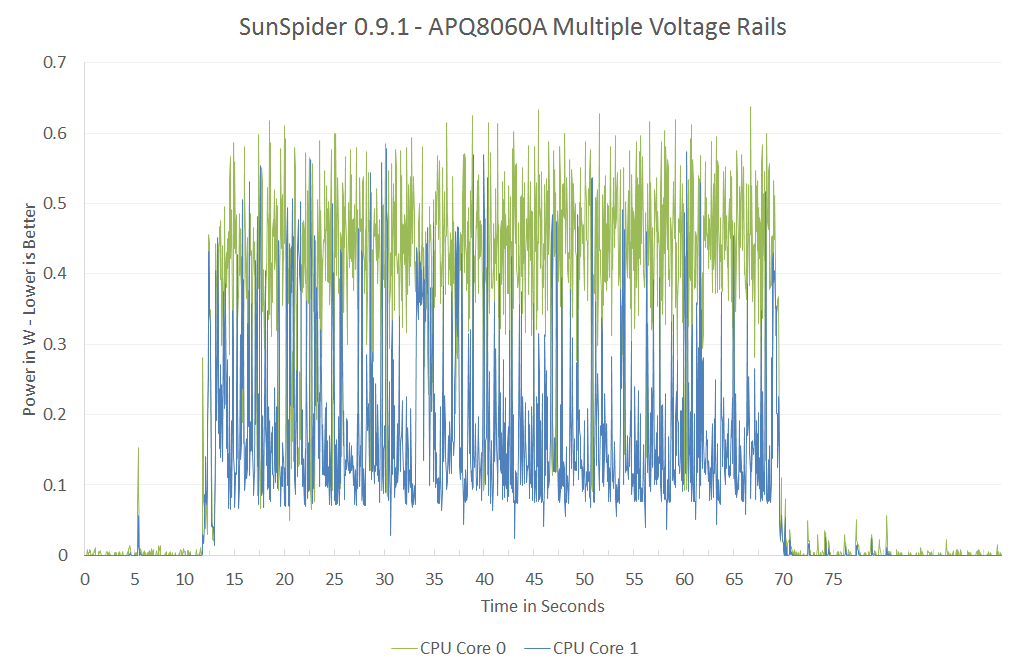
SunSpider is a great benchmark to showcase exactly why Qualcomm has each core running on its own power/frequency plane. For a mixed workload like this, the second core isn't totally idle/power gated but it isn't exactly super active either. If both cores were tied to the same voltage/frequency, the second core would have higher leakage current than in this case. The counter argument would be that if you ran the second core at its max frequency as well it would be able to complete its task quicker and go to sleep, drawing little to no power. The second approach would require a very fast microcontroller to switch between v/f modes and it's unclear which of the two would offer better power savings. It's just nice to be able to visualize exactly why Qualcomm does what it does here.
On the other end of the spectrum however is a benchmark like Kraken, where both cores are fairly active and the workload is balanced across both cores:
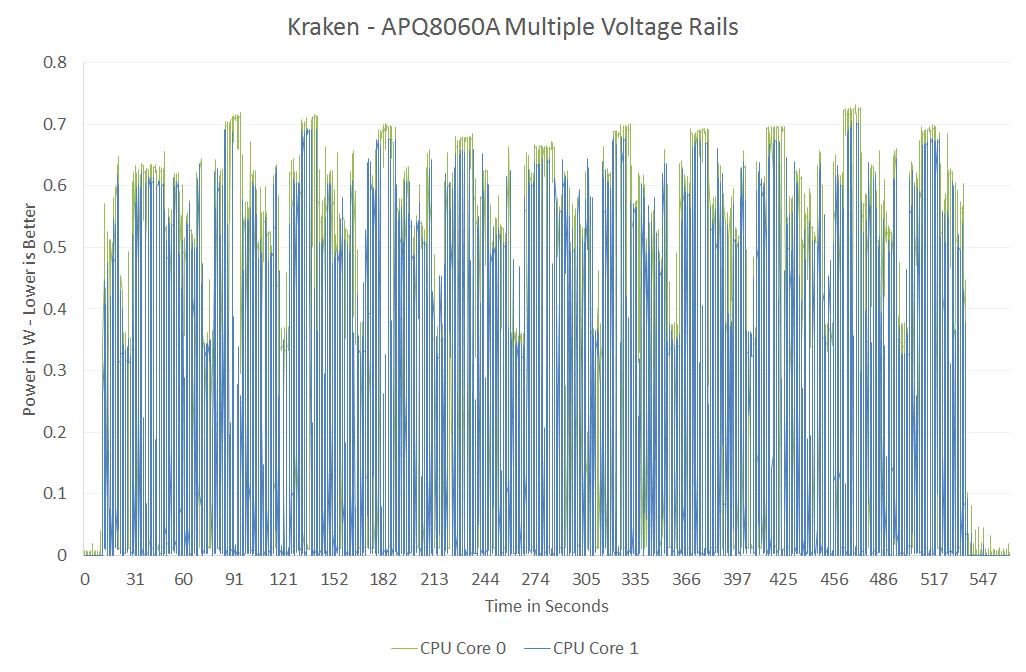
Here there's no real benefit to having two independent voltage/frequency planes, both cores would be served fine by running at the same voltage and frequency. Qualcomm would argue that the Kraken case is rare (single threaded performance still dominates most user experience), and the power savings in situations like SunSpider are what make asynchronous clocking worth it. This is a much bigger philosophical debate that would require far more than a couple of graphs to support and it's not one that I want to get into here. I suspect that given its current power management architecture, Qualcomm likely picked the best solution possible for delivering the best possible power consumption. It's more effort to manage multiple power/frequency domains, effort that I doubt Qualcomm would put in without seeing some benefit over the alternative. That being said, what works best for a Qualcomm SoC isn't necessarily what's best for a different architecture.








140 Comments
View All Comments
A5 - Friday, January 4, 2013 - link
Even if you just look at the Sunspider (which draws nothing on the screen) power draw, it's pretty clear that the A15 draws more power. There have been a ton of OEMs complaining about A15's power draw, too.madmilk - Friday, January 4, 2013 - link
Since when did screen resolution matter for CPU power consumption on CPU benchmarks? Platform power might change, yes, but this doesn't invalidate many facts like Cortex-A15 using twice as much power on average compared to Krait, Atom or Cortex-A9.Wolfpup - Friday, January 4, 2013 - link
Good lord. Do you have some evidence for any of this? If neither Windows nor Android is the "right platform" for ARM, then...are you waiting for Blackberry benchmarks? That's a whole lot of spin you're doing, presumably to fit the data to your preconceived "ARM IS BETTER!" faith.Veteranv2 - Friday, January 4, 2013 - link
Hahaha, the Nexus 10 has almost 4 times the pixels of the Atom.And the conclusion is it draws more power in benchmarks? Of course, those pixels aren't going to fill itself. Way to make conclusion.
How big was that Intel PR cheque?
iwod - Saturday, January 5, 2013 - link
While i wouldn't say it was a Intel PR, I think they should definitely have left the system level power usage out of the questions. There is no point telling me that a 100" Screen with ARM is using X amount of power compared to 1" Screen with Haswell.It is confusing.
But they did include CPU and GPU benchmarks. So saying it is Intel PR is just trolling.
AlB80 - Friday, January 4, 2013 - link
Architectures with variable length of instruction are doomed. Actually there is only one remains. x86.Intel made the step into a happy past when CISC has an advantage over RISC, when superscalarity was just a theory.
Cortex A57 is coming. ARM cores will easily outperform Atom by effective instruction rate with minimum overhead.
Wolfpup - Friday, January 4, 2013 - link
How is x86 doomed when it has an absolute stranglehold on real PCs, and is now competitive on ultramobile platforms?The only disadvantage it holds is the need for a larger decoder on the front end, which has been proportionally shrinking since 1995.
djgandy - Friday, January 4, 2013 - link
plus effing one!I think some people heard their uni lecturers say something once in 1999 and just keep repeating it as if it is still true!
AlB80 - Friday, January 4, 2013 - link
Shrinking decoder... nice myth. Of course complicated scheduler and ALU dozen impact on performance, but do not forget how decoded instruction queues are filled. Decoder is only one real difference.1. There is fundamental limits how many variable instructions can be decoded per clock. CISC has an instruction cross-interference at the decoder stage. One logical block should determine a total length of decoded instructions.
2. There is a trick when CISC decoder is disintegrated into 2-3 parts with dedicated inputs, so its looks like a few independent decoders, but each part can not decode any instruction.
Now compare it with RISC.
And as I said, what happens when Cortex can decode 4,5,6,7,8 instructions?
Kogies - Friday, January 4, 2013 - link
Don't be so quick to prophesy the death of a' that. What happens when a Cortex decodes 8 instructions... I don't know, it uses 8W?Also, didn't Apple choose CISC (Intel) chips over RISC (PowerPC)? Interestingly, I believe Apple made the switch to Intel because the PowerPC chips had too high a power premium for mobile computers.