Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
Gigabyte GA-7PESH1 Software
Typically when a system integrator buys a server motherboard from Gigabyte, a full retail package comes with it including manuals, utility CDs and SATA cables. Gigabyte have told me that this will be improved in the future, with SAS cables, header accessories and GPU bridges for CF/SLI. But due to the nature of my review sample, there was no retail package as such. When I received a sample from Gigabyte, there was no retail box with extras, nor were there driver CDs or a user guide and manual. Good job then that all these can be found on the Gigabyte website under the download section for the GA-7PESH1. In my case, this involves downloading the Intel .inf files, the ASPEED 2300 drivers, and the Intel LAN drivers. Also available on the website are the LSI SAS RAID drivers, and the SATA RAID driver.
When it comes to software available to download, the river has run dry. There is literally not one piece of software available to the user – nothing relating to monitoring, or fan controls or the like. The only thing that approaches a software tool is the Advocent Server Management Interface, which is accessed via the browser of another computer connected to the same network when the system has the third server management NIC connection activated.
When the system is connected to the power supply, and the power supply is switched on, the motherboard takes around 30 seconds to prepare itself before the power button on the board itself can be pushed. There is a green light physically on the board that turns from a solid light to a flashing light when this button can be pushed - the board then takes another 60 seconds or so to POST. During this intermediate state when the light is flashing, the server management software can be accessed through the web interface.
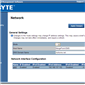
The default username and password are admin and password for this interface, and when logged in we get a series of options relating to the management of the motherboard:
The interface implements a level of security in accessing the management software, as well as keeping track of valid user accounts, web server settings, and active interface sessions.


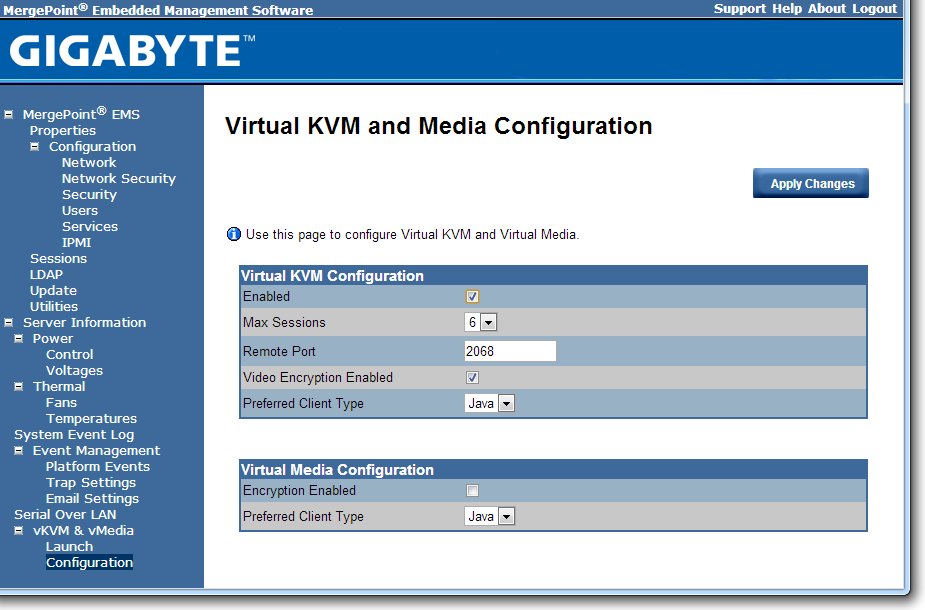
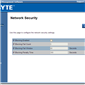
The software also provides options to update the firmware, and to offer full control as to the on/off state of the motherboard with access to all voltages, fan speeds and temperatures the software has access to.

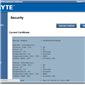
The system log helps identify when sensors are tripped (such as temperature and fans) as well as failed boots and software events.
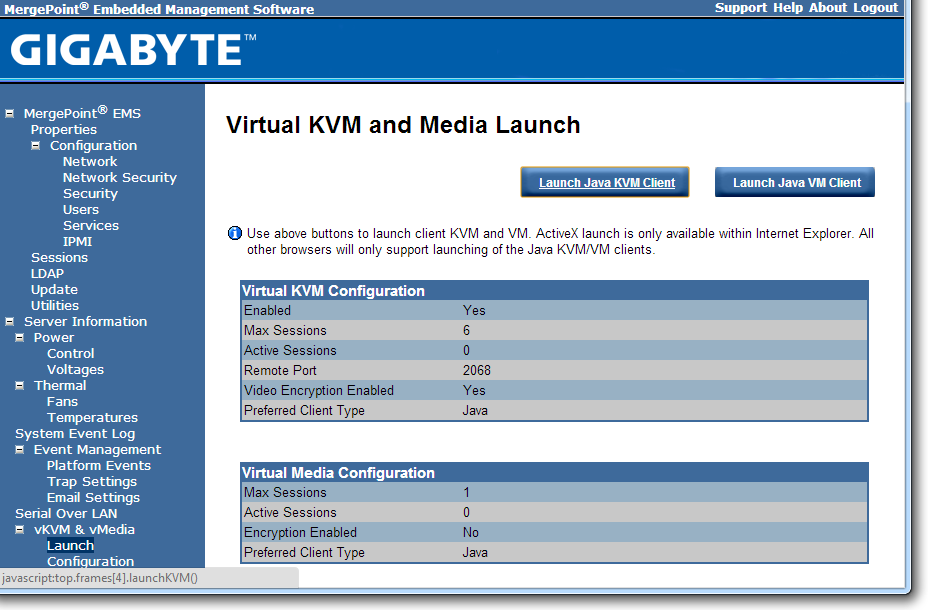
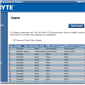
Both Java KVM and Have VM environments are supported, with options relating to these in the corresponding menus.
It should also be noted that during testing, we found the system to be unforgiving when changing discrete GPUs. If an OS was installed while attached to a GTX580 and NVIDIA drivers were installed, the system would not boot if the GTX580 was removed and a HD7970 was put in its place. The same thing happens if the OS is installed under the HD7970 and the AMD drivers installed.








64 Comments
View All Comments
toyotabedzrock - Saturday, January 5, 2013 - link
There is a large number of very smart people on Google+. You really should come join us.JlHADJOE - Tuesday, January 8, 2013 - link
Of course there are lots of smart people on G+! You're all google employees right? =PActivate: AMD - Saturday, January 5, 2013 - link
As a fellow chemist, I must say that you have to be some kind of nut to want to do computational/physical chemistry. If you need me, I'll be at the bench!Good article too!
engrpiman - Saturday, January 5, 2013 - link
I didn't read the article in full but what I did read was top notch. I found your simulations and mathematics very interesting. I took a Physics class which was focused in writing code to run mathematical simulations . Using the given java lib. I wrote my own code to calculate PI. When I returned from the gym the program had calculated 3.1 . I then re-wrote the program from scratch and ditched the built in libs. and reran. I had 20 decimals in 30 sec it was an epic improvement.All in all I think your article could be very useful to me.
Thanks for writing.
SodaAnt - Saturday, January 5, 2013 - link
THIS is why I read Anandtech. I'll admit that I wasn't quite in the mood to read all the equations (I'll have to do that later), but really, these kind of reviews make my day.Cardio - Saturday, January 5, 2013 - link
Wonderful review...as always. ThanksHakon - Saturday, January 5, 2013 - link
Hi Ian. Thanks for the nice article. I have one suggestion regarding the explicit finite difference code:You could try to reorder the loops such that the memory access is more cache friendly. Right now 'pos' is incremented by NX (or even NX*NY in 3D) which will generate a lot cache misses for large grids. If you switch the x and the y loop (in the 2D case) this can be avoided.
IanCutress - Saturday, January 5, 2013 - link
Either way I order the loops, each point has to read one up, one down, one left and one right. My current code tries to keep three as consecutive reads and jump once, keeping the old jump in local memory. If I adjusted the loops, I could keep the one dimension in local memory, but I'd have to jump outside twice (both likely cache misses) to get the other data. I couldn't cache those two values as I never use them again in the loop iteration.When I did this code on the GPU, one method was to load an XY block into memory and iterate in the Z-dimension, meaning that each thread per loop iteration only loaded one element, with a few of them loading another for the halo, but all cache aligned.
I hope that makes sense :)
Ian
Hakon - Saturday, January 5, 2013 - link
Yes, but when you access the array 'cA' at 'pos' the CPU will fetch the entire cache line (64 byte in case of your machine, i.e. 16 floats) of the corresponding memory address into the CPU cache. That means that subsequent accesses to say 'pos + 1', 'pos + 2' and so on will be served by the cache. Accessing an array in such a sequential manner is therefore fast.However, when you access an array in a nasty way, e.g. 'NX + x' -> '2*NX + x', -> '3*NX + x', then each such access implies a trip to main memory if NX happens to be large.
That you need to move up / down and sideways in memory does not matter. When you write down the accesses of the code with the reordered loops you will notice that they just access three "lines" in memory in a cache friendly way.
Not reusing the old values of the last iteration should not affect performance in a measurable way. Even if the compiler fails to see this optimization, the accesses will be served by the L1 cache.
Btw, did you allocate the array having NUMA in mind, i.e. did you initialize your memory in an OpenMP loop with the same access pattern as used in the algorithms? I am a bit surprised by the bad performance of your dual Xeon system.
IanCutress - Saturday, January 5, 2013 - link
Memory was allocated via the new command as it is 1D. When using a 2D array the program was much slower. I was unaware you could allocate memory in an OpenMP way, which thinking about it could make the 2D array quicker. I also tried writing the code using the PPL and lambdas, but that was also slower than a simple OpenMP loop.I'm coming at these algorithms from the point of view of a non-CompSci interested in hardware, and the others in the research group were chemists content to write single threaded code on multi-core machines. Transferring the OpenMP variations of that code from a 1P to a 2P, as the results show, give variable results depending on the algorithm.
There are always ways to improve the efficiency of the code (and many ways to make it unreadable), but for a large part moving to the 2P system all depends on how your code performs. Please understand that my examples being within my limits of knowledge and representative of the research I did :) I know that SSE2/SSE4/AVX would probably help, but I have never looked into those. More often than not, these environments are all about research throughput, so rather than spend a few week to improve efficiency by 10% (or less), they'd rather spend that money getting a faster system which theoretically increases the same code throughput 100%.
I'll have a look at switching the loops if I write an article similar to this in the future :)
Ian