Gigabyte GA-7PESH1 Review: A Dual Processor Motherboard through a Scientist’s Eyes
by Ian Cutress on January 5, 2013 10:00 AM EST- Posted in
- Motherboards
- Gigabyte
- C602
USB Speed
For this benchmark, we run CrystalDiskMark to determine the ideal sequential read and write speeds for the USB port using our 240 GB OCZ Vertex3 SSD with a SATA 6 Gbps to USB 3.0 converter. Then we transfer a set size of files from the SSD to the USB drive using DiskBench, which monitors the time taken to transfer. The files transferred are a 1.52 GB set of 2867 files across 320 folders – 95% of these files are small typical website files, and the rest (90% of the size) are the videos used in the Sorenson Squeeze test.
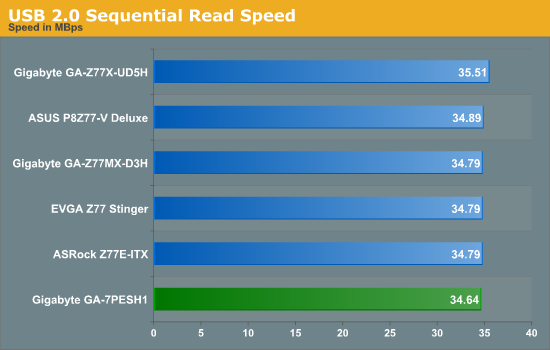
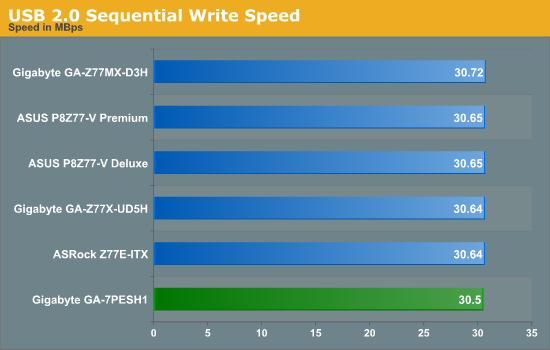

USB speed is dictated by the chipset and the BIOS implementation, and the GA-7PESH1 performance is comparable to our Z77/X79 testing.
DPC Latency
Deferred Procedure Call latency is a way in which Windows handles interrupt servicing. In order to wait for a processor to acknowledge the request, the system will queue all interrupt requests by priority. Critical interrupts will be handled as soon as possible, whereas lesser priority requests, such as audio, will be further down the line. So if the audio device requires data, it will have to wait until the request is processed before the buffer is filled. If the device drivers of higher priority components in a system are poorly implemented, this can cause delays in request scheduling and process time, resulting in an empty audio buffer – this leads to characteristic audible pauses, pops and clicks. Having a bigger buffer and correctly implemented system drivers obviously helps in this regard. The DPC latency checker measures how much time is processing DPCs from driver invocation – the lower the value will result in better audio transfer at smaller buffer sizes. Results are measured in microseconds and taken as the peak latency while cycling through a series of short HD videos - under 500 microseconds usually gets the green light, but the lower the better.

As a workstation motherboard, having a low DPC latency would be critical for recording and analyzing time sensitive information. Scoring 110 microseconds at its peak latency is great for this motherboard.








64 Comments
View All Comments
toyotabedzrock - Saturday, January 5, 2013 - link
There is a large number of very smart people on Google+. You really should come join us.JlHADJOE - Tuesday, January 8, 2013 - link
Of course there are lots of smart people on G+! You're all google employees right? =PActivate: AMD - Saturday, January 5, 2013 - link
As a fellow chemist, I must say that you have to be some kind of nut to want to do computational/physical chemistry. If you need me, I'll be at the bench!Good article too!
engrpiman - Saturday, January 5, 2013 - link
I didn't read the article in full but what I did read was top notch. I found your simulations and mathematics very interesting. I took a Physics class which was focused in writing code to run mathematical simulations . Using the given java lib. I wrote my own code to calculate PI. When I returned from the gym the program had calculated 3.1 . I then re-wrote the program from scratch and ditched the built in libs. and reran. I had 20 decimals in 30 sec it was an epic improvement.All in all I think your article could be very useful to me.
Thanks for writing.
SodaAnt - Saturday, January 5, 2013 - link
THIS is why I read Anandtech. I'll admit that I wasn't quite in the mood to read all the equations (I'll have to do that later), but really, these kind of reviews make my day.Cardio - Saturday, January 5, 2013 - link
Wonderful review...as always. ThanksHakon - Saturday, January 5, 2013 - link
Hi Ian. Thanks for the nice article. I have one suggestion regarding the explicit finite difference code:You could try to reorder the loops such that the memory access is more cache friendly. Right now 'pos' is incremented by NX (or even NX*NY in 3D) which will generate a lot cache misses for large grids. If you switch the x and the y loop (in the 2D case) this can be avoided.
IanCutress - Saturday, January 5, 2013 - link
Either way I order the loops, each point has to read one up, one down, one left and one right. My current code tries to keep three as consecutive reads and jump once, keeping the old jump in local memory. If I adjusted the loops, I could keep the one dimension in local memory, but I'd have to jump outside twice (both likely cache misses) to get the other data. I couldn't cache those two values as I never use them again in the loop iteration.When I did this code on the GPU, one method was to load an XY block into memory and iterate in the Z-dimension, meaning that each thread per loop iteration only loaded one element, with a few of them loading another for the halo, but all cache aligned.
I hope that makes sense :)
Ian
Hakon - Saturday, January 5, 2013 - link
Yes, but when you access the array 'cA' at 'pos' the CPU will fetch the entire cache line (64 byte in case of your machine, i.e. 16 floats) of the corresponding memory address into the CPU cache. That means that subsequent accesses to say 'pos + 1', 'pos + 2' and so on will be served by the cache. Accessing an array in such a sequential manner is therefore fast.However, when you access an array in a nasty way, e.g. 'NX + x' -> '2*NX + x', -> '3*NX + x', then each such access implies a trip to main memory if NX happens to be large.
That you need to move up / down and sideways in memory does not matter. When you write down the accesses of the code with the reordered loops you will notice that they just access three "lines" in memory in a cache friendly way.
Not reusing the old values of the last iteration should not affect performance in a measurable way. Even if the compiler fails to see this optimization, the accesses will be served by the L1 cache.
Btw, did you allocate the array having NUMA in mind, i.e. did you initialize your memory in an OpenMP loop with the same access pattern as used in the algorithms? I am a bit surprised by the bad performance of your dual Xeon system.
IanCutress - Saturday, January 5, 2013 - link
Memory was allocated via the new command as it is 1D. When using a 2D array the program was much slower. I was unaware you could allocate memory in an OpenMP way, which thinking about it could make the 2D array quicker. I also tried writing the code using the PPL and lambdas, but that was also slower than a simple OpenMP loop.I'm coming at these algorithms from the point of view of a non-CompSci interested in hardware, and the others in the research group were chemists content to write single threaded code on multi-core machines. Transferring the OpenMP variations of that code from a 1P to a 2P, as the results show, give variable results depending on the algorithm.
There are always ways to improve the efficiency of the code (and many ways to make it unreadable), but for a large part moving to the 2P system all depends on how your code performs. Please understand that my examples being within my limits of knowledge and representative of the research I did :) I know that SSE2/SSE4/AVX would probably help, but I have never looked into those. More often than not, these environments are all about research throughput, so rather than spend a few week to improve efficiency by 10% (or less), they'd rather spend that money getting a faster system which theoretically increases the same code throughput 100%.
I'll have a look at switching the loops if I write an article similar to this in the future :)
Ian