The Xeon Phi at work at TACC
by Johan De Gelas on November 14, 2012 1:44 PM EST- Posted in
- Cloud Computing
- CPUs
- IT Computing
- Intel
- Larrabee
- Xeon
- Xeon Phi
The Xeon Phi card comes on a PCIe card, much like a GPU. Given the architecture's origins as a GPU, the form factor should't come as a surprise. Like modern HPC GPUs however, the Xeon Phi card has no display output - its role is strictly for compute.
The Xeon Phi acts as a multi-core system on chip running its own operating system, a modified Linux kernel. Each Xeon Phi card has its own IP address however, the Xeon Phi can not operate on its own. A "normal" Xeon will be be the host CPU, the Xeon Phi card is a coprocessor, similar to the way your CPU and GPU work together.
Below you can see the SKUs that Intel will offer.
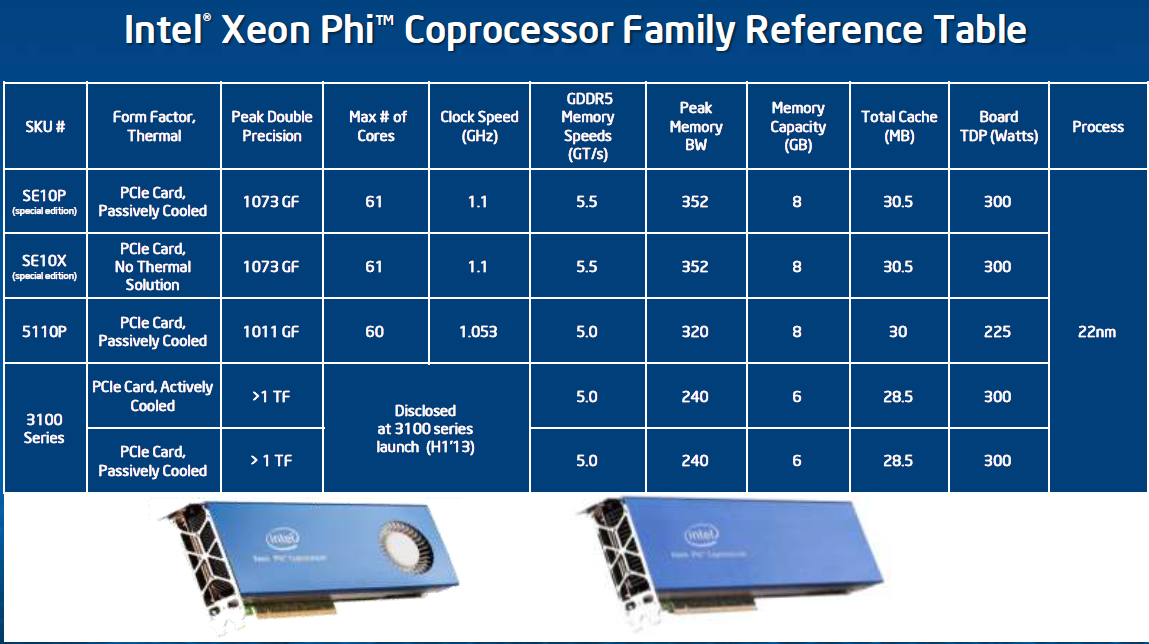
The Xeon Phi inside the Stampede are special edition Xeon Phis.These special editions get 61 cores and run at a slightly higher clockspeed (1.1 GHz).
The commercially avialable 5110P has one core and 50 MHz less than the special edition Phi but comes with 8 GB of ECC memory. The P-suffix indicates that it's passively cooled, relying on the host server for airflow. The 5110P is not cheap at $2699, but it's still more affordable than NVIDIA's Tesla K20 ($3199). The Xeon Phi 5100 series is really intended for more memory bandwidth bound applications thanks to the use of 5GHz GDDR5 and a fully populated 512-bit memory interface.
For compute bound applications however, Intel will offer the Xeon Phi 3100 series in the first half of next year for less than $2000. The Xeon Phi 3100 will come with 6GB of GDDR5 (5GHz data rate) and only a 384-bit memory interface. Core clock should be higher, delivering over 1TFLOP of DP FP performance.
The Xeon Phi cards use a 7GHz PCIe 2.0 interface, as Intel found moving to PCIe 3.0 resulted in slightly higher overhead.








46 Comments
View All Comments
Kevin G - Saturday, November 17, 2012 - link
It is dependent upon the bus encoding. PCI-E 1.0/2.0 use an 8/10 encoding scheme to handle traffic while PCI-E 3.0 uses 128/130 encoding. PCI-E only increases the clock speed of the bus by 66% with the rest of the bandwidth increase stemming from the more efficient encoding schema. Xeon Phi seems to have kept the PCI-E 1.0/2.0 encoding but supports the higher clock rate of PCI-E 3.0. This appears to be nonstandard but the LGA 2011 Xeons appear to support this for additional bandwidth.Any overhead is likely adding full PCI-E 3.0 support in addition to PCI-E 1.0/2.0.
mayankleoboy1 - Thursday, November 15, 2012 - link
Assuming you can buy a single Xeon phi card, can it work in desktop motherboards and processors ?Can it work with AMD processors ? Can it work in tandem with Nvidia and ATI GPU's ?
Joschka77 - Thursday, November 15, 2012 - link
i think the answers would be: Yes, Yes, no! ;-)Jaybus - Thursday, November 15, 2012 - link
No, it is yes, yes, and yes. The Stampede also uses 128 NVIDIA Tesla K20 GPUs, as stated in the article.Kevin G - Saturday, November 17, 2012 - link
That's with in the cluster, not necessarily in the same host system. I strongly suspect that the visual nodes featuring K20 GPU's are isolated from the Xeon Phi nodes.maximumGPU - Thursday, November 15, 2012 - link
can't deny that openMP code that automatically runs faster on the phi would represent a great solution for those looking for the speed up without the cost and time of modifying code for gpus. There certainly is a market to cater for with these cards.creed3020 - Thursday, November 15, 2012 - link
Johan,The numbers you describe as to configuration of the units doesn't add up.
Eight of the compute sleds plus two PSU sleds cannot fit into a 4U unit. Judging by the photo it appears that in this vertical configuration of nodes it goes something like this: {Compute, Compute, PSU, PSU, Compute, Compute } 4U. It appears this leads to a total of 5 chassis per cluster within the rack.
This is then compounded with two distinct clusters per rack with their own Infiniband switch + regular Ethernet switch. This makes for a total of 10 C8000 chassis per rack.
This makes sense when considering a 48U rack. 22U per cluster x 2 clusters per rack = 44U with a few spare slots at the top and middle. I could two at top and one in the middle.
llninja1 - Thursday, November 15, 2012 - link
I think the author got some Dell facts mixed up. Looking at Dell.com you can fit 8 compute sleds in, but those compute sleds are half width and don't contain the necessary double wide PCIe slots to accommodate a Xeon Phi card. So in a single 4U unit, you are correct it can only hold 4 compute sleds and two power units as depicted in the Stampede picture.creed3020 - Friday, November 16, 2012 - link
Thanks for the explanation. I didn't go over to the Dell site but it would explain that a slimmer sled is possible if you don't have to stick one these huge 2 slot Xeon Phi cards in.It makes me wonder how big a difference there is in total PFLOPS/rack when configured with the half height sled vs. full height sled with Phi.
mfilipow - Thursday, November 15, 2012 - link
"Eight of those server sleds find a home inside the C8000 4U Chassis, together with two power sleds." did you write - but on the photo I only see 4x computing sleds plus 2x power. Where are the other 4?!