NVIDIA Launches Tesla K20 & K20X: GK110 Arrives At Last
by Ryan Smith on November 12, 2012 9:00 AM ESTEfficiency Through Hyper-Q, Dynamic Parallelism, & More
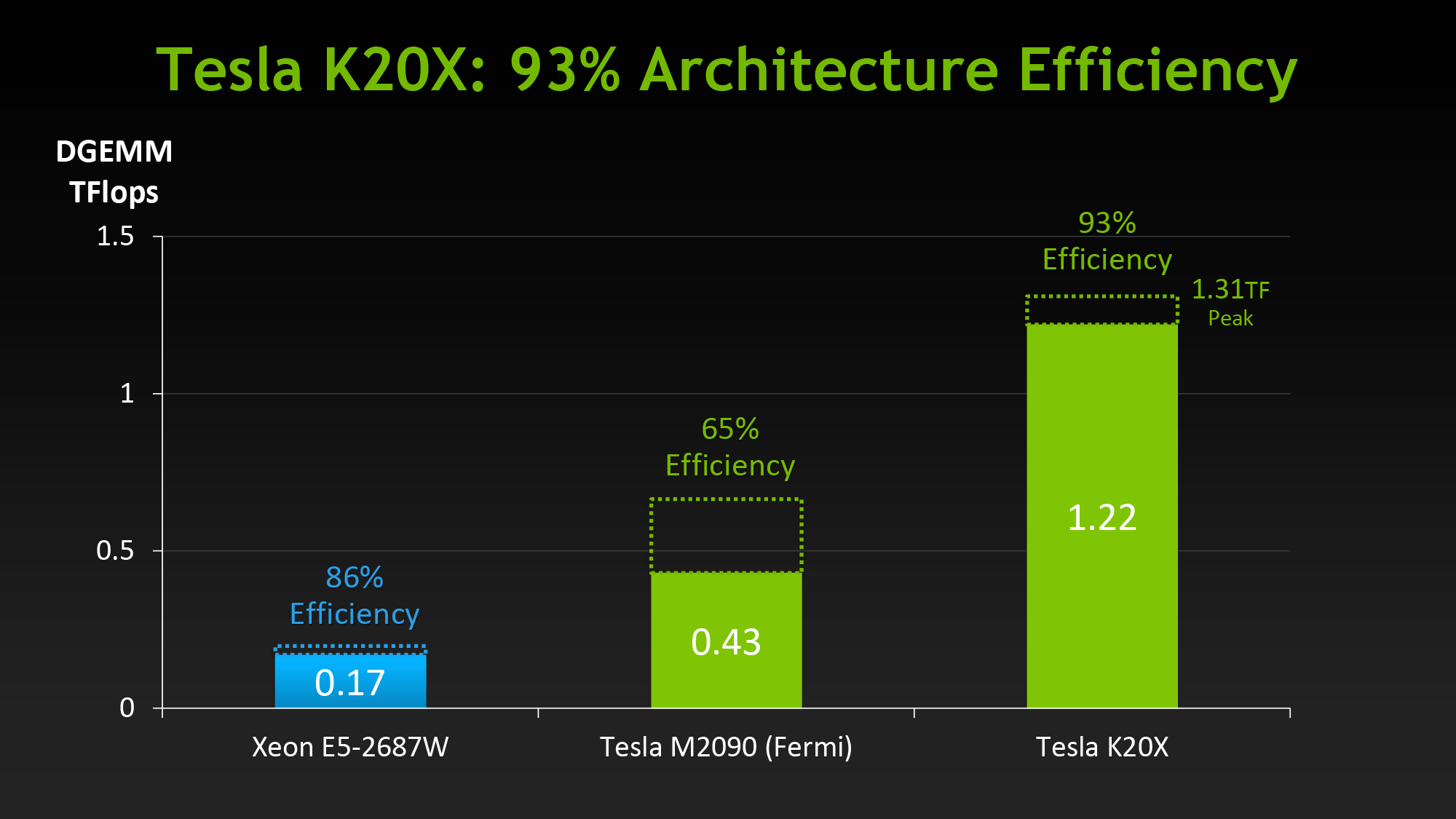
When NVIDIA first announced K20 they stated that their goal was to offer 3x the performance per watt of their Fermi based Tesla solutions. With wattage being held nearly constant from Fermi to Kepler, NVIDIA essentially needed to triple their total performance to reach that number.
However as we’ve already seen from NVIDIA’s hardware specifications, K20 triples their theoretical FP32 performance but not their theoretical FP64 performance, due to the fact that NVIDIA’s FP64 execution rate falls from ½ to 1/3their FP32 rate. Does that mean NVIDIA has given up on tripling their performance? No, but with Kepler the solution isn’t just going to be raw hardware, but the efficient use of existing hardware.
Of everything Kepler and GK110 in particular add to NVIDIA’s compute capabilities, their marquee features, HyperQ and Dynamic Parallelism, are firmly rooted in maximizing their efficiency. Now that we’ve seen what NVIDIA’s hardware can do at a low level, we’ll wrap up our look at K20 and GK110 by looking at how NVIDIA intends to maximize their efficiency and best feed the beast that is GK110.
Hyper-Q
Sometimes the simplest things can be the most powerful things, and this is very much the case for Hyper-Q. Simply put, Hyper-Q expands the number of hardware work queues from 1 on GF100 to 32 on GK110. The significance of this being that having 1 work queue meant that GF100 could be under occupied at times (that is, hardware units were left without work to do) if there wasn’t enough work in that queue to fill every SM or if there were dependency issues, even with parallel kernels in play. By having 32 work queues to select from, GK110 can in many circumstances achieve higher utilization by being able to put different program streams on what would otherwise be an idle SMX.
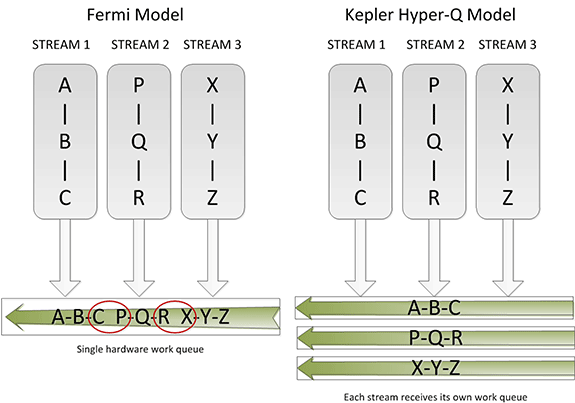
The simplistic nature of Hyper-Q is further reinforced by the fact that it’s designed to easily map to MPI, a common message passing interface frequently used in HPC. As NVIDIA succinctly puts it, legacy MPI-based algorithms that were originally designed for multi-CPU systems and that became bottlenecked by false dependencies now have a solution. By increasing the number of MPI jobs (a very easy modification) it’s possible to utilize Hyper-Q on these algorithms to improve the efficiency all without changing the core algorithm itself. Ultimately this is also one of the ways NVIDIA hopes to improve their HPC market share, as by tweaking their hardware to better map to existing HPC workloads is in this fashion NVIDIA’s hardware will become a much higher performing option.
Dynamic Parallelism
If Hyper-Q was the simple efficiency feature, then NVIDIA’s other marquee feature, Dynamic Parallelism, is the harder and more complex of the features.
Dynamic Parallelism is NVIDIA’s name for the ability for kernels to be able to dispatch other kernels. With Fermi only the CPU could dispatch a new kernel, which incurs a certain amount of overhead by having to communicate back and forth with the CPU. By giving kernels the ability to dispatch their own child kernels, GK110 can both save time by not having to go back to the GPU, and in the process free up the CPU to work on other tasks.

The difficult of course comes from the fact that dynamic parallelism implicitly relies on recursion, to which as the saying goes “to understand recursion, you must first understand recursion”. The use of recursion brings with it many benefits so the usefulness of dynamic parallelism should not be understated, but if nothing else it’s a forward looking feature. Recursion isn’t something that can easily be added to existing algorithms, so taking full advantage of dynamic parallelism will require new algorithms specifically designed around it. (ed: fork bombs are ready-made for this)
Reduced ECC Overhead
Although this isn’t strictly a feature, one final efficiency minded addition to GK110 is the use of a new lower-overhead ECC algorithm. As you may recall, Tesla GPUs implement DRAM ECC in software, allowing ECC to be added without requiring wider DRAM busses to account for the checkbits, and allowing for ECC to be enabled and disabled as necessary. The tradeoff for this is that enabling ECC consumes some memory bandwidth, reducing effective memory bandwidth to kernels running on the GPU. GK110 doesn’t significantly change this model, but what it does do is reduce the amount of ECC checkbit traffic that results from ECC being turned on. The amount of memory bandwidth saved is workload dependent, but NVIDIA’s own tests are showing that the performance hit from enabling ECC has been reduced by 66% for their internal test suite.
Putting It All Together: The Programmer
Bringing things to a close, while we were on the subject of efficiency the issue of coder efficiency came up in our discussions with NVIDIA. GK110 is in many ways a direct continuation of Fermi, but at the same time it brings about a significant number of changes. Given the fact that HPC is so performance-centric and consequently often so heavily tuned for specific processors (a problem that also spans to consumer GPGPU workloads) we asked NVIDIA about just how well existing programs run on K20.
The short answer is that despite the architectural changes between Fermi and GK110, existing programs run well on K20 and are usually capable of taking advantage of the additional performance offered by the hardware. It’s clear that peak performance on K20 will typically require some rework, particularly to take advantage of features like dynamic parallelism, but otherwise we haven’t been hearing about any notable issues transitioning to K20 thus far.

Meanwhile as part of their marketing plank NVIDIA is also going to be focusing on bringing over additional HPC users by leveraging their support for OpenACC, MPI, and other common HPC libraries and technologies, and showcasing just how easy porting HPC programs to K20 is when using those technologies. Note that these comparisons can be a bit misleading since the core algorithms of most programs are complex yet code dense, but the main idea is not lost. For NVIDIA to continue to grow their HPC market share they will need to covert more HPC users from other systems, which means they need to make it as easy as possible to accommodate their existing code and tools.








73 Comments
View All Comments
kwrzesien - Monday, November 12, 2012 - link
My first First! Okay, now back to work.DigitalFreak - Monday, November 12, 2012 - link
I wouldn't call riding the short-bus work...kwrzesien - Monday, November 12, 2012 - link
Hey, I wouldn't call reading news work either!CeriseCogburn - Thursday, November 29, 2012 - link
Thank you insane amd fanboys, for months on end, you've been screaming that nVidia yields are horrible and they're late to the party, while nVidia itself has said yields are great, especially in the GPU gaming card space.now the big amd fanboy lie is exposed.
" Interestingly NVIDIA tells us that their yields are terrific – a statement backed up in their latest financial statement – so the problem NVIDIA is facing appears to be demand and allocation rather than manufacturing."
(that's in the article above amd fanboys, the one you fainted...after raging... trying to read)
Wow.
I'm so glad this site is so fair, and as we see, as usual, what nVidia has been telling them is considered a lie for a very, very long time, until the proof that it was and is actually the exact truth and has been all along is slammed hard into the obstinate amd fan brain.
So nVidia NEVER had an ongoing yield issue on 600 series..
That's what they said all along, and the liars, knows as amd fanboys, just lied instead, even after they were informed over and over again that nVidia did not buy up a bunch of manufacturing time early.
Thanks amd fanboys, months and months of your idiot lies makes supporting amd that much harder, and now they are truly dying.
Thank you for destroying competition.
mayankleoboy1 - Monday, November 12, 2012 - link
Anand, I am a Nvidia fanboi.But still i was surprised by your AMD S10000 coverage. That merited a page in the _pipeline_ section.
And a product from Nvidia gets a front seat, _3 page_ article ?
Bias, or page hits ?
Ryan Smith - Monday, November 12, 2012 - link
I had more to write about the K20, it's as simple as that. This is the first chance I've had to write in-depth about GK110, whereas S10000 is a dual-chip board using an existing GPU.lx686x - Monday, November 12, 2012 - link
Ohhh the W9000/8000 review that never got a promised part 2? And the S9000 and S7000 that was also thrown in the pipeline?tviceman - Monday, November 12, 2012 - link
Just like the gtx650 that never got it's own review. Get over it.lx686x - Monday, November 12, 2012 - link
It wasn't promised, get over it.The Von Matrices - Tuesday, November 13, 2012 - link
It was promised, but it never was published.http://www.anandtech.com/show/6289/nvidia-launches...
"We’ll be looking at the GTX 650 in the coming week, at which point we should have an answer to that question."