The Intel SSD DC S3700: Intel's 3rd Generation Controller Analyzed
by Anand Lal Shimpi on November 5, 2012 12:01 PM EST- Posted in
- Cloud Computing
- Storage
- IT Computing
- SSDs
- Intel
A Brand New Architecture
To understand how the S3700 is different, we need to revisit how SSDs work. I've done this several times over the years so I'll keep it as succinct as possible here. SSDs are made up of a bunch of NAND packages, each with 1 - 8 NAND die per package, with each die made of multiple planes, blocks and finally pages.
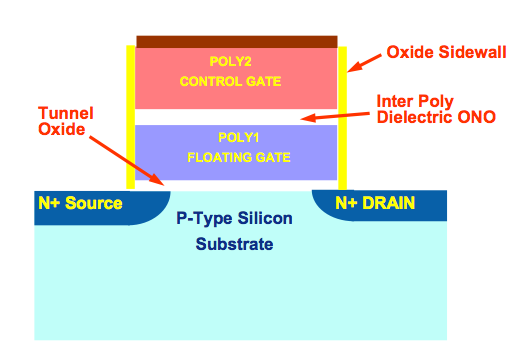
NAND is solid-state, non-volatile memory (data is retained even when power is removed, courtesy of some awesome physics). There are no moving parts, and accesses are very memory-like which delivers great sequential and random IO performance. The downside is NAND has some very strict guidelines dictating how it is written to and erased.
The first thing to know about NAND flash is that you can only write to the same NAND cell a finite number of times. The total amount of charge stored in a NAND cell is counted in dozens of electrons. The tunneling process that places the electrons on the floating gate (thus storing data) weakens the silicon oxide insulation layer that keeps the charge there. Over time, that layer degrades to the point where the cell can no longer store data, and it has to be marked as bad/unusable.
The second principle of dealing with NAND is that you can only write to NAND at the page level. In modern drives that's a granularity of 8KB.
The final piece of the puzzle, and the component that makes all of this a pain to deal with is that you can only erase NAND at the block level, which for Intel's 25nm NAND is 256 pages (2048KB).
Modern SSDs present themselves just like hard drives do, as a linear array of logical block addresses. The OS sends an address and command to the SSD, and the controller translates that address to a physical location in NAND.
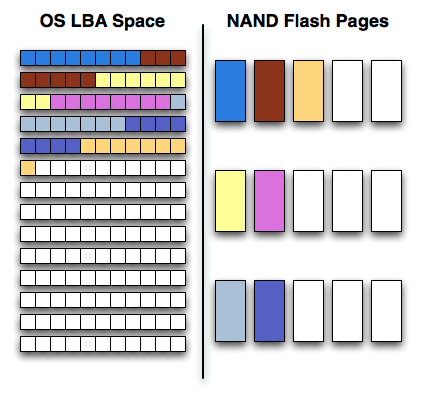
When writing to an SSD, the SSD controller must balance its desire for performance (striping writes across as many parallel NAND die as possible) with the goal of preserving NAND lifespan by writing to all cells evenly (wear leveling).
As writes come in, new pages are allocated from a pool of free blocks. As the process of erasing a NAND cell reduces endurance, a good SSD controller will prefer allocating an empty page for new data over erasing an old block. Eventually the controller will run out of clean/empty pages to write to and will have to recycle an old block filled (sometimes only partially) with invalid data to keep operating. This process can reduce overall performance and increase wear on the NAND.
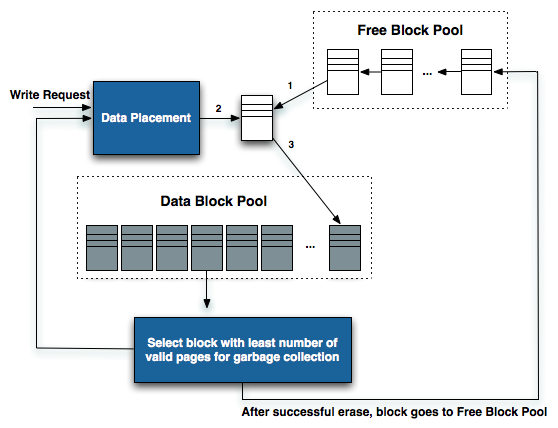
When writing sequential data to an SSD it's easy to optimize for performance. Transfers can be broken up and striped across all available NAND die. Reading the data back is perfectly optimized for high performance as well. It's random IO that causes a problem for performance. Writes to random LBA locations are combined and sent out as burst traffic to look sequential, however the mapping of those LBAs to physical NAND locations can leave the drive in a very fragmented state. With enough random data fragmented on a drive, all write performance will suffer as the controller will no longer be able to quickly allocate large contiguous blocks of free pages across all NAND die.
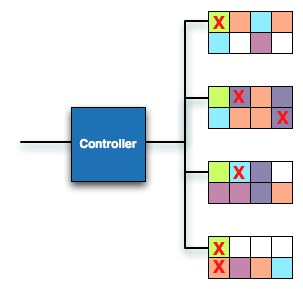
SSD in a fragmented state, white blocks represent free pages, Xes represent invalid data, colored blocks are valid data - more detail here
Modern SSD controllers will attempt to defragment themselves either while the drive is in use, or during periods of idle time (hence the phrase idle garbage collection). Adequate defragmentation is necessary to maintain a drive's performance even after it has been used for a while. The best controllers do a great job of defragmenting themselves as they work, while the worst allow internal fragmentation to get out of hand.
With that recap out of the way, let's talk about how Intel's first and second generation SSD controllers worked.
The Indirection Table
There never was a true Intel X25-M G3, the third generation controller went missing after briefly appearing on Intel roadmaps. Instead we got mild revisions of the X25-M G2's controller with new features enabled through firmware. This old controller was used in the Intel SSD 320 and more recently in the Intel SSD 710.
One notable characteristic of this old controller was that it never required a large external DRAM (16 - 64MB for the early drives). Intel was proud of the fact that it stored no user data in DRAM, which I always assumed kept the size requirements down. It turns out there was another reason.
All controllers have to map logical block addresses to physical locations in NAND. This map is stored on the NAND itself (and wear leveled so it actually moves locations), but it's cached in DRAM for fast access. Intel calls this map its indirection table.
In the old drives, the indirection table was a binary tree. A binary tree is a data structure made up of nodes and branches where each node can have at most two children.
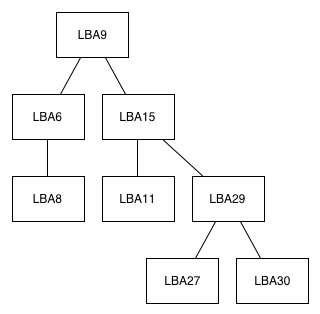
An example of an LBA-tracking binary tree, Intel's implementation is obviously far more complex. This tree can get huge.
The old indirection table grew in size as the drive was written to. Each node would keep track of a handful of data including logical block address and the physical NAND location that the block mapped to. The mapping wasn't 1:1 so many nodes would refer to a starting LBA address in addition to an offset, allowing a single node to refer to a range of physical locations.
As write requests came in, sequential data was stored as LBA + offset per node in the binary tree. Non-sequential data created a new node, growing the tree, and increasing lookup time. The tree remained balanced (for low-overhead searches, comp sci majors will remember that there's a direct relationship between the height of a binary tree and how long it takes to perform inserts/lookups on the tree), so the creation of new nodes could sometimes be very time intensive.
Given the very small DRAM that Intel wanted on its drives (to help keep costs as low as possible) and the increasing lookup times from managing an ever expanding tree, Intel would regularly defragment/compress the tree. With enough data in the tree you could actually begin compressing various nodes in the tree down into a single node. For example we might have two separate nodes in the tree that refer to sequential physical locations, which can be combined into a single node with location + offset. The tree defrag/compression process would contribute to high latency with random IO.
There was another problem however. The physical NAND had to be defragmented on a regular basis to keep pages contiguous and avoid a random sprinkling of pages on each block (this can negatively impact sequential IO performance if you go to write a large block of data and it either has to be split up amongst multiple randomly distributed blocks, or if you have to erase and rewrite a bunch of blocks to make room for the new data). The problem was that once NAND was defragmented, the logical to physical mapping tree had to be updated to reflect the new mapping, which could sometimes conflict. There could be situations where the tree could just be finished compressing itself, but the NAND would defrag itself forcing a recompression/reorganization of the tree. The fact that both the mapping tree and physical NAND had to be defragmented, and the fact that doing one could create more work for the other contributed to some potentially high latencies in the old design.
The old Intel controller had to defragment both the indirection table and the physical NAND space, and the two processes could conflict, which would create some unexpectedly high latency IO from time to time. On average, Intel was able to keep this under control, but when given the opportunity to start from scratch one major goal was to eliminate this cause of latency.








43 Comments
View All Comments
Impulses - Monday, November 5, 2012 - link
I'd say Samsung is about on par with Intel if you look at the number of major bugs requiring immediate firmware updates etc. Intel's rep took a bit of a hit when even they couldn't release an entirely bug free Sandforce drive IMO (though it wasn't a surprise).Death666Angel - Tuesday, November 6, 2012 - link
Not to mention the 8MB bug with their own controller. No product is safe, but Samsung, Intel, Crucial and Plextor seem the safest, with Samsung and Crucial being also very price competitive. But that's just how I see it. :D I have had 2 OCZ drives and not a single problem with either.Taft12 - Monday, November 5, 2012 - link
Why are you complaining about scenarios that don't exist??"But with pricing like the S3700 is featuring, the days of Intel being competitive in the consumer space may be over..."
THIS DRIVE IS NOT FOR THE CONSUMER SPACE!
"I'd rather see Intel take a two-tiered approach. By all means, keep putting out the enterprise drives for the high margins, but also keep a toe in the consumer market."
THIS IS EXACTLY WHAT INTEL HAS RIGHT NOW! And no indication that will change. This doesn't just apply to the SSD space, they've had separate consumer and server CPU lines for decades.
chrnochime - Monday, November 5, 2012 - link
Or just pay more for enterprise. Not like it isn't going to keep dropping in price anyway.philipma1957 - Monday, November 5, 2012 - link
My usage would take 10 or more years to kill this ssd. 800 gb would be pricey but a 400gb for 700 on a sale would be very tempting.MrSpadge - Tuesday, November 6, 2012 - link
Spending big on a drive with strong endurance, hoping it will last 10 years, doesn't sound like a good idea to me. Reasons:- other parts of the SSD may fail rather than NAND wear out
- performance and price are still developing so rapidly that you probably won't want to use this drive in 5 years anymore anyway
- see it lke this: if instead of paying 700$ now you'd go for a smaller drive with less endurance at 350$ you can use that 350$ (+interest) to buy a new drive in 5 years (if your SSD is really worn out by then). This one should be way faster and much bigger than the original drive, providing you much better value for the next 5 years. Plus if the old drive still works you could still use it in a less "enthusiastic" configuration.
mayankleoboy1 - Monday, November 5, 2012 - link
So intel is proud that it keeps no user data on the DRAM.But what about /sandforce and Marvell controllers ? Do they use DRAM for caching userdata ?
Is this configurable by the OEM ?
Death666Angel - Tuesday, November 6, 2012 - link
As far as I know, everyone in the consumer space but Intel chaches user data in the DRAM and they aren't dodging that either. For normal consumer use, I don't see why that would be any issue either. If you are worried about that last bit of data integrity, get an enterprise solution or a UPS, which should solve the issue, too. :)kaix2 - Monday, November 5, 2012 - link
The new controller sounds very promising for all of us who have been waiting for a new Intel controller. I would expect Intel's consumer drives to eventually get the same controller and as far as the price concern, I bet most of the price premium is really from HET-MLC NAND vs regular MLC NAND. Regular consumers don't need 10 drive write per day and the drives should be much cheaper with just regular MLC NAND.cdillon - Monday, November 5, 2012 - link
Not caching user data writes in DRAM so that you can't lose them when the power goes out is all well and good, but what happens with indirection table updates which will have to happen AT THE SAME TIME and are inextricably linked? Losing an indirection table mapping to new user data that was just written is no less bad than losing the actual user data, because either way you're losing the data.Intel has two options here... They can either write indirection table updates directly to NAND at the same time as the user data, or they can cache the indirection table updates only in DRAM and then write them to flash later. Obviously the former is the safest option and I presume this is what Intel is doing, but I've never seen anybody mention how they handle protecting the mapping table updates on any SSD, since they can arguably be MORE important than a little bit of user data due to the risk of losing absolutely everything on the drive if the table gets completely out of whack.