Memory Performance: 16GB DDR3-1333 to DDR3-2400 on Ivy Bridge IGP with G.Skill
by Ian Cutress on October 18, 2012 12:00 PM EST- Posted in
- Memory
- G.Skill
- Ivy Bridge
- DDR3
Conversion – Xilisoft 7
Another classic example of memory bandwidth and speed is during video conversion. Data is passed between the memory and the CPU for processing – ideally faster memory here helps as well as memory that can deal with consecutive reads. Multiple threads on the CPU will also provide an additional stress, as each will ask for different data from the system. Our test uses two sets of conversions: first, a series of 160 videos have the first three minutes of each converted from various formats (480p to 1080p mkv) to AAC audio; and second is the motherboard testing, converting 32 1080p videos to iPod format. Each test is measured by the time taken to complete.
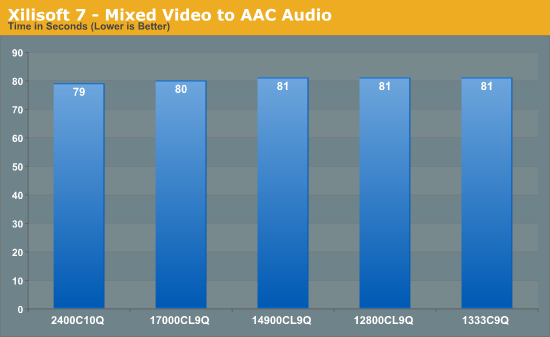
Converting to AAC seems to depend not on the memory – the movement of data from storage to memory to CPU is faster than the CPU can compute.
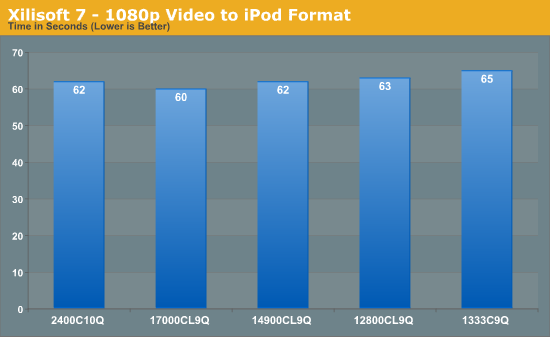
Video conversion is often one area quoted as being beneficial for memory speed, however these does not seem strictly true. As data is moved from storage to memory to the CPU, only if that memory transfer is the limiting factor does having faster memory help. In conversion to an iPod video format, that seems true moving from DDR3-1333 to DDR3-2133 just about, however it seems the limiting factor is still the CPU speed or the algorithm doing the conversion.
Folding on GPU
Memory usage is all algorithm dependent – if the calculation has a lot of small loops that do not require additional reads memory, then memory is unimportant. If the calculation requires data from other sources in those calculations, then memory can either be stressed randomly or sequentially. Using Ryan’s Folding benchmark as a platform, we are testing how much memory affects the serial calculation part of a standard F@H work unit.
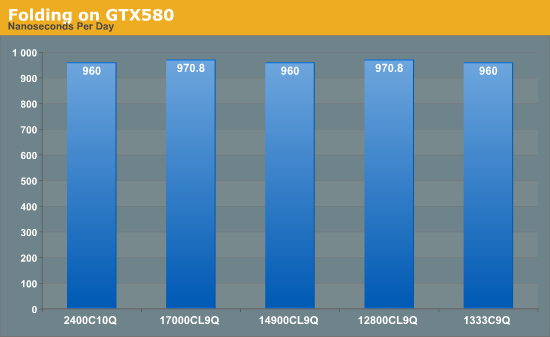
Unfortunately this test is only available to the nearest second, thus the benchmark finishes in either 89 or 90 seconds, giving appropriate ns/day. From the results, folding on GPUs is not affected by memory speed.
WinRAR x64 4.20
When compressing or converting files from one format to another, the file itself is often held in memory then passed through the CPU to be processed, then written back. If the file is larger than the available memory, then there is also loading time between the storage and the memory to consider. WinRAR is a variable multi-threaded benchmark, whereby the files it converts and compresses determines how much multi-threading takes place. When in multithreaded mode, the rate of cache misses can increase, leading to a less-than optimal scaling. Having fast memory can help with this.
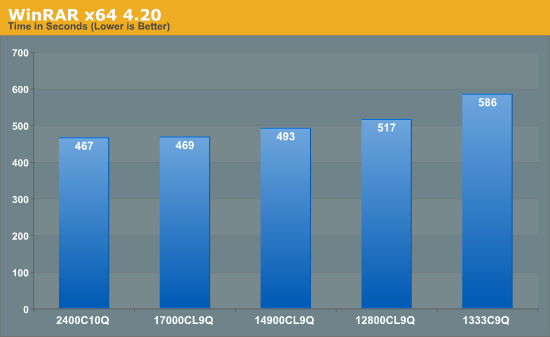
WinRAR is one of the benchmarks in our testing suite that benefits immensely from having faster memory. Moving from DDR3-1333 to DDR3-2400 speeds the process up by 20%, with the biggest gain moving from 1333 to 1600, and noticeable gains all the way up to 2133 C9.
Greysky's x264 HD 5.0.1
The x264 HD test, now version 5.0.1, tests the time to encode a 1080p video file into a high quality x264 video file. This test is standard across a range of reviews from AnandTech and other websites allowing for easy comparison. The benchmark is capable of running all cores to the maximum. Results here are reported as the average across four attempts for both the first and second passes.
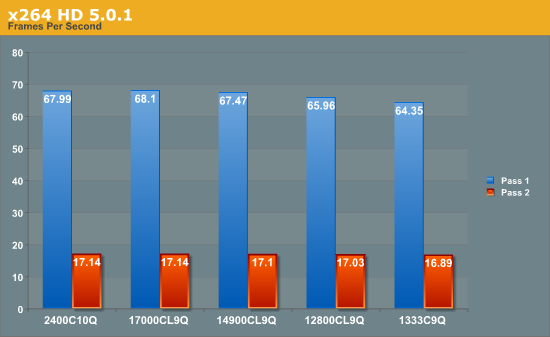
In another conversion test, we see that this benchmark gets a ~5% boost with faster memory, although Pass 1 sees a bigger boost than Pass 2. If conversion into x264 is the main purpose of the system, then the price premium of the faster memory could easily be justifiable.








114 Comments
View All Comments
frozentundra123456 - Thursday, October 18, 2012 - link
While interesting from a theoretical standpoint. I would have been more interested in a comparison in laptops using HD4000 vs A10 to see if one is more dependent on fast memory than others. To be blunt, I dont really care much about the IGP on a 3770K. It would have been a more interesting comparison in laptops where the igp might actually be used for gaming. I guess maybe it would have been more difficult to do with changing memory around so much in a laptop though.The other thing is I would have liked to see the difference in games at playable frame rates. Does it really matter if you get 5.5 or 5.9 fps? It is a slideshow anyway. My interest is if using higher speed memory could have moved a game from unplayable to playable at a particular setting or allowed moving up to higher settings in a game that was playable.
mmonnin03 - Thursday, October 18, 2012 - link
RAM by definition is Random Access which means no matter where the data is on the module the access time is the same. It doesn't matter if two bytes are on the same row or on a different bank or on a different chip on the module, the access time is the same. There is no sequential or random difference with RAM. The only difference between the different rated sticks are short/long reads, not random or sequential and any reference to random/sequential reads should be removed.Olaf van der Spek - Thursday, October 18, 2012 - link
You're joking right? :pmmonnin03 - Thursday, October 18, 2012 - link
Well if the next commenter below says their memory knowledge went up by 10x they probably believe RAM reads are different depending on whether they are random or sequential.nafhan - Thursday, October 18, 2012 - link
"Random access" means that data can be accessed randomly as opposed to just sequentially. That's it. The term is a relic of an era where sequential storage was the norm.Hard drives and CD's are both random access devices, and they are both much faster on sequential reads. An example of sequential storage would be a tape backup drive.
mmonnin03 - Thursday, October 18, 2012 - link
RAM is direct access, no sequential or randomness about it. Access time is the same anywhere on the module.XX reads the same as
X
X
Where X is a piece of data and they are laid out in columns/rows.
Both are separate commands and incure the same latencies.
extide - Thursday, October 18, 2012 - link
No, you are wrong. Period. nafhan's post is correct.menting - Thursday, October 18, 2012 - link
no, mmonnin03 is more correct.DRAM has the same latency (relatively speaking.. it's faster by a little for the bits closer to the address decoder) for anywhere in the memory, as defined by the tAA spec for reads. For writes it's not as easy to determine since it's internal, but can be guessed from the tRC spec.
The only time that DRAM reads can be faster for consecutive reads, and considered "sequential" is if you open a row, and continue to read all the columns in that row before precharging, because the command would be Activate, Read, Read, Read .... Read, Precharge, whereas a "random access" will most likely be Activate, Read, Precharge most of the time.
The article is misleading, using "sequential reads" in the article. There is really no "sequential", because depending if you are sequential in row, column, or bank, you get totally different results.
jwilliams4200 - Thursday, October 18, 2012 - link
I say mmonnin03 is precisely wrong when he claims that " no matter where the data is on the module the access time is the same".The read latency can vary by about a factor of 3 times whether the read is from an already open row, or whether the desired read comes from a different row than one already open.
That makes a big difference in total read time, especially if you are reading all the bytes in a page.
menting - Friday, October 19, 2012 - link
no. he is correct.if every read has the conditions set up equally (ie the parameters are the same, only the address is not), then the access time is the same.
so if address A is from a row that is already open, the time to read that address is the same as address B, if B from a row that is already open
you cannot have a valid comparison if you don't keep the conditions the same between 2 addresses. It's almost like saying the latency is different between 2 reads because they were measured at different PVT corners.