Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTThe Haswell Front End
Conroe was a very wide machine. It brought us the first 4-wide front end of any x86 micro-architecture, meaning it could fetch and decode up to 4 instructions in parallel. We've seen improvements to the front end since Conroe, but the overall machine width hasn't changed - even with Haswell.
Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.
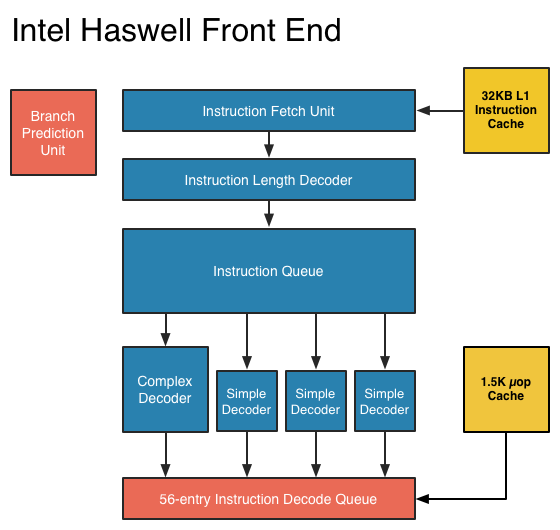
In short, there aren't many major, high-level changes to see here. Instructions are fetched at the top, sent through a bunch of steps before getting to the decoders where they're converted from macro-ops (x86 instructions) to an internally understood format known to Intel as micro-ops (or µops). The instruction fetcher can grab 4 - 5 x86 instructions at a time, and the decoders can output up to 4 micro-ops per clock.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.








245 Comments
View All Comments
tipoo - Sunday, October 7, 2012 - link
I don't think so, doesn't the HD4000 have more bandwidth to work with than AMDs APUs yet offers worse performance? They still had headroom there. I think it's just for TDP, they limit how much power the GPUs can use since the architecture is oriented at mobile.magnimus1 - Friday, October 5, 2012 - link
Would love to hear your take on how Intel's latest and greatest fares against Qualcomm's latest and greatest!cosmotic - Friday, October 5, 2012 - link
Ah, an MPEG2 encoder. Just in time!jamyryals - Friday, October 5, 2012 - link
This made me :)name99 - Friday, October 5, 2012 - link
We laugh but one possibility is that Intel hopes to sell Haswell's inside US broadcast equipment.There isn't much broadcast equipment sold, but the costs are massive, and there's no obvious reason not to replace much of that custom hardware with intel chips.
And much of the existing broadcast hardware (at least the MPEG2-encoding part) is obviously garbage --- the artifacts I see on broadcast TV are bad even for the prime-time networks, and are truly awful for the budget independent operators.
Much like they have written a cell-tower stack to run on i7's to replace the similarly grossly over-priced custom hardware that lives in cell towers, and are currently deploying in China. Anand wrote about this about two weeks ago.
vt1hun - Friday, October 5, 2012 - link
Do you have an idea when Intel will move to DDR4 ? Not with Haswell according to this article.Thank you
tipoo - Friday, October 5, 2012 - link
Haswell EX for servers will support DDR4, but even Broadwell on desktops is only DDR3, we won't see DDR4 in desktops until 2015.jwcalla - Friday, October 5, 2012 - link
We'll probably see DDR4 in the ARM space before we have it on Intel.Maybe this should be AMD's focus of attack: if they can't compete on performance, at least try on chipset features.
Perhaps Intel's biggest concern would be if somebody comes along with a super-efficient x86 emulator for ARM. Going forward, "legacy applications" is going to be an increasingly important selling point to prevent ARM inroads on the low end.
Microsoft keeping their Windows ARM version locked-down is a key to that too, and likely a deference to their relationship with Intel. But Apple is less likely to similarly constrain themselves.
meloz - Saturday, October 6, 2012 - link
>We'll probably see DDR4 in the ARM space before we have it on Intel.>Maybe this should be AMD's focus of attack: if they can't compete on performance, at least try on chipset features.
The problem with DDR4 is likely going to be the price. We all know how the memory industry likes to jack up the prices whenever a new spec comes out. Remember how expensive DDr3 was when it started to replace DDR2?
Some people joke that this transition is the only time they make any money in the RAM business, and considering the low prices of DDR3 you have to wonder.
DDR4 might offer some performance and power advantage on release, but it will likely be more expensive and take time (12-18 months?) to offer a compelling performance / $ advantage over cheap DDR3 variants.
If AMD is trying to position itself as 'value' brand, chaining themselves to DDR4 (before Intel's volume brings down the prices for everyone) could spell their doom.
Kevin G - Friday, October 5, 2012 - link
Intel is set to launch Ivy Bridge EX on a new socket late in 2013 on a new socket. The on-die controller will likely use memory buffering similar to what Nehalem-EX and Westmere-EX use. The buffer chips may initially use DDR3 but this would allow for a trivial migration to DDR4 since the on-die controller doesn't communicate directly with the memory chips.Come to think of it, Intel could migration Nehalem-EX/Westmere-EX to DDR4 with a chipset upgrade. Vendors like HP put the buffer chips and memory slots on a daughter card so only that part would need replacement.