Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTThe Haswell Front End
Conroe was a very wide machine. It brought us the first 4-wide front end of any x86 micro-architecture, meaning it could fetch and decode up to 4 instructions in parallel. We've seen improvements to the front end since Conroe, but the overall machine width hasn't changed - even with Haswell.
Haswell leaves the overall pipeline untouched. It's still the same 14 - 19 stage pipeline that we saw with Sandy Bridge depending on whether or not the instruction is found in the uop cache (which happens around 80% of the time). L1/L2 cache latencies are unchanged as well. Since Nehalem, Intel's Core micro-architectures have supported execution of two instruction threads per core to improve execution hardware utilization. Haswell also supports 2-way SMT/Hyper Threading.
The front end remains 4-wide, although Haswell features a better branch predictor and hardware prefetcher so we'll see better efficiency. Since the pipeline depth hasn't increased but overall branch prediction accuracy is up we'll see a positive impact on overall IPC (instructions executed per clock). Haswell is also more aggressive on the speculative memory access side.
The image below is a crude representation I put together of the Haswell front end compared to the two previous tocks. If you click the buttons below you'll toggle between Haswell, Sandy Bridge and Nehalem diagrams, with major changes highlighted.
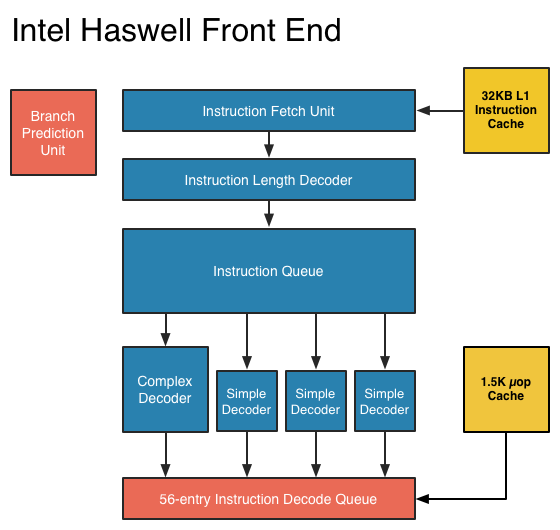
In short, there aren't many major, high-level changes to see here. Instructions are fetched at the top, sent through a bunch of steps before getting to the decoders where they're converted from macro-ops (x86 instructions) to an internally understood format known to Intel as micro-ops (or µops). The instruction fetcher can grab 4 - 5 x86 instructions at a time, and the decoders can output up to 4 micro-ops per clock.
Sandy Bridge introduced the 1.5K µop cache that caches decoded micro-ops. When future instruction fetch requests are made, if the instructions are contained within the µop cache everything north of the cache is powered down and the instructions are serviced from the µop cache. The decode stages are very power hungry so being able to skip them is a boon to power efficiency. There are also performance benefits as well. A hit in the µop cache reduces the effective integer pipeline to 14 stages, the same length as it was in Conroe in 2006. Haswell retains all of these benefits. Even the µop cache size remains unchanged at 1.5K micro-ops (approximately 6KB in size).
Although it's noted above as a new/changed block, the updated instruction decode queue (aka allocation queue) was actually one of the changes made to improve single threaded performance in Ivy Bridge.
The instruction decode queue (where instructions go after they've been decoded) is no longer statically partitioned between the two threads that each core can service.
The big changes in Haswell are at the back end of the pipeline, in the execution engine.








245 Comments
View All Comments
dishayu - Friday, October 5, 2012 - link
Woah! I did not even think of that. That is VERY compelling but i can't do without unlocked multiplier, so there is no perfect processor for me still :(StevoLincolnite - Friday, October 5, 2012 - link
Or just go with a Socket 2011 Core i7 3930K like I have and do a little bit of undervolting and has no IGP's.I think the reason why the Desktop space has seen decreasing/stagnant sales is simply because allot of people see no need to upgrade.
A Core 2 Quad Q6600 @ 3.6ghz, with a decent chunk of Ram and a decent graphics card is actually fairly capable of running almost every game at maximum settings.
Heck I know people who are perfectly happy sitting with a Pentium 4 for basic web use.
I think a change needs to happen where software catches up with hardware to give people a reason to upgrade and drive sales which might reinvigorate Intel and AMD to innovate.
Windows 8 and the next generation consoles might actually help in that regard.
De_Com - Friday, October 5, 2012 - link
Well said Steve. Couldn't agree with you more.
I'm running a Core 2 Extreme QX6850 at 3.4ghz, 1066Mhz DDR2 Ram and a GTX295 and it still rocks all the newest games at or close to max settings.
Will have this system 4 years this November.(all except the GTX295, which was upgraded from a 9800 GX2), even now I'm thinking that was a waste of cash.
I've gone to upgrade at least twice each year, but can't justify it.
The only place I'd see returns is in the power costs, but hey, whats a few extra cents.....
The system meets my needs, and forking out for a similar system today would cost around the €1800 mark.
Until the software can better utilize the components I'm holding out until Summer 2013, that'll be over 4 years I've gotten out of this system. Up until 2008 I slavishly upgraded every year or 2.
lukarak - Saturday, October 6, 2012 - link
This (late) December, i will have had my i7 for 4 years, and i have not seen a single reason to upgrade. The GPU is 2.5 years old (GTX480, was 280 before that).A x58 motherboard has 6 memory slots, and now houses 24 GB of ram for virtual machines, which can go 48 GB for a reasonable price.
I just don't see the need to do anything more, and this will probably fail from old age before i would need a drastically faster machine.
xaml - Thursday, May 23, 2013 - link
"but hey, whats a few extra cents....."Sure, it's probably not your generation to take the hit, having to deal with the consequences of energy excesses.
DanNeely - Friday, October 5, 2012 - link
Is that actually an IGPless chip, or just a standard LGA1155 quadcore chip with a disabled IGP.csroc - Friday, October 5, 2012 - link
I don't mind power savings, the few times my system is idle it could certainly benefit but overall it would mean reduced consumption even under load. My system just doesn't spend enough time in idle with my Q9450.Ultimately it does seem as though the software demand for faster CPU hardware has slowed and between that and the lack of real competition, so has the development.
If it weren't for the fact that I need more RAM or wanted faster photo processing (and may start doing some video) I'd probably keep what I've got a bit longer. My Q9450 hasn't held me back from playing any games yet. The 20% OC I've been running doesn't hurt but ultimately a lot of things just aren't CPU limited anymore.
Kidster3001 - Monday, October 15, 2012 - link
If you're playing 3D games then your CPU is likely "idle" 50%-75% of the time. Idle time does not just mean when the display is off.IanCutress - Friday, October 5, 2012 - link
You may think this as a result of all the low power talk, but Haswell is doing something rather important on the peak performance side. The increase in the size of the execution engine is important - adding in another integer ALU and another load/store means that in workloads that share INT and FPU performance (think loop counters which store an INT for loop iteration then perform some FP calcs) will improve. By increasing the bandwidth available and being able to keep the two FPU fed with info means a greater throughput as long as the bandwidth and thread switching can hide any additional L3 latency. Personally I'm thinking this may be a subtle move towards more threads per core in future architectures. Some of the non x86 are abusing 8 threads/core with improvement gains, so I wonder if that would be possible here. Ideally we would like every port on the execution engine to do everything, with a single pipeline feeding it and excellent branch prediction to help with single thread speed. Smaller nodes help with that silicon real estate, or someone will stumble on a better/smaller way to actually physically create these things.Ian
DanNeely - Friday, October 5, 2012 - link
I'm curious what IBM/Oracle's high SMT designs look like on the execution port side. As long as it's business as usual I doubt Intel will ever make all the ports do everything because it would just be hogging a huge amount of die area when the odds of each thread doing all of the same instruction type constantly are very low. Smaller bursts of one type can be spread out using OOOE.