Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTCPU Architecture Improvements: Background
Despite all of this platform discussion, we must not forget that Haswell is the fourth tock since Intel instituted its tick-tock cadence. If you're not familiar with the terminology by now a tock is a "new" microprocessor architecture on an existing manufacturing process. In this case we're talking about Intel's 22nm 3D transistors, that first debuted with Ivy Bridge. Although Haswell is clearly SoC focused, the designs we're talking about today all use Intel's 22nm CPU process - not the 22nm SoC process that has yet to debut for Atom. It's important to not give Intel too much credit on the manufacturing front. While it has a full node advantage over the competition in the PC space, it's currently only shipping a 32nm low power SoC process. Intel may still have a more power efficient process at 32nm than its other competitors in the SoC space, but the full node advantage simply doesn't exist there yet.
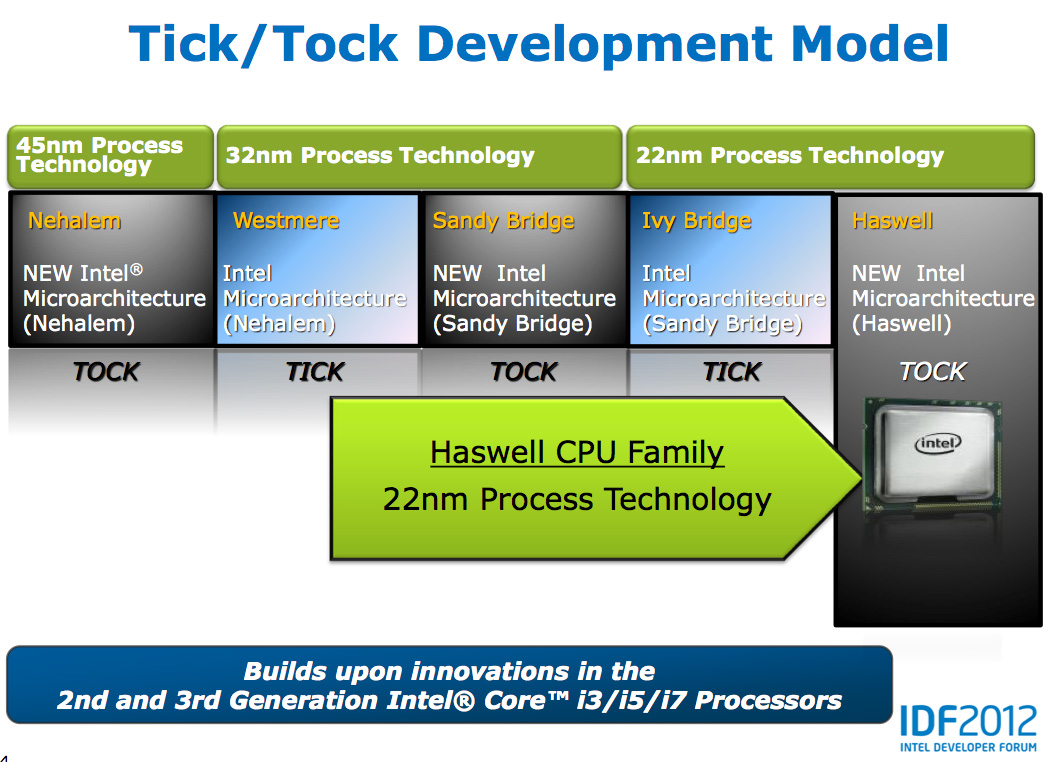
Although Haswell is labeled as a new micro-architecture, it borrows heavily from those that came before it. Without going into the full details on how CPUs work I feel like we need a bit of a recap to really appreciate the changes Intel made to Haswell.
At a high level the goal of a CPU is to grab instructions from memory and execute those instructions. All of the tricks and improvements we see from one generation to the next just help to accomplish that goal faster.
The assembly line analogy for a pipelined microprocessor is over used but that's because it is quite accurate. Rather than seeing one instruction worked on at a time, modern processors feature an assembly line of steps that breaks up the grab/execute process to allow for higher throughput.
The basic pipeline is as follows: fetch, decode, execute, commit to memory. You first fetch the next instruction from memory (there's a counter and pointer that tells the CPU where to find the next instruction). You then decode that instruction into an internally understood format (this is key to enabling backwards compatibility). Next you execute the instruction (this stage, like most here, is split up into fetching data needed by the instruction among other things). Finally you commit the results of that instruction to memory and start the process over again.
Modern CPU pipelines feature many more stages than what I've outlined here. Conroe featured a 14 stage integer pipeline, Nehalem increased that to 16 stages, while Sandy Bridge saw a shift to a 14 - 19 stage pipeline (depending on hit/miss in the decoded uop cache).
The front end is responsible for fetching and decoding instructions, while the back end deals with executing them. The division between the two halves of the CPU pipeline also separates the part of the pipeline that must execute in order from the part that can execute out of order. Instructions have to be fetched and completed in program order (can't click Print until you click File first), but they can be executed in any order possible so long as the result is correct.
Why would you want to execute instructions out of order? It turns out that many instructions are either dependent on one another (e.g. C=A+B followed by E=C+D) or they need data that's not immediately available and has to be fetched from main memory (a process that can take hundreds of cycles, or an eternity in the eyes of the processor). Being able to reorder instructions before they're executed allows the processor to keep doing work rather than just sitting around waiting.
Sidebar on Performance Modeling
Microprocessor design is one giant balancing act. You model application performance and build the best architecture you can in a given die area for those applications. Tradeoffs are inevitably made as designers are bound by power, area and schedule constraints. You do the best you can this generation and try to get the low hanging fruit next time.
Performance modeling includes current applications of value, future algorithms that you expect to matter when the chip ships as well as insight from key software developers (if Apple and Microsoft tell you that they'll be doing a lot of realistic fur rendering in 4 years, you better make sure your chip is good at what they plan on doing). Obviously you can't predict everything that will happen, so you continue to model and test as new applications and workloads emerge. You feed that data back into the design loop and it continues to influence architectures down the road.
During all of this modeling, even once a design is done, you begin to notice bottlenecks in your design in various workloads. Perhaps you notice that your L1 cache is too small for some newer workloads, or that for a bunch of popular games you're seeing a memory access pattern that your prefetchers don't do a good job of predicting. More fundamentally, maybe you notice that you're decode bound more often than you'd like - or alternatively that you need more integer ALUs or FP hardware. You take this data and feed it back to the team(s) working on future architectures.
The folks working on future architectures then prioritize the wish list and work on including what they can.








245 Comments
View All Comments
dishayu - Friday, October 5, 2012 - link
Woah! I did not even think of that. That is VERY compelling but i can't do without unlocked multiplier, so there is no perfect processor for me still :(StevoLincolnite - Friday, October 5, 2012 - link
Or just go with a Socket 2011 Core i7 3930K like I have and do a little bit of undervolting and has no IGP's.I think the reason why the Desktop space has seen decreasing/stagnant sales is simply because allot of people see no need to upgrade.
A Core 2 Quad Q6600 @ 3.6ghz, with a decent chunk of Ram and a decent graphics card is actually fairly capable of running almost every game at maximum settings.
Heck I know people who are perfectly happy sitting with a Pentium 4 for basic web use.
I think a change needs to happen where software catches up with hardware to give people a reason to upgrade and drive sales which might reinvigorate Intel and AMD to innovate.
Windows 8 and the next generation consoles might actually help in that regard.
De_Com - Friday, October 5, 2012 - link
Well said Steve. Couldn't agree with you more.
I'm running a Core 2 Extreme QX6850 at 3.4ghz, 1066Mhz DDR2 Ram and a GTX295 and it still rocks all the newest games at or close to max settings.
Will have this system 4 years this November.(all except the GTX295, which was upgraded from a 9800 GX2), even now I'm thinking that was a waste of cash.
I've gone to upgrade at least twice each year, but can't justify it.
The only place I'd see returns is in the power costs, but hey, whats a few extra cents.....
The system meets my needs, and forking out for a similar system today would cost around the €1800 mark.
Until the software can better utilize the components I'm holding out until Summer 2013, that'll be over 4 years I've gotten out of this system. Up until 2008 I slavishly upgraded every year or 2.
lukarak - Saturday, October 6, 2012 - link
This (late) December, i will have had my i7 for 4 years, and i have not seen a single reason to upgrade. The GPU is 2.5 years old (GTX480, was 280 before that).A x58 motherboard has 6 memory slots, and now houses 24 GB of ram for virtual machines, which can go 48 GB for a reasonable price.
I just don't see the need to do anything more, and this will probably fail from old age before i would need a drastically faster machine.
xaml - Thursday, May 23, 2013 - link
"but hey, whats a few extra cents....."Sure, it's probably not your generation to take the hit, having to deal with the consequences of energy excesses.
DanNeely - Friday, October 5, 2012 - link
Is that actually an IGPless chip, or just a standard LGA1155 quadcore chip with a disabled IGP.csroc - Friday, October 5, 2012 - link
I don't mind power savings, the few times my system is idle it could certainly benefit but overall it would mean reduced consumption even under load. My system just doesn't spend enough time in idle with my Q9450.Ultimately it does seem as though the software demand for faster CPU hardware has slowed and between that and the lack of real competition, so has the development.
If it weren't for the fact that I need more RAM or wanted faster photo processing (and may start doing some video) I'd probably keep what I've got a bit longer. My Q9450 hasn't held me back from playing any games yet. The 20% OC I've been running doesn't hurt but ultimately a lot of things just aren't CPU limited anymore.
Kidster3001 - Monday, October 15, 2012 - link
If you're playing 3D games then your CPU is likely "idle" 50%-75% of the time. Idle time does not just mean when the display is off.IanCutress - Friday, October 5, 2012 - link
You may think this as a result of all the low power talk, but Haswell is doing something rather important on the peak performance side. The increase in the size of the execution engine is important - adding in another integer ALU and another load/store means that in workloads that share INT and FPU performance (think loop counters which store an INT for loop iteration then perform some FP calcs) will improve. By increasing the bandwidth available and being able to keep the two FPU fed with info means a greater throughput as long as the bandwidth and thread switching can hide any additional L3 latency. Personally I'm thinking this may be a subtle move towards more threads per core in future architectures. Some of the non x86 are abusing 8 threads/core with improvement gains, so I wonder if that would be possible here. Ideally we would like every port on the execution engine to do everything, with a single pipeline feeding it and excellent branch prediction to help with single thread speed. Smaller nodes help with that silicon real estate, or someone will stumble on a better/smaller way to actually physically create these things.Ian
DanNeely - Friday, October 5, 2012 - link
I'm curious what IBM/Oracle's high SMT designs look like on the execution port side. As long as it's business as usual I doubt Intel will ever make all the ports do everything because it would just be hogging a huge amount of die area when the odds of each thread doing all of the same instruction type constantly are very low. Smaller bursts of one type can be spread out using OOOE.