Intel's Haswell Architecture Analyzed: Building a New PC and a New Intel
by Anand Lal Shimpi on October 5, 2012 2:45 AM ESTCPU Architecture Improvements: Background
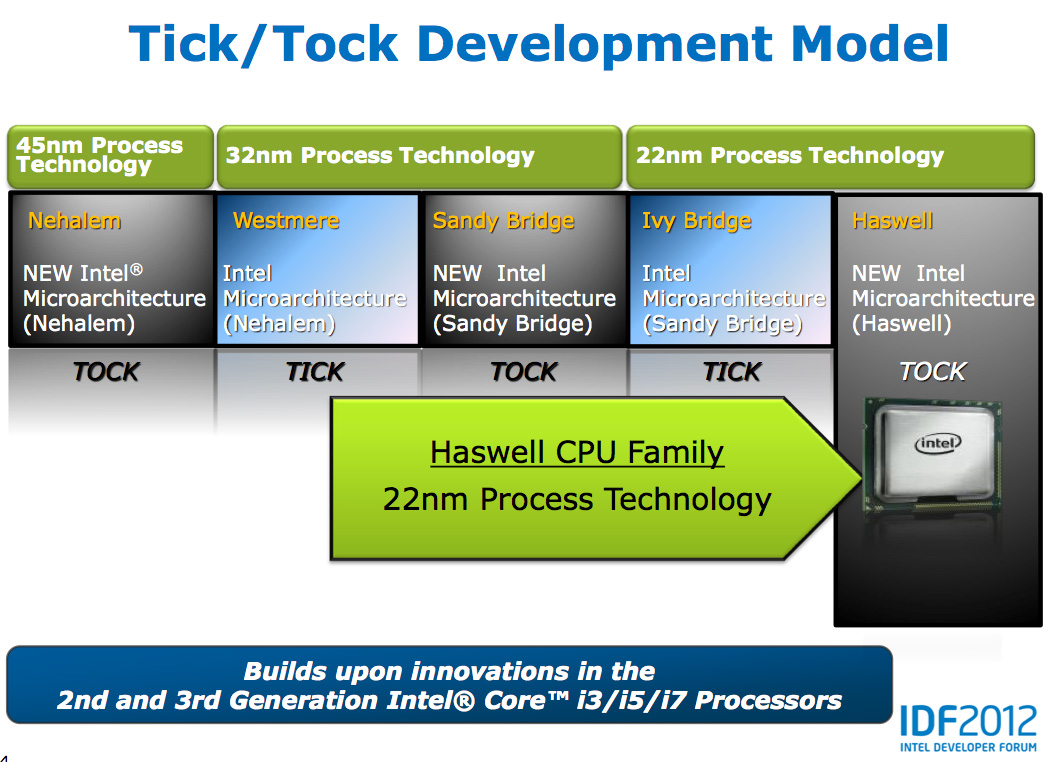
Despite all of this platform discussion, we must not forget that Haswell is the fourth tock since Intel instituted its tick-tock cadence. If you're not familiar with the terminology by now a tock is a "new" microprocessor architecture on an existing manufacturing process. In this case we're talking about Intel's 22nm 3D transistors, that first debuted with Ivy Bridge. Although Haswell is clearly SoC focused, the designs we're talking about today all use Intel's 22nm CPU process - not the 22nm SoC process that has yet to debut for Atom. It's important to not give Intel too much credit on the manufacturing front. While it has a full node advantage over the competition in the PC space, it's currently only shipping a 32nm low power SoC process. Intel may still have a more power efficient process at 32nm than its other competitors in the SoC space, but the full node advantage simply doesn't exist there yet.
Although Haswell is labeled as a new micro-architecture, it borrows heavily from those that came before it. Without going into the full details on how CPUs work I feel like we need a bit of a recap to really appreciate the changes Intel made to Haswell.
At a high level the goal of a CPU is to grab instructions from memory and execute those instructions. All of the tricks and improvements we see from one generation to the next just help to accomplish that goal faster.
The assembly line analogy for a pipelined microprocessor is over used but that's because it is quite accurate. Rather than seeing one instruction worked on at a time, modern processors feature an assembly line of steps that breaks up the grab/execute process to allow for higher throughput.
The basic pipeline is as follows: fetch, decode, execute, commit to memory. You first fetch the next instruction from memory (there's a counter and pointer that tells the CPU where to find the next instruction). You then decode that instruction into an internally understood format (this is key to enabling backwards compatibility). Next you execute the instruction (this stage, like most here, is split up into fetching data needed by the instruction among other things). Finally you commit the results of that instruction to memory and start the process over again.
Modern CPU pipelines feature many more stages than what I've outlined here. Conroe featured a 14 stage integer pipeline, Nehalem increased that to 16 stages, while Sandy Bridge saw a shift to a 14 - 19 stage pipeline (depending on hit/miss in the decoded uop cache).
The front end is responsible for fetching and decoding instructions, while the back end deals with executing them. The division between the two halves of the CPU pipeline also separates the part of the pipeline that must execute in order from the part that can execute out of order. Instructions have to be fetched and completed in program order (can't click Print until you click File first), but they can be executed in any order possible so long as the result is correct.
Why would you want to execute instructions out of order? It turns out that many instructions are either dependent on one another (e.g. C=A+B followed by E=C+D) or they need data that's not immediately available and has to be fetched from main memory (a process that can take hundreds of cycles, or an eternity in the eyes of the processor). Being able to reorder instructions before they're executed allows the processor to keep doing work rather than just sitting around waiting.
Sidebar on Performance Modeling
Microprocessor design is one giant balancing act. You model application performance and build the best architecture you can in a given die area for those applications. Tradeoffs are inevitably made as designers are bound by power, area and schedule constraints. You do the best you can this generation and try to get the low hanging fruit next time.
Performance modeling includes current applications of value, future algorithms that you expect to matter when the chip ships as well as insight from key software developers (if Apple and Microsoft tell you that they'll be doing a lot of realistic fur rendering in 4 years, you better make sure your chip is good at what they plan on doing). Obviously you can't predict everything that will happen, so you continue to model and test as new applications and workloads emerge. You feed that data back into the design loop and it continues to influence architectures down the road.
During all of this modeling, even once a design is done, you begin to notice bottlenecks in your design in various workloads. Perhaps you notice that your L1 cache is too small for some newer workloads, or that for a bunch of popular games you're seeing a memory access pattern that your prefetchers don't do a good job of predicting. More fundamentally, maybe you notice that you're decode bound more often than you'd like - or alternatively that you need more integer ALUs or FP hardware. You take this data and feed it back to the team(s) working on future architectures.
The folks working on future architectures then prioritize the wish list and work on including what they can.








245 Comments
View All Comments
jigglywiggly - Friday, October 5, 2012 - link
wish the onboard gpu was better =/woula been nice for a laptop
tipoo - Friday, October 5, 2012 - link
2x the HD4000 is pretty decent for integrated. I wonder if that's 2x with or without the eDRAM cache though.ElvenLemming - Friday, October 5, 2012 - link
It's been known for a while that Haswell was only going to have a moderate improvement in the iGPU and the next big overhaul would be coming with Broadwell.csroc - Friday, October 5, 2012 - link
This is impressive, it might convince me it's time for a new laptop. On the other hand I also need to build a new desktop workstation and Haswell so far hasn't impressed me in that space.mayankleoboy1 - Friday, October 5, 2012 - link
Is Intel sacrificing Desktop CPU performance to make an architecture that is geared to the mobile space ?csroc - Friday, October 5, 2012 - link
It feels that way to me. Mobile performance seems to be their big concern now, that and improving the GPU. Two things I generally can't be bothered to care about when I'm looking to build a new workstation. I suspect I'll build an Ivy Bridge system because I could use it now and see nothing worth getting excited about.dishayu - Friday, October 5, 2012 - link
I fully share your sentiment. TO be very crude, i don't mind at all, paying for power imporvements, because it will pay back for itself in the long term (by consuming less power AND needing lesser cooling). But i DO mind very much, paying for 40 EUs of GPU on my desktop build which i will not use even for a second. Me, you and many others do not care about on-die graphics and Intel should realize that.I don't know why intel can't offer us both GPU and GPU-less options, the way they did with motherboards back in the days? P965 had no graphics, G965 did. Pretty sure it's technologically not an issue.
DanNeely - Friday, October 5, 2012 - link
If it makes you feel any better; reports elsewhere are that GT3 will be mobile only, because desktops don't have the power/size constraints driving the need for premium IGPs.Intel's not IGP CPUs are the E series parts; unfortunately they've failed to execute on the enthusiast side in terms of price/launch date leaving them as mostly server parts.
There just aren't enough of us to justify Intel adding another die design for their mass market socket that doesn't have an IGP at all instead of just letting us turn it off and use the extra TDP headroom for more time at boost speeds.
Omoronovo - Friday, October 5, 2012 - link
I'm somewhat in disagreement with you both.Whilst I share a concern that Intel is no longer focusing on raw performance improvements in the purely desktop space, they are still delivering incremental updates to the architecture that will benefit all current software (even if only marginally). However, processor performance has been reaching more and more diminishing returns in recent years, namely that software is simply not able to take advantage of multiple cores and improved performance because of (primarily) locks and complexity in creating multi-threaded applications.
As such, Intel has been focusing on that area - to make it easier for software and software developers to take advantage of the performance that exists *now* rather than brute forcing the issue by simply delivering more raw performance (much of which will be wasted/remain idle due to current software constraints).
With this, Intel has been able to focus on keeping performance high whilst subsequently dropping power usage substantially - the fact the iGPU is oftentimes not being used in a desktop environment does not invalidate it's utility - QuickSync is a prime example of where the gpu can accelerate certain types of processing, and if more software takes advantage of this we should see even more gains in future.
For the last 6 years or so, Intel has shown that it knows what demands will be placed on future computing hardware, and they seem convinced that this is the way to go. We might not be there yet, but technologies like C++AMP, OpenCL and such make me hopeful that this will change in a few years.
cmrx64 - Friday, October 5, 2012 - link
I solved this problem by buying an Ivy Bridge Xeon (specifically, an E3-1230v2). No GPU, lower power consumption than the equivalent i5/i7, has hyperthreading, performs really good, and a lot cheaper than an i7.If you don't care about the GPU, look to the Xeon line.