The iPhone 5 Review
by Anand Lal Shimpi, Brian Klug & Vivek Gowri on October 16, 2012 11:33 AM EST- Posted in
- Smartphones
- Apple
- Mobile
- iPhone 5
Apple's Swift: Pipeline Depth & Memory Latency
Section by Anand Shimpi
For the first time since the iPhone's introduction in 2007, Apple is shipping a smartphone with a CPU clock frequency greater than 1GHz. The Cortex A8 in the iPhone 3GS hit 600MHz, while the iPhone 4 took it to 800MHz. With the iPhone 4S, Apple chose to maintain the same 800MHz operating frequency as it moved to dual-Cortex A9s. Staying true to its namesake, Swift runs at a maximum frequency of 1.3GHz as implemented in the iPhone 5's A6 SoC. Note that it's quite likely the 4th generation iPad will implement an even higher clocked version (1.5GHz being an obvious target).
Clock speed alone doesn't tell us everything we need to know about performance. Deeper pipelines can easily boost clock speed but come with steep penalties for mispredicted branches. ARM's Cortex A8 featured a 13 stage pipeline, while the Cortex A9 moved down to only 8 stages while maintining similar clock speeds. Reducing pipeline depth without sacrificing clock speed contributed greatly to the Cortex A9's tangible increase in performance. The Cortex A15 moves to a fairly deep 15 stage pipeline, while Krait is a bit more conservative at 11 stages. Intel's Atom has the deepest pipeline (ironically enough) at 16 stages.
To find out where Swift falls in all of this I wrote two different codepaths. The first featured an easily predictable branch that should almost always be taken. The second codepath featured a fairly unpredictable branch. Branch predictors work by looking at branch history - branches with predictable history should be, well, easy to predict while the opposite is true for branches with a more varied past. This time I measured latency in clocks for the main code loop:
| Branch Prediction Code | ||||||
| Apple A3 (Cortex A8 @ 600MHz | Apple A5 (2 x Cortex A9 @ 800MHz | Apple A6 (2 x Swift @ 1300MHz | ||||
| Easy Branch | 14 clocks | 9 clocks | 12 clocks | |||
| Hard Branch | 70 clocks | 48 clocks | 73 clocks | |||
The hard branch involves more compares and some division (I'm basically branching on odd vs. even values of an incremented variable) so the loop takes much longer to execute, but note the dramatic increase in cycle count between the Cortex A9 and Swift/Cortex A8. If I'm understanding this data correctly it looks like the mispredict penalty for Swift is around 50% longer than for ARM's Cortex A9, and very close to the Cortex A8. Based on this data I would peg Swift's pipeline depth at around 12 stages, very similar to Qualcomm's Krait and just shy of ARM's Cortex A8.
Note that despite the significant increase in pipeline depth Apple appears to have been able to keep IPC, at worst, constant (remember back to our scaled Geekbench scores - Swift never lost to a 1.3GHz Cortex A9). The obvious explanation there is a significant improvement in branch prediction accuracy, which any good chip designer would focus on when increasing pipeline depth like this. Very good work on Apple's part.
The remaining aspect of Swift that we have yet to quantify is memory latency. From our iPhone 5 performance preview we already know there's a tremendous increase in memory bandwidth to the CPU cores, but as the external memory interface remains at 64-bits wide all of the changes must be internal to the cache and memory controllers. I went back to Nirdhar's iOS test vehicle and wrote some new code, this time to access a large data array whose size I could vary. I created an array of a finite size and added numbers stored in the array. I increased the array size and measured the relationship between array size and code latency. With enough data points I should get a good idea of cache and memory latency for Swift compared to Apple's implementation of the Cortex A8 and A9.
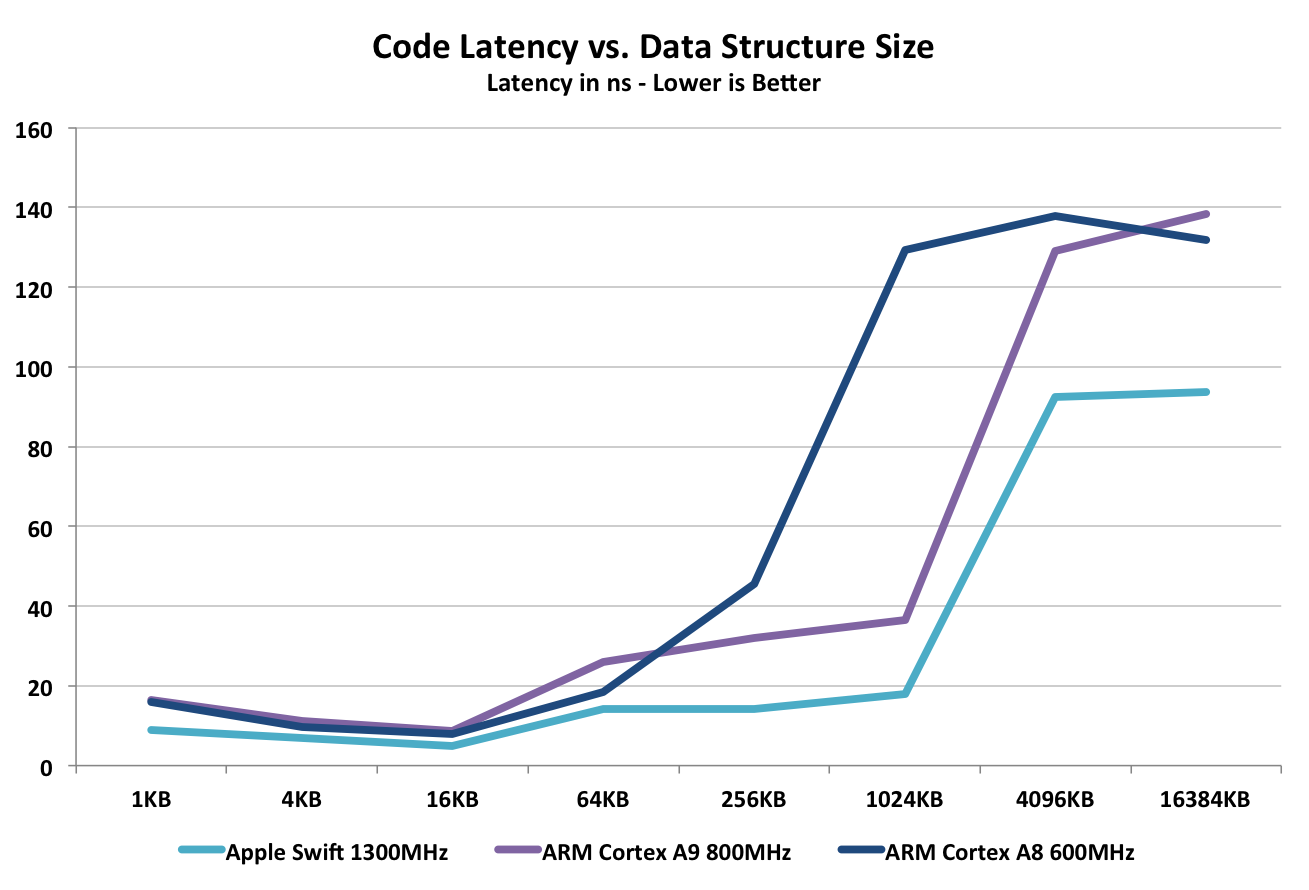
At relatively small data structure sizes Swift appears to be a bit quicker than the Cortex A8/A9, but there's near convergence around 4 - 16KB. Take a look at what happens once we grow beyond the 32KB L1 data cache of these chips. Swift manages around half the latency for running this code as the Cortex A9 (the Cortex A8 has a 256KB L2 cache so its latency shoots up much sooner). Even at very large array sizes Swift's latency is improved substantially. Note that this data is substantiated by all of the other iOS memory benchmarks we've seen. A quick look at Geekbench's memory and stream tests show huge improvements in bandwidth utilization:
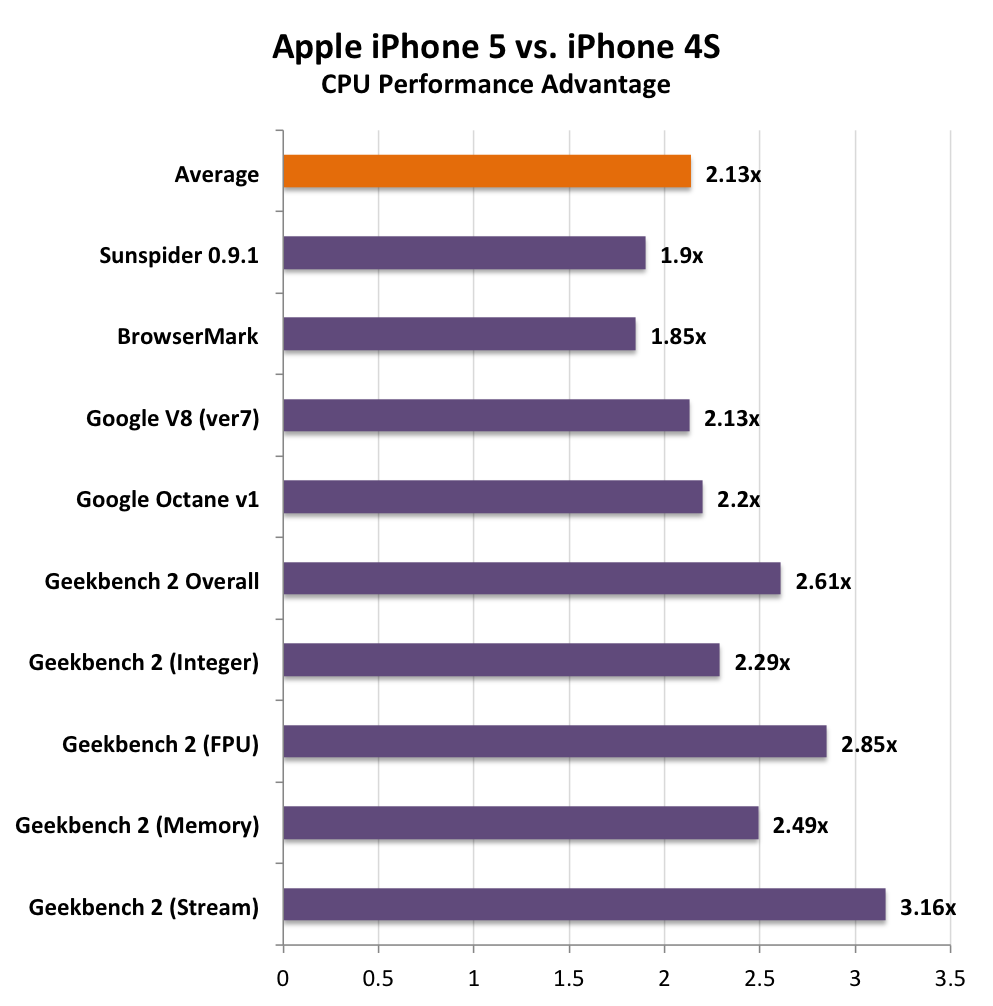
Couple the dedicated load/store port with a much lower latency memory subsystem and you get 2.5 - 3.2x the memory performance of the iPhone 4S. It's the changes to the memory subsystem that really enable Swift's performance.








276 Comments
View All Comments
dagamer34 - Tuesday, October 16, 2012 - link
Yeah, when are we going to see PowerVR 6?ltcommanderdata - Tuesday, October 16, 2012 - link
I think it's expected mid-2013, so it would have been a big stretch to have made it for the iPhone 5. Apple didn't really have that much choice with sticking to the SGX543MP since happened to be off cadence. Even making it for the iPad 4 might be iffy.peat - Tuesday, October 16, 2012 - link
I was pushed to see the 'considerable' difference between the thickness of the iP4 and iP5 in the pic. Looking at the dimensions in the table it's thinner by a truly staggering 11%.Q. Since when has an 11% change in anything equated to "considerable". But yup, I still want one.
darwinosx - Tuesday, October 16, 2012 - link
To anyone who knows anything about smartphone design and what goes into the device.Alucard291 - Tuesday, October 16, 2012 - link
No offence but to a consumer that's still 11%. I.e. not even 1/5 reduction.What I'm trying to get at here is that its negligible to most users and touting it as an improvement is only marketing blurb.
Sufo - Tuesday, October 16, 2012 - link
IRL i've noticed the reduction, you'd be surprised how good your hands are at picking up (forgive the pun) on these things. Still, it's not a huge change, admittedly, and it was almost mandatory with the increase in height. Nevertheless once again a nice device to hold.doobydoo - Friday, October 19, 2012 - link
Exactly.If you actually try holding an iPhone 5 you'll immediately notice how obvious it is that it's significantly thinner and lighter.
And as someone else said - it's 18% thinner, not 11.
Kidster3001 - Monday, October 22, 2012 - link
really dooby?From someone who has always said 4" was way to big and 3.5" was perfect? Now you like 4" displays?
Aenean144 - Tuesday, October 16, 2012 - link
Since when does (1 - 7.6/9.3) = 11%?My calculator says the iPhone 5 is 18% thinner than the iPhone 4.
edsib1 - Tuesday, October 16, 2012 - link
Your android benchmarks are meaningless if you dont use a) best browser and b) latest drivers. Phones with later version drivers will have higher scores.HTC One X (Tegra3) - official RUU 4.04 & Chrome
Kraken - 21095
Google V8 - 1578
Octane V1 - 1684
Sunspider - 1172
Browsermark - 130288
HTC One X (Tegra3) - Eternity Kernel (3.4) & Chrome
Kraken - 18750
Google V8 - 1791
Octane V1 - 1922
Sunspider - 1084
Browsermark - 162580